
Mimic
Mimic is browser automation you build by showing it, not coding it. Do a task once, and Mimic does it forever, for pennies.
Today's AI browser agents are capable, but they start every run from scratch. Ask one to repeat a task and it re-reads the page and re-reasons each step as if it had never seen the job before, paying an LLM to think it through again on every run. Do the job a thousand times and you pay to figure it out a thousand times. Mimic watches you do it once, learns the workflow, and then replays it deterministically, with zero LLM calls. The only time it stops to think again is when the website actually changes underneath it, so the cost stays flat whether you run it once or a million times.
We proved it by racing Mimic against a state-of-the-art agent on the same outreach job. The other agent spent \$1.55. Mimic spent \$0.06, about 25x cheaper, and faster too.
We are upfront about the limit, though: sending a thousand messages still means a thousand clicks, so the total time still grows with the work. We cannot beat physics. What collapses is the thinking cost, not the doing. And when a page changes and a step breaks, Mimic does not fall over. It works out what the missing element was meant to do, finds it again, fixes itself, and remembers the fix so it never breaks there twice.
Inspiration
We are Berkeley students, and like most students, we lose hours of every week to tedious web busywork: cold emails, LinkedIn outreach, pasting the same details into form after form to chase internships, recruiters, and the occasional reply. It is repetitive, it is nearly identical every time, and it is exactly the kind of work a computer should be doing for us.
So why isn't it? Because every existing fix is flawed in its own way:
- Traditional automation (UiPath, Zapier) needs a developer and weeks of setup, then breaks the moment a button moves.
- The new AI browser agents will do the task, but they improvise it from scratch on every run. That makes them both unreliable and surprisingly expensive: you are paying an LLM to relearn the same job over and over.
Nobody builds the obvious thing: working out a repetitive task should be a one-time cost, not a tax you pay on every run. Learn it once by watching a human, then run it forever for almost nothing, with no code and no config, and it should not collapse the first time a site redesigns a page. We wanted to put that in the hands of people who have neither a budget nor a CS degree, starting with ourselves.
To test it safely, without spamming real people or risking banned accounts, we rebuilt the task we actually dread as a sandbox: LinkedUp, a stand-in for LinkedIn we could automate freely.
What it does
The idea in one line: you do a task once, and Mimic learns to do it for you.
Concretely, you show it the job inside Mimic's browser: read a lead from a spreadsheet, open the messaging site, type a personalized note, hit send. Mimic records every move. Then Anthropic's Claude (Opus 4.8) reads that recording and turns it into a clean, reusable workflow, working out which parts are the variables that change every time (the person's name, their role) and which are the fixed steps that never do (click Send). Press run, and it works through a whole spreadsheet of new people on its own.
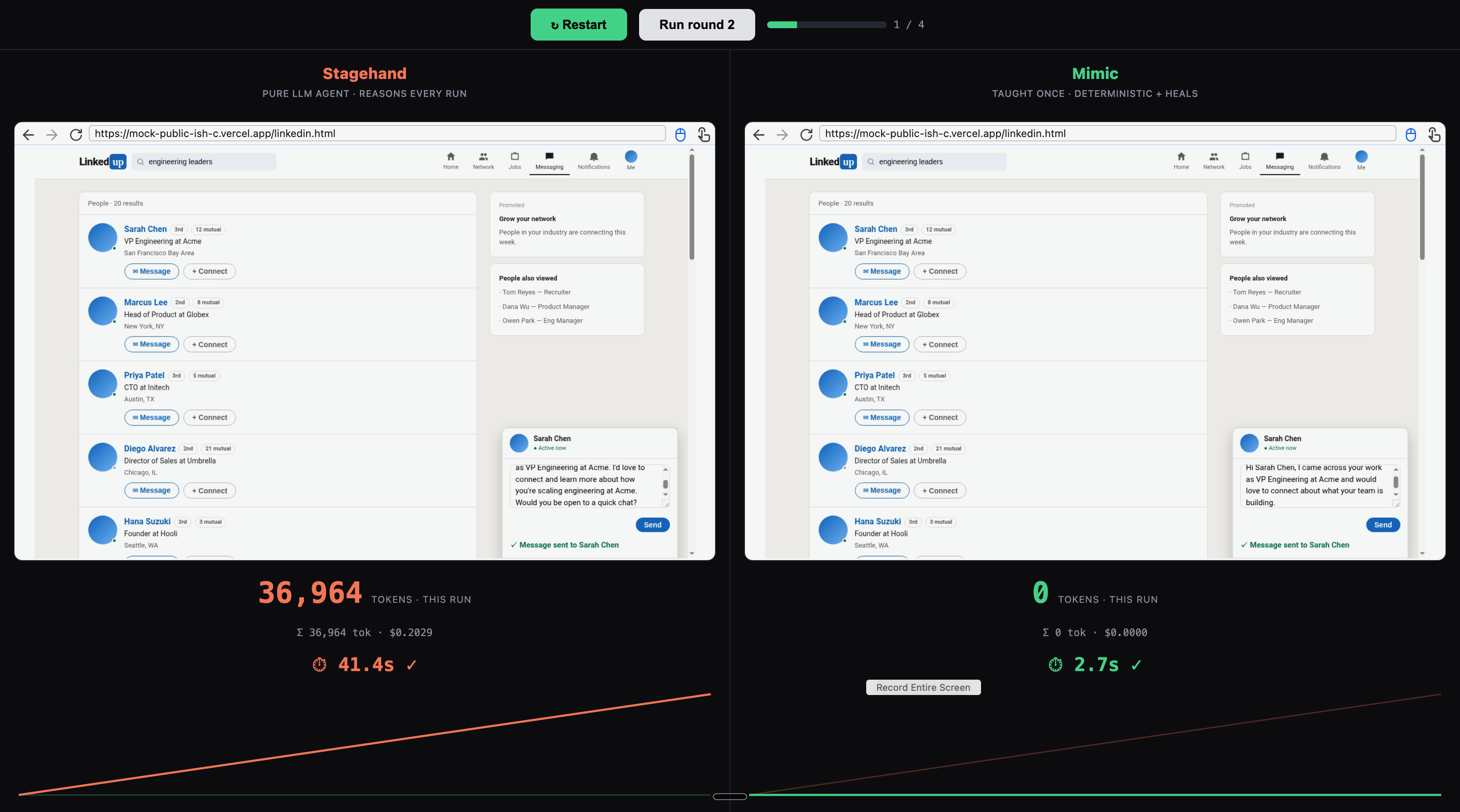
