


Inspiration
We forget 70% of what we learn within 24 hours. Notes apps don't solve this , they're static files that sit untouched. We wanted something different: a personal AI that doesn't just store knowledge, but understands it.
An AI that connects ideas across everything you've ever read, written, or discussed ,and retrieves it through natural conversation.
Milo was born from the frustration of knowing you've learned something before but being unable to find it when you need it most.
What it does
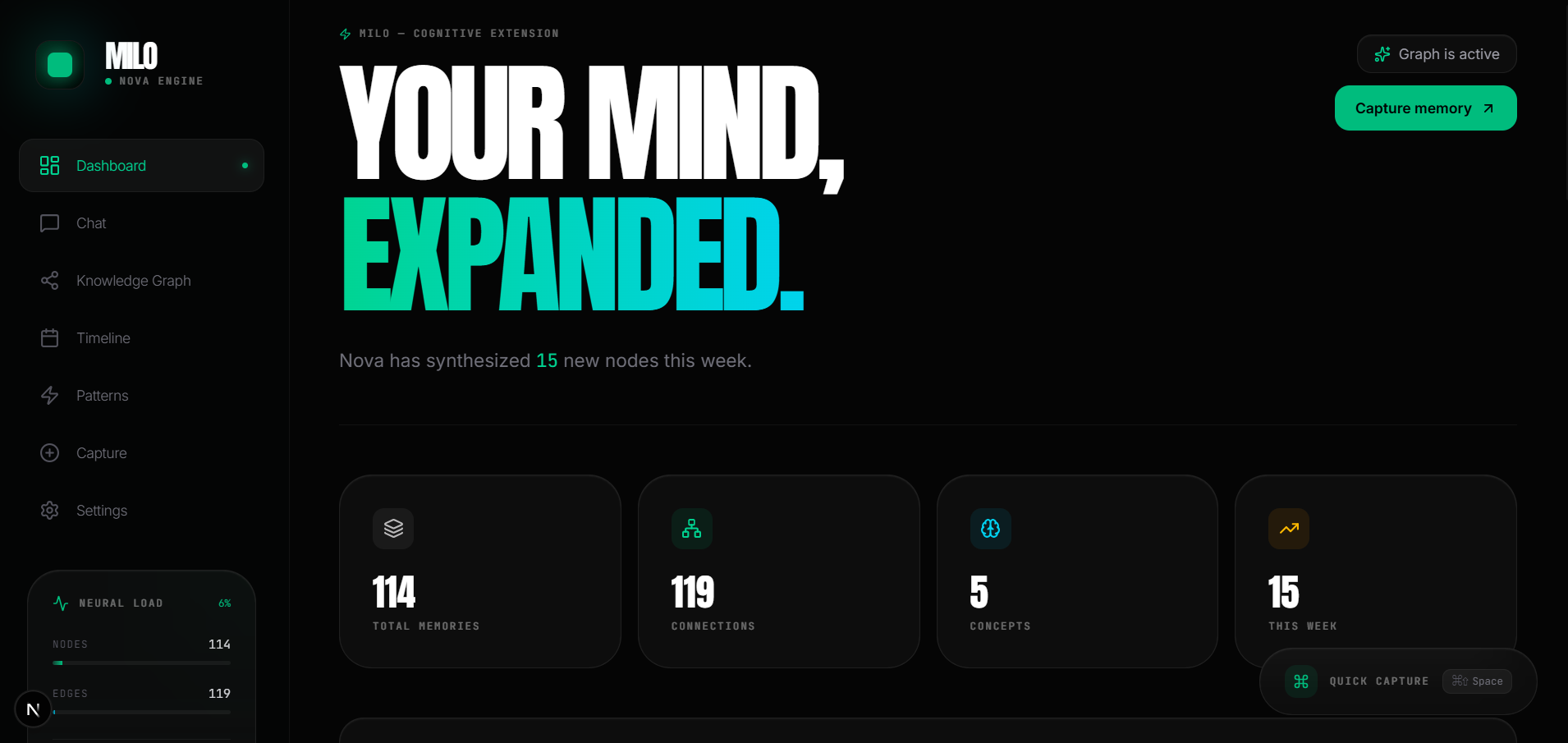
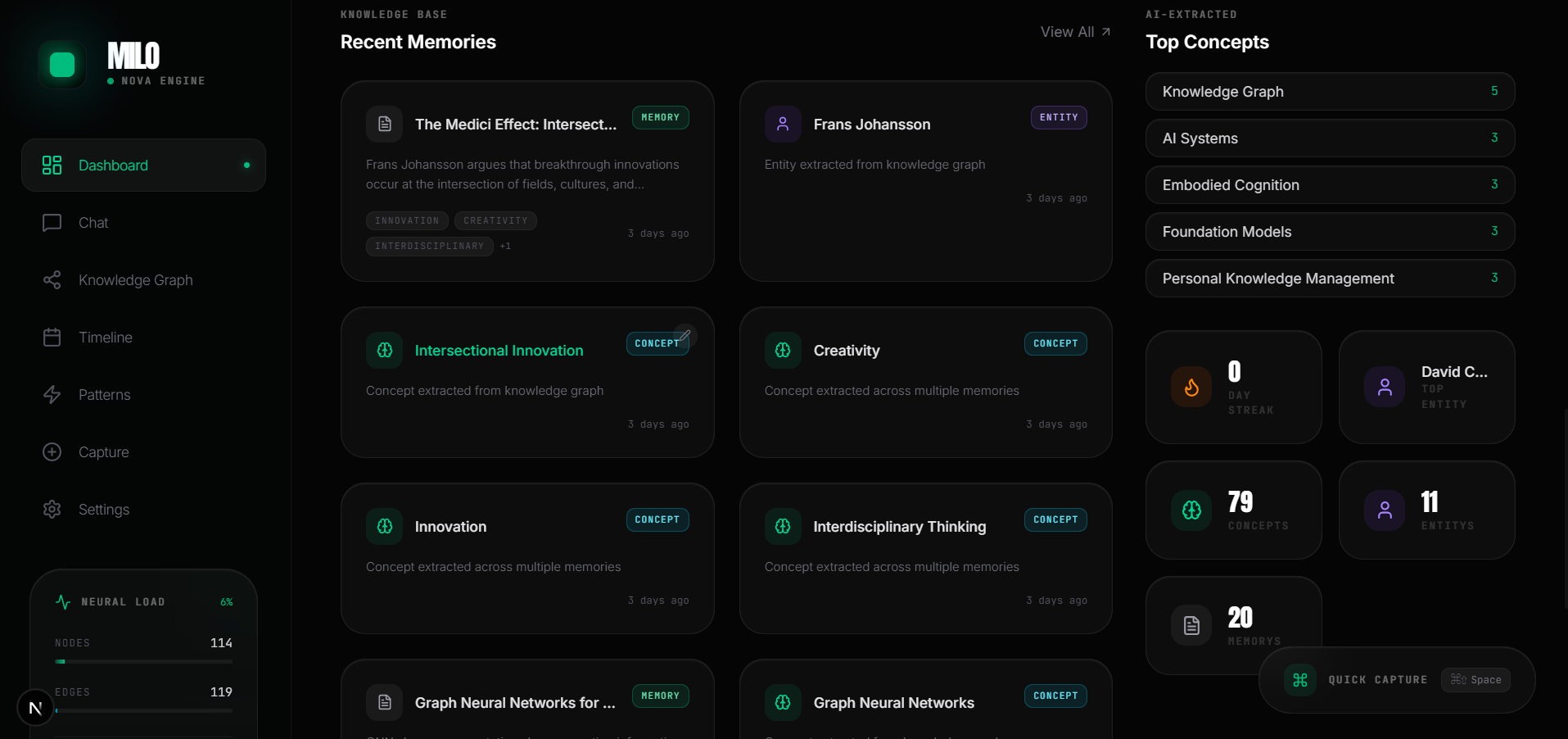
Milo is a personal AI memory system powered by Amazon Nova. It captures knowledge from multiple sources , typed notes, PDFs, documents, web articles, voice memos, and meeting transcripts , then structures everything into a living knowledge graph.
