
Inspiration
Personalized learning is usually costly and inaccessible, leading it to be hard to access for learners without the necessary resources. Traditional education often uses a one-size-fits-all approach, making personalized support rare and costly- often too expensive for widespread accessibility. Studies indicate that 77% of learning and development professionals think that personalized learning is vital to growth and engagement, yet resources tailored to individual learning needs are frequently tied to high costs, which limits access for many learners. Personalized learning has been shown to significantly improve learning outcomes: students using customized learning programs have reported better engagement and retention rates, with personalized approaches supporting academic gains, especially in struggling students.
Mind the Gap seeks to bridge this accessibility gap by using innovative technology to deliver a personalized learning experience that’s freely accessible. By combining tailored topic mapping with adaptive resources, automated assessments, and emotion sensing, our platform provides the same benefit of one-on-one support, tutoring, and personalized learning plans in an accessible, self-directed environment. This offers a transformative educational experience by harnessing the wealth of knowledge available online to personally address each and every learner’s unique needs without being financially burdensome.
Even if you were to consider the cost of running the models and APIs, generating a completely custom, unique course for a student from scratch costs on average $0.50, which is a mere fraction of the thousands of dollars that personalized learning usually costs.
What it does
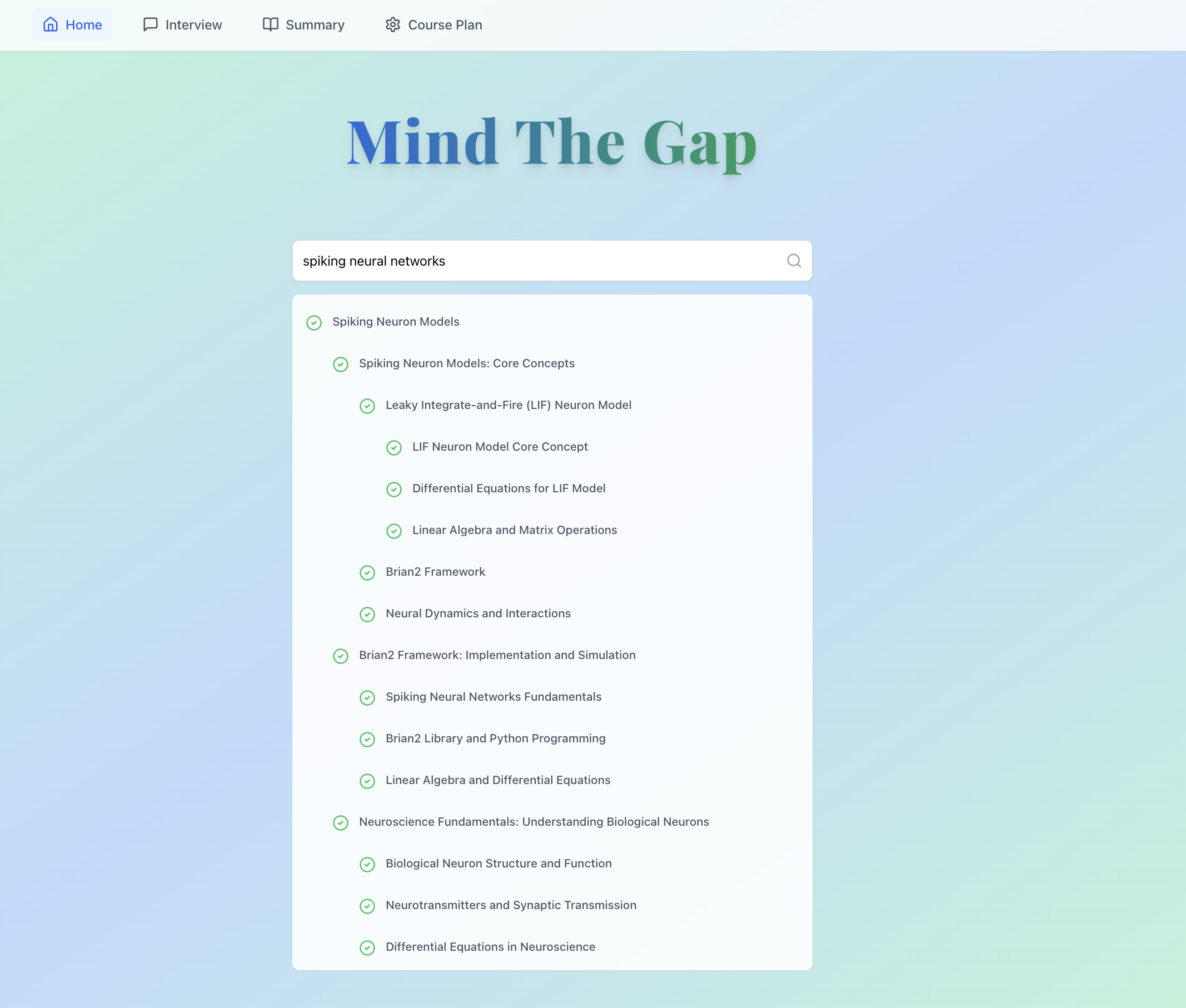
Mind the Gap is an interactive learning platform that assists users in gaining the knowledge needed to develop a project they want to create
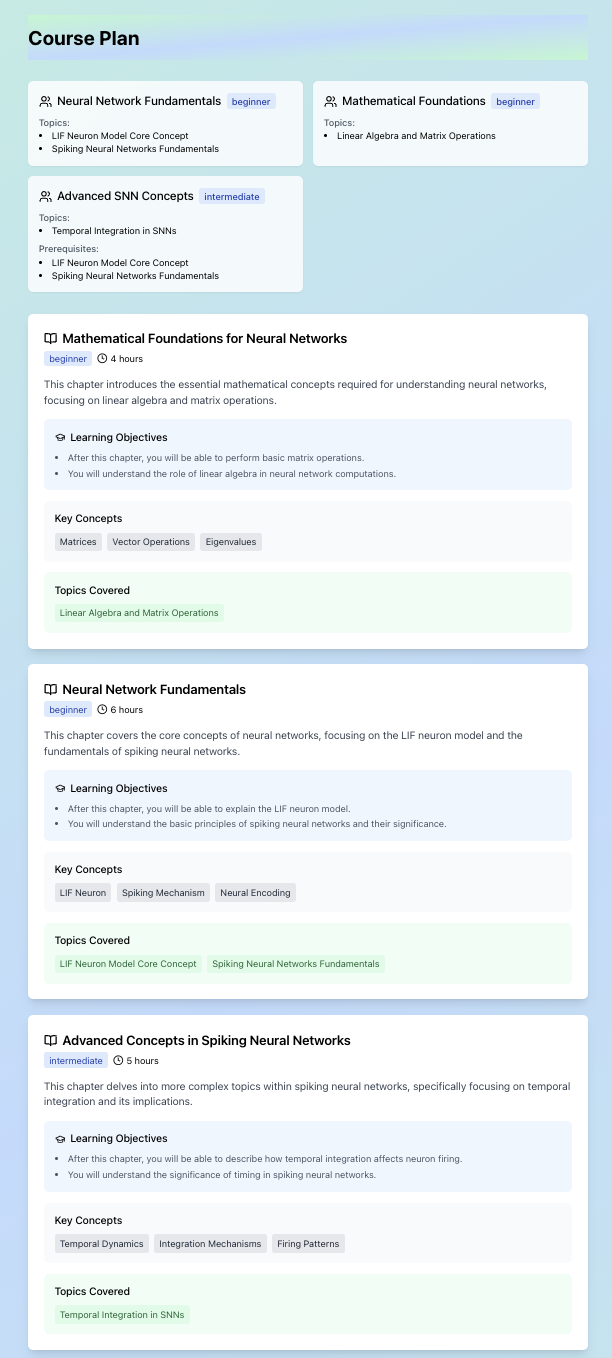
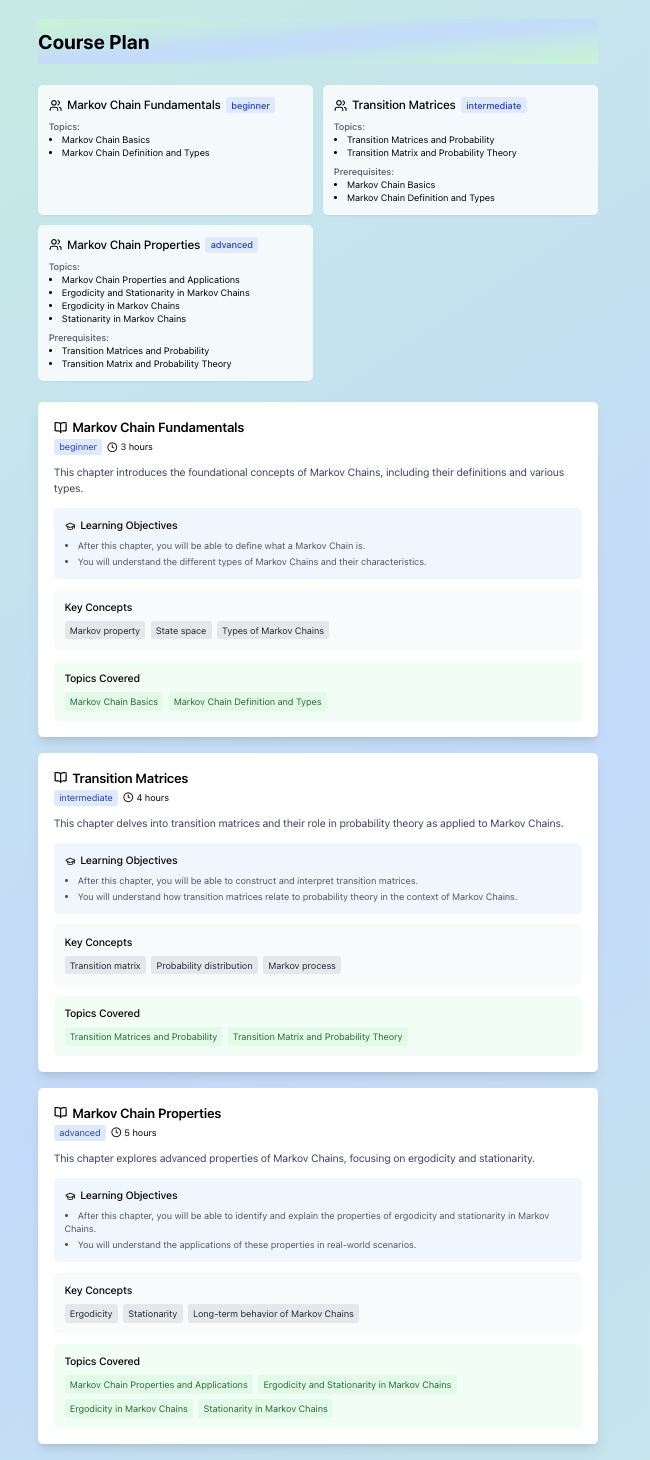
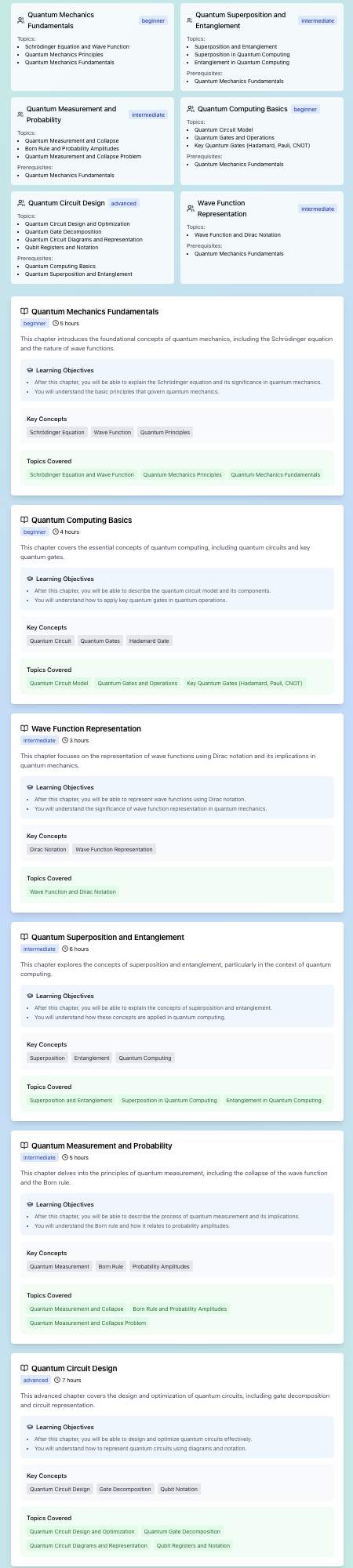
- Users begin by entering the project they want to build or learn about The platform then generates a tailored list of general topics necessary to understand that project. For deeper learning, each topic expands into specific subtopics
- Users can then select topics they’re interested in or don’t fully understand
- A sidebar then allows them to further mark their knowledge level with options to indicate familiarity (check mark), lack of knowledge (X), or a request for an interview (microphone)
- If the user opts for an interview, the platform conducts a brief audio Q&A on the selected topics, analyzing both the user’s responses and tone or emotion to assess confidence and understanding in each area
- Based on this analysis, the platform identifies knowledge gaps and generates a custom list of resources, curated from the web, to help users learn what’s needed to complete their project