The Cost Race is the demo. A claim like "it's cheaper" means nothing without proof, so we made the savings impossible to miss. We put Mimic head to head with Stagehand (a top-tier AI agent from Browserbase) on the identical job: go down a list of leads, message each one on LinkedUp, come back, repeat. A live meter between them counts real tokens and real dollars, pulled from each side's actual API usage, nothing estimated and nothing faked.
- Stagehand re-reads and re-reasons every step for every lead, and its meter climbs the entire time.
- Mimic replays what it already learned: zero LLM calls, zero tokens on a clean run.
Same three-lead job: \$1.55 versus \$0.06 (about 25x cheaper), and 132 seconds versus 32.
Then we break it, live. Mid-race, we rename the Send button to Send to, the kind of small change that breaks normal automation. A brittle script would fail immediately. Stagehand handles it, but only because it is already re-reading the entire page on every step, which is exactly why it is so expensive. Mimic hits the broken button and, for the first and only time in the run, stops to think: Anthropic's Claude looks at the page, asks which element is the button that sends this message, finds it by meaning instead of the old broken selector, patches the step, finishes the lead, and writes the fix back so it never breaks there again. Cheap because it is deterministic, trustworthy because it heals, and you watch all of it happen live, on one screen.
Design and UX
A demo can be technically strong and still fail to land if nobody can see what makes it strong. The parts that matter most, the cost gap, the deterministic replay, the self-healing, all happen invisibly, in milliseconds, inside a backend. So we treated the interface as the argument, not a footnote to it.
- It all fits on one screen. Two agents run side by side, each driving a real cloud browser you can watch, with a live cost-and-token meter and a per-lane timer between them. You do not read a claim about savings, you watch one counter race ahead while the other barely moves.
- There is no code anywhere. Teaching Mimic is just using a browser. Someone who has never written a line of code records a workflow by doing the task once: no scripts, no selector editors, no settings to configure.
- The heal is the centerpiece. The moment we break the page, the UI tells the story in real time: the failure, Mimic working out the fix, and the step running again. A recovery that would normally be a buried error log becomes the high point of the demo.
None of it is pre-recorded. Every number on screen is streamed live, step by step, over WebSockets, straight from the real run.
How we built it
Under the hood it is a simple loop, record, structure, replay, heal, with a memory layer holding it together.
- Record. Playwright captures every click, keystroke, and page change, and snapshots the context around each one (the DOM, the element's attributes, what it semantically is), even across multiple browser tabs.
- Structure. Anthropic's Claude (Opus 4.8, with structured JSON output) reads that raw recording and turns it into a clean, parameterized workflow, separating the variables from the fixed actions.
- Store. The workflow and its full version history live in Redis as genuine agent memory: not a cache, but a permanent, auditable record the healer reads from and writes back to.
- Replay. The runtime runs the saved workflow against new data, unattended, streaming every step to the UI over WebSockets, inside a real cloud browser (Browserbase).