Key capabilities
Capture
Ingest knowledge from text, PDF, DOCX, URLs, voice, and meeting transcripts with a single action.
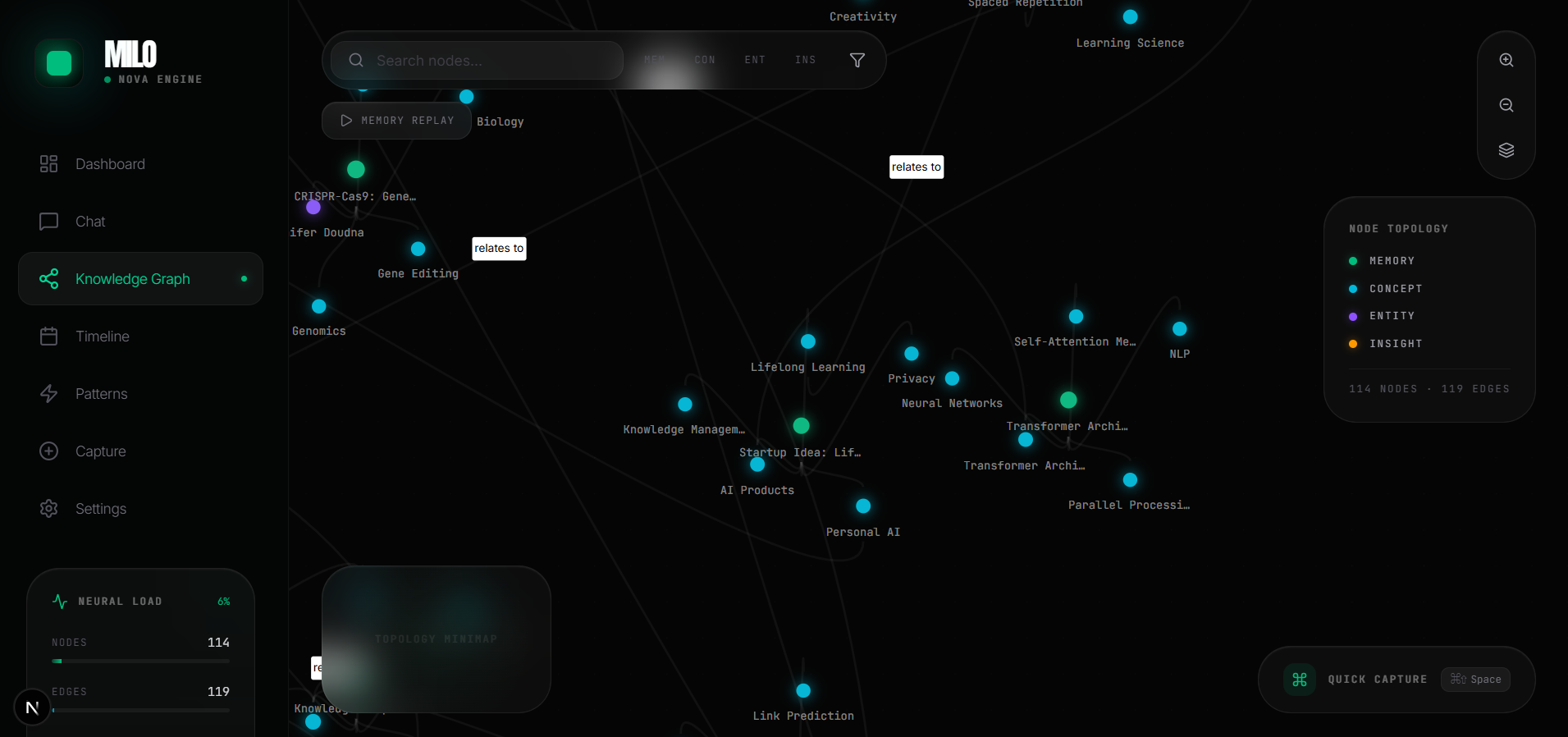
Knowledge Graph
Automatically extracts entities, concepts, and relationships, building an interactive visual graph of your entire intellectual landscape.
Conversational Retrieval
Ask questions in natural language and get grounded answers with citations to your own knowledge.
