-
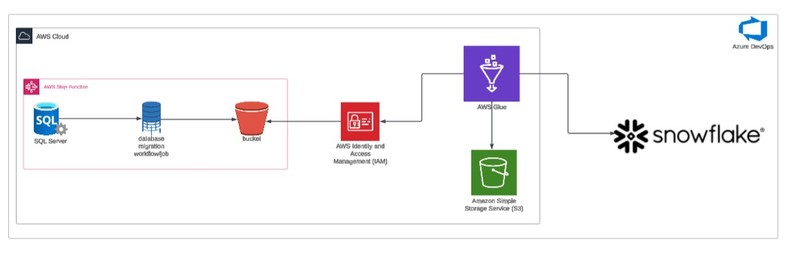
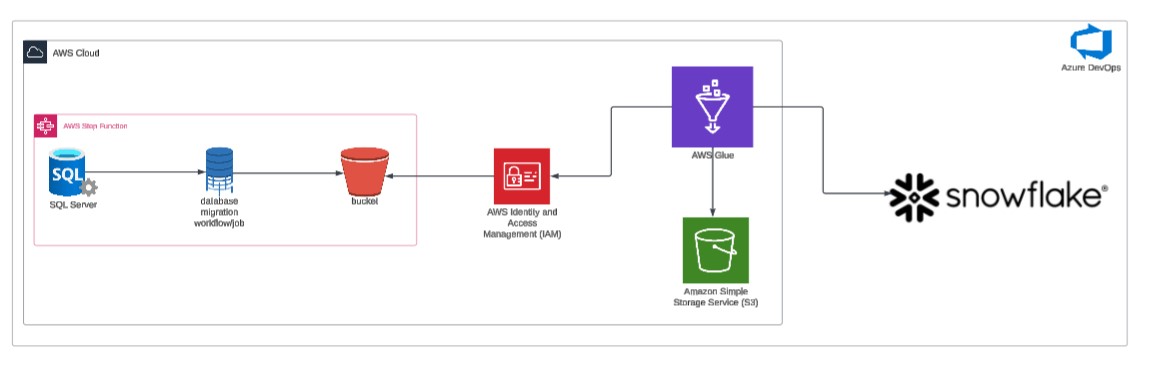
High level flow
-
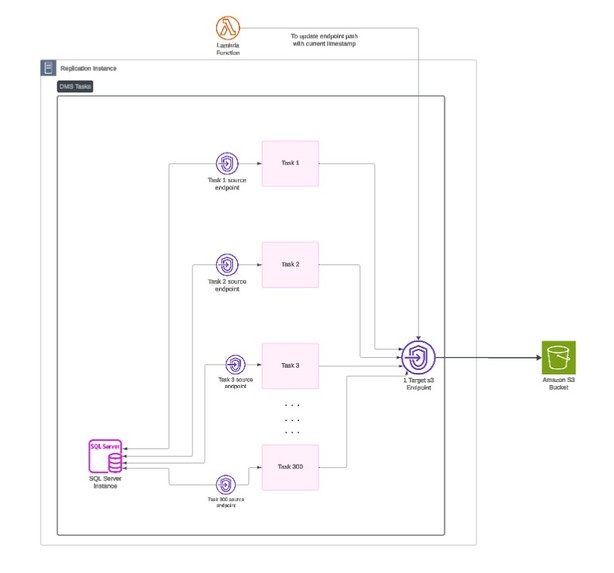
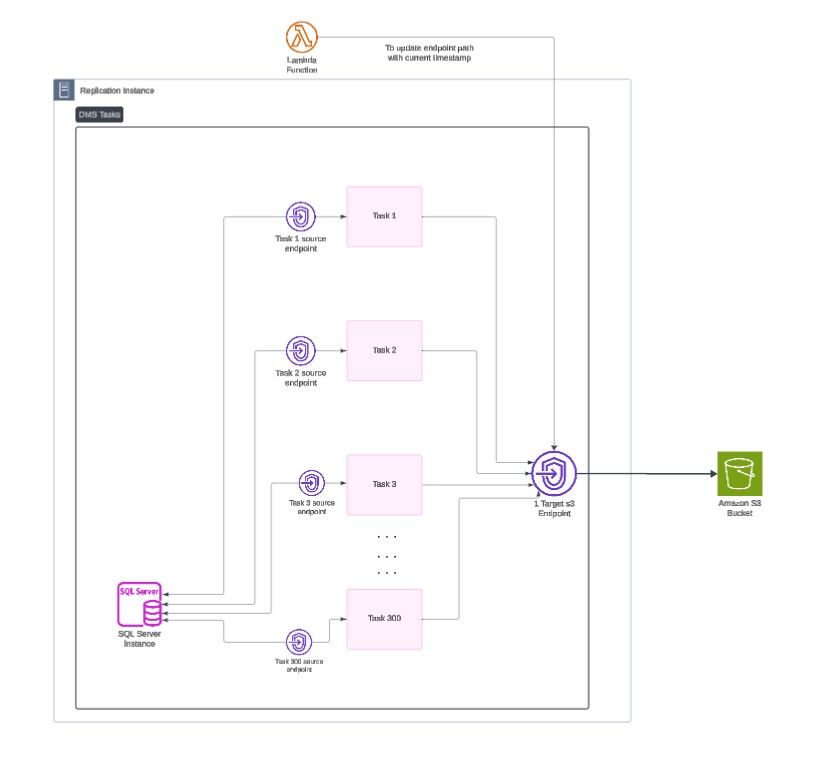
Instance level arch
Inspiration
Modernization of Data Warehouses and leveraging AWS serverless services like AWS DMS, Lambda, Step Functions, and more.