- It creates a personalized learning pathway, guiding users through exactly what they need to know to successfully bring their project to life
How we built it
We divided up tasks such as ML search agents, frontend/backend and speech-to-speech interview. In order to parallelize as efficiently as possible, we wrote mock data generators for the frontend/backend to work with as the models were being brought up. Tools we used: Cursor, TavilyAI, OpenAI API, Groq API, HuggingFace API, FastAPI, LangChain, …
Parallel Knowledge Search – We created agents with Llama3.2-8B + search engine tool use that used controllable breadth + depth searches to cover wide and deep knowledge for the user. We threaded each topic’s subtopic searches.
Interviewer – With the Hume Empathic Voice Interface, we were able to interview the user on topics they were unsure of to gauge their understanding. We read the voice’s emotion to get another indicator of their confidence. This was finally aggregated into a list of topics and their associated confidence levels.
Course Generation – We created a multi-agent system with LangGraph. It took the user’s list of topics + confidence on each topic as input. An analyst agent grouped topics and decided the difficulty of each one. Then a planner agent turned this into chapters, key concepts and descriptions. This was passed to a research orchestrator agent that contracted smaller researcher agents (gpt_researcher open source library) to find information on subtopics and report back. This was all finally passed into an organizer agent to clean up all the data into a readable format. Each agent used OpenAI language models such as gpt-4o-mini. Researcher agents utilized the Tavily search API.
Challenges we ran into
With the nature of parallel calls, we ran into LLM inference rate limits and search API rate limits very often. Integrating an audio-based IO into the webapp proved challenging with the frontend/backend layers. Guiding the search agents to stay on topic and also go in depth was a lot of prompt engineering and traditional algorithmic guidance.
Accomplishments that we're proud of
Learning how to create agentic systems that can work in parallel to do work for the user cheaply, efficiently and accurately
What we learned
- How to finetune adapters for billion parameter-scale LLMs
- How to serve LLMs from multiple providers
- How to using a multi-modal models from Hume
- How to implement user confidence detection logic
- How to execute for 36 hours
What's next
- Fine tuning all models for more steerable outcomes
- Switch inference to cerebras once we get access for higher rate limits and tokens per second
- More compute for more parallel capability.
Team members
Mihika Tiwari, Ashray Gupta, Maxwell Zhang



Log in or sign up for Devpost to join the conversation.