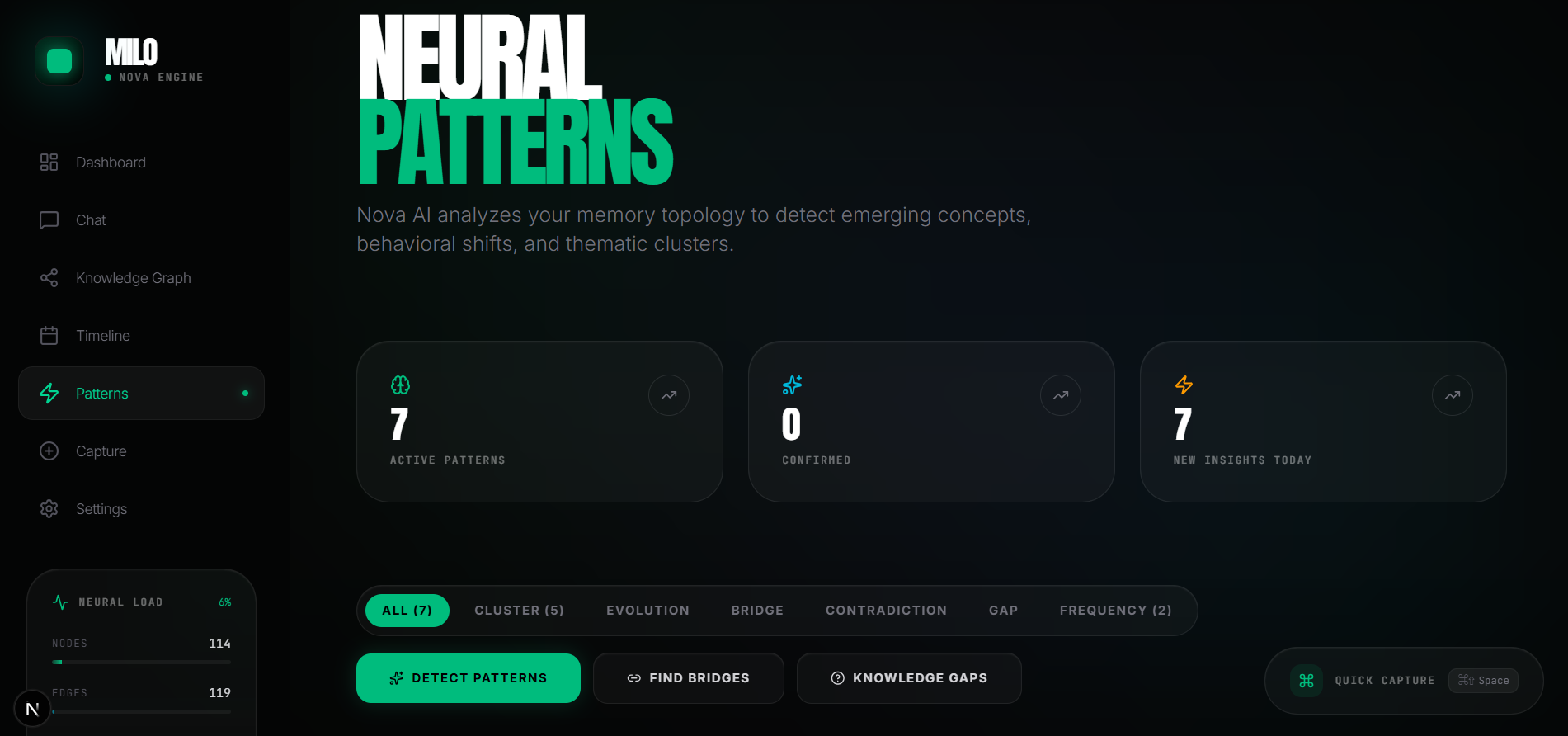
Pattern Detection
AI identifies clusters, contradictions, knowledge gaps, and evolving ideas across your memories.
Timeline View
See how your knowledge and thinking evolved over time.
Encryption
AES-256-GCM encryption on all stored content with passphrase-protected access.
Browser Extension
Capture web content and highlights directly from any page.