What It Does
Migrates data from a legacy SQL Server to Amazon S3 using AWS Database Migration Service (DMS), orchestrated via AWS Step Functions. The entire stack is built using AWS CDKTF (Cloud Development Kit for Terraform). The code is designed to handle both full load and delta load scenarios. Data from S3 is then moved to a cloud database like Snowflake using an IAM trust relationship.
How We Built It
We created pipelines to replicate data from SQL Server to S3, ensuring the file output is in .parquet format for easy adoption by Snowflake. Once the pipeline was established, we orchestrated the entire process using AWS Step Functions.
We leveraged AWS Lambda to dynamically modify DMS endpoints during pipeline execution, which enabled storing output files in specific S3 directories per source database. This helped us maintain proper data organization, especially when handling multiple source databases and tables.
The DMS tasks were configured to replicate both tables and views by using the parameter table-type. It's important to note that AWS DMS only supports views during a full-load operation.
DMS performance tuning was also a key part of our build process. We optimized task settings by:
- Increasing batch sizes for data extraction
- Enabling multi-threaded replication for large tables
- Partitioning at the table level to reduce processing time for large datasets
These adjustments significantly improved task throughput and reduced end-to-end latency.
Challenges We Ran Into
We needed to replicate approximately 250 databases, with each database containing around 40 tables—totaling close to 12,000 tables replicated daily using the DMS process.
Our approach involved creating one DMS task per database, encompassing all associated tables. This required careful configuration of DMS to manage large-scale operations within task limits and optimize for performance.
DMS also required specific SQL commands to be executed on the source SQL Server instance after the DMS user (PID) was created. These pre-requisites posed a challenge during initial setup.
Additionally, dynamically modifying DMS endpoints at runtime introduced potential risks such as misconfigured paths, which could lead to data being written to incorrect S3 directories. To mitigate this, we implemented robust error handling and validation within our Lambda functions.
Accomplishments That We're Proud Of
- Seamlessly replicating over 12,000 tables across hundreds of databases
- Dynamically managing DMS endpoints per database using AWS Lambda
- Ability to onboard a new database with a single click by updating a flag in Azure library variables
- Enabling both full-load and delta-load options without redeploying infrastructure
What We Learned
- AWS DMS offers great flexibility to switch between full load and delta load configurations
- A single DMS instance can support up to 200 tasks, which is critical for scaling
- DMS internally manages table-level parallelism, optimizing replication at the table level based on instance capacity
- View replication is only supported in full-load tasks
- Performance gains are best achieved by tuning task settings (batch size, threading) and partitioning large tables for parallel processing
What's Next for Migration Using AWS Serverless Solutions
- Enable delta load functionality for near real-time updates
- Implement intelligent task scheduling to avoid resource bottlenecks
- Expand monitoring with CloudWatch dashboards and alerting for failed tasks
- Explore AWS Glue for post-processing data pipelines and advanced transformations
- Continue improving DMS performance beyond instance scaling, using task-level tuning and better partitioning strategies
Built With
- amazon-web-services
- cdktf
- dms
- lambda


Log in or sign up for Devpost to join the conversation.