- Heal. When a step fails, Anthropic's Claude re-grounds the element from its stored intent, patches it, retries, and saves the upgraded workflow back to Redis as a new version. Sentry captures the full failure-and-recovery moment, because failure is our product, so we instrument it closely.
Why the cost collapses. A normal agent re-reasons every step on every run, so its token cost grows in step with how many times you run it: a thousand runs, a thousand bills. Mimic pays the thinking cost once, up front, to learn the task, then replays it with no LLM involved at all. The only time it spends a token again is when the website itself changes and a step needs healing, and that depends on how often the site changes, not on how many times you run. So the cost stays roughly flat no matter the volume, and the cost per run trends toward zero.
The honest caveat, which we care about: a thousand tasks is still a thousand rounds of clicking and typing, so the total time still grows with the work. We cannot beat physics. What flattens is the thinking, not the doing. In short, a normal agent re-interprets the task from scratch every run, while Mimic compiles it once and runs the result.
We split the build across one clean contract: the Brain (Anthropic's Claude handling intent-extraction, structuring, and healing, pure logic that owns the Redis schema) and the Hands and Face (the browser engine, record and replay, the Cost Race, and the live heal visualization). A single shared types file was the only seam the three of us had to agree on, which is the main reason we did not trip over each other.
Challenges we ran into
- The healer is not allowed to guess. A confident wrong heal is worse than no heal at all: it clicks the wrong button and submits bad data. So we hardened the prompt and wrote a dedicated anti-hallucination test: when nothing on the page matches what the step is trying to do, the healer must return "could not heal" rather than invent a plausible-looking selector. It passes.
- The meter had to be honest. A made-up cost number would have undermined the whole pitch. So we estimate nothing: we read each side's actual token usage (Mimic's heal tokens from Anthropic's reported usage, Stagehand's from its SDK's per-step totals) and price both at list rate. The \$0.06 really is near-zero, and the \$1.55 really is what the agent spent.
- The demo could only work once. In our first version, the healing lane wrote its fix back to shared memory, so on the next run the control lane read the already-healed workflow and survived too, erasing the contrast. The fix: both lanes always start from the pristine original. The heal still accrues in the memory trail, but the race stays repeatable.
- We had to keep our own selector broken on purpose. The structuring step kept "helpfully" upgrading our deliberately brittle selector into a robust one, which meant our staged break would not break anything, and nothing would heal. We had to force structuring to preserve the recorded selector exactly as-is. The healer is the only part of the system allowed to improve it.
Accomplishments that we're proud of
- The whole loop is real, end to end. A real recorded trace goes to Anthropic, into Redis, hits a real break, gets a real heal, and the fix is written back, all verified against the live Anthropic API and a live cloud Redis, running in a real cloud browser via Browserbase. Nothing is stubbed.
- The cost claim is measured, not asserted. \$1.55 versus \$0.06 on an identical job, taken from both sides' real API usage.
- We made an invisible system legible. A live side-by-side cost-and-token meter, two real cloud browsers running in parallel, and a real-time heal visualization, every value streamed step by step over WebSockets rather than pre-baked.
- The healer is accurate and cautious. It re-grounds a renamed or moved control by intent with high confidence, and it correctly refuses when there is nothing valid to click.
- Four sponsor technologies are load-bearing, not bolted on. Anthropic (Claude Opus 4.8) is the brain, Redis is the agent memory, Browserbase runs the live cloud browsers for both lanes (and makes Stagehand, the agent we benchmark against), and Sentry catches the exact failure that triggers a heal.
What we learned
- Self-healing is only as trustworthy as its willingness to fail loudly. The "refuse to guess" behavior mattered more than the healing itself; a heal you cannot trust is a liability, not a feature.
- The win is on cost, not runtime, and that distinction is the whole pitch. Caching the reasoning stops your per-run token cost from growing with the number of runs; it does not make the actual clicking and typing any less work. Knowing exactly which axis you are improving keeps the claim honest.
- For a systems demo, the UI is the argument. The cost gap and the self-heal are real in the backend, but they only land because a judge can watch them happen live, on one screen, in real browsers.
- "Agent memory" should mean an auditable, versioned trail of what changed and why, not a glorified key-value cache. Redis modeled that cleanly.
What's next for Mimic
- More kinds of healing: not just renamed or moved buttons, but reordered flows, multi-page tasks, and login walls.
- Scheduling, so a workflow can run on its own, unattended.
- A savings dashboard showing the cumulative dollars each workflow has saved versus a reasoning agent.
- A shared library where non-coders can publish and fork each other's workflows.
- Confidence thresholds, so when the healer is unsure, it hands off to a human instead of guessing.
Built With
- anthropic
- browserbase
- claude-opus-4-8
- express.js
- html
- node.js
- playwright
- react
- redis
- sentry
- stagehand
- typescript
- vercel
- websockets











Log in or sign up for Devpost to join the conversation.