How we built it
Milo runs on three Amazon Nova models, each chosen for a specific role:
Amazon Nova 2 Lite
Fast operations: entity extraction, tagging, summarization, and classification during the ingestion pipeline.
Amazon Nova Pro
Deep reasoning: RAG-powered answers, pattern detection, relationship scoring, and graph traversal queries.
Amazon Nova Multimodal Embeddings
1024-dimensional vector embeddings for semantic search across all captured knowledge.
The ingestion pipeline processes every piece of content through:
extraction → chunking (512 tokens, 64-token overlap) → Nova embedding → entity/relationship extraction via Nova Lite → graph update in SQLite → vector storage in LanceDB
Retrieval uses a hybrid approach:
- Semantic search (Nova embeddings + LanceDB)
- Keyword search (SQLite FTS5)
- Graph traversal (2-hop neighborhood expansion)
These are fused via Reciprocal Rank Fusion, then Nova Pro generates a grounded answer with node citations.
Stack
- Next.js 16 (App Router, TypeScript)
- SQLite via Drizzle ORM
- LanceDB for vector storage
- AWS Bedrock for all AI calls
- React Flow for graph visualization
- Framer Motion for UI
- Chrome Extension (Manifest V3) for web capture
Challenges we ran into
Nova Multimodal Embeddings API differences
Nova Multimodal Embeddings uses a different request/response format from other Bedrock models. Debugging the correct payload structure (taskType: "SINGLE_EMBEDDING" with singleEmbeddingParams) and response parsing (body.embeddings[0].embedding) required careful iteration.
Knowledge graph extraction
Building a knowledge graph from unstructured text is fundamentally hard. Getting Nova to extract meaningful entities and relationships consistently , and merging them without creating duplicate nodes , required extensive prompt engineering and deduplication logic.
Deploying file-based databases
Deploying on EC2 with a Next.js app using both SQLite and LanceDB (both file-based) meant we needed persistent storage and enough memory for production builds. We solved this with instance sizing and swap space.
Hybrid retrieval balancing
Making hybrid retrieval work well , balancing semantic search, keyword search, and graph traversal so the right context surfaces for any question, not just keyword matches.
Accomplishments that we're proud of
- A fully functional knowledge graph that automatically builds itself from any content you give it , no manual linking or tagging required.
- Three Nova models working in concert, each handling what it does best: fast extraction, deep reasoning, and semantic understanding.
- Conversational retrieval that actually works , ask “What did I learn about X?” and get a grounded answer citing specific memories.
- Pattern detection that surfaces connections you didn’t notice: cross-domain concepts, evolving ideas, and contradictions in your thinking.
- End-to-end encryption by default , your knowledge graph is yours alone.
- A polished UI with interactive graph visualization that makes exploring your knowledge enjoyable.
What we learned
Amazon Nova’s model lineup works extremely well for multi-tier AI architectures.
Using a fast model for extraction and a reasoning model for complex queries is both more efficient and more cost-effective.Knowledge graphs and vector search complement each other.
Vectors find semantically similar content; graphs find structurally related content. The combination retrieves context neither approach finds alone.The hardest part of personal AI isn’t the AI , it’s the data pipeline.
Cleaning and structuring messy real-world data (PDFs, web pages, voice transcripts) takes the majority of engineering effort.
What's next for Milo
Proactive insights
Milo surfaces relevant memories while you're reading or writing ,before you ask.
Multi-user support
Shared knowledge spaces for teams and study groups.
Mobile app
Capture ideas on the go with voice-first interaction.
IPFS-based sync
Decentralized, encrypted cross-device sync where users control their own data.
Advanced graph algorithms
- PageRank to identify your most central ideas
- Community detection to map knowledge domains
- Temporal analysis to track intellectual growth
Built With
- amazon-nova-2-lite
- amazon-nova-multimodal-embedding-sqlite
- amazon-nova-pro
- api
- chrome
- drizzle-orm
- extension
- framer-motion-amazon-bedrock
- lancedb
- next.js-16
- react-19
- react-flow-aws-transcribe
- speech
- tailwind-css
- typescript
- web


Log in or sign up for Devpost to join the conversation.