-
-

-
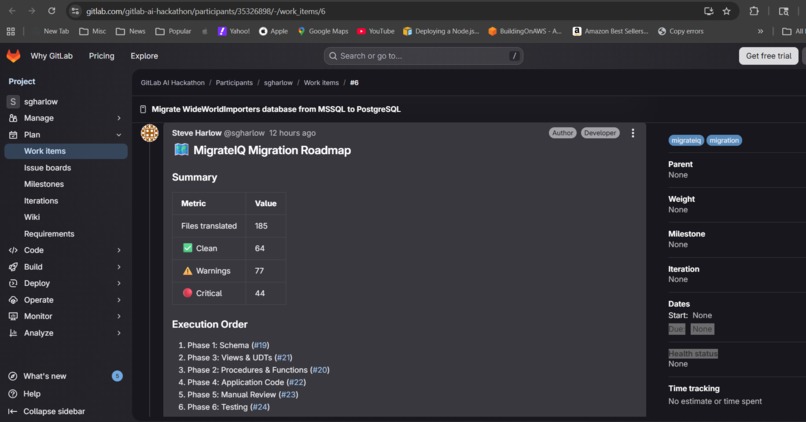
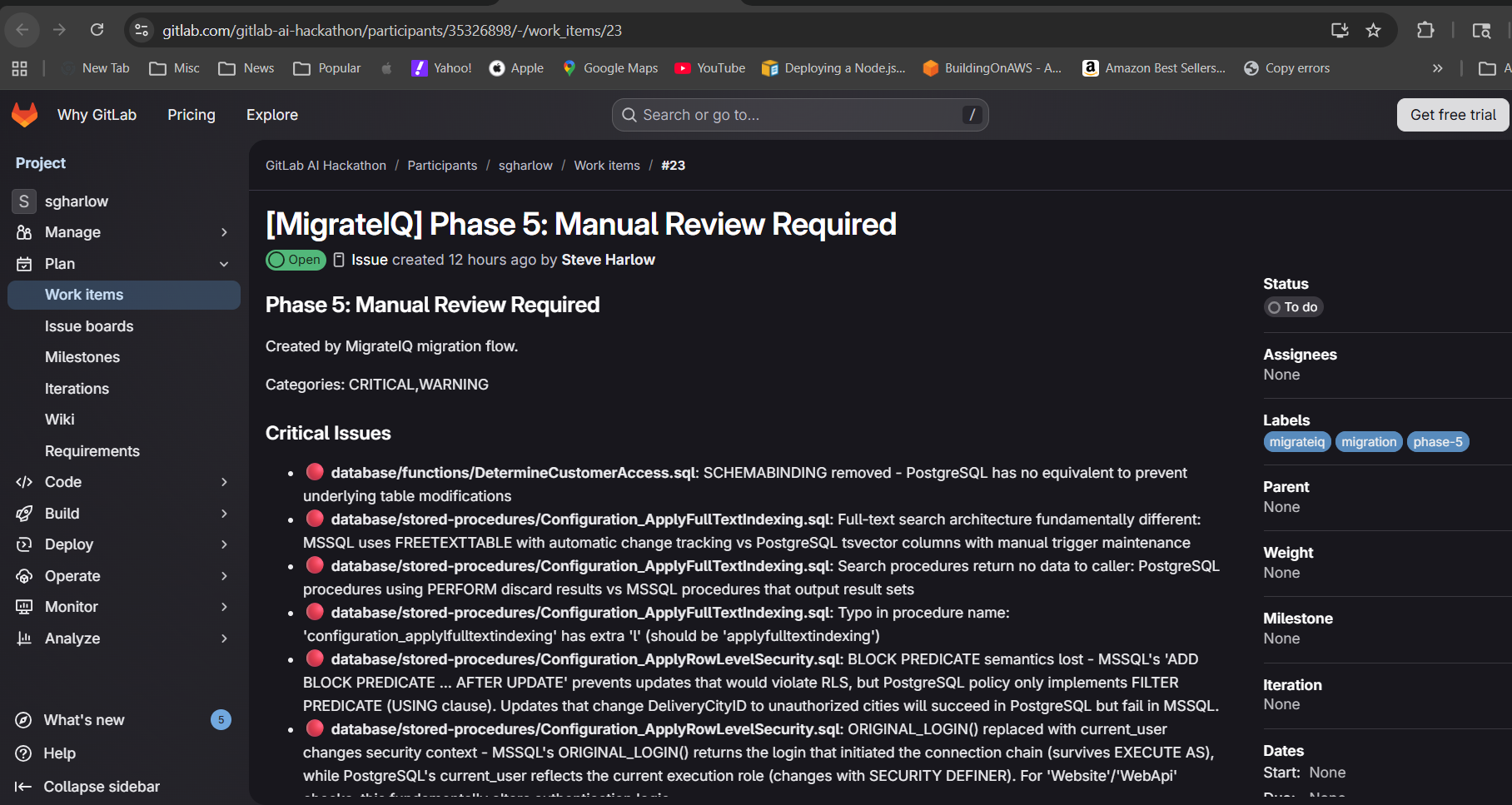
Six phase issues created. Phase 5 lists every item needing human review.
-
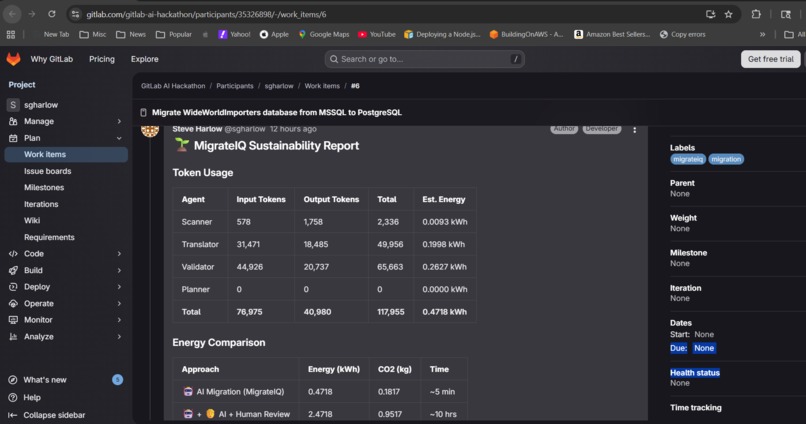
Complete roadmap with effort estimates. Plus sustainability tracking — 91% energy reduction vs manual.
-
Here's the translated code.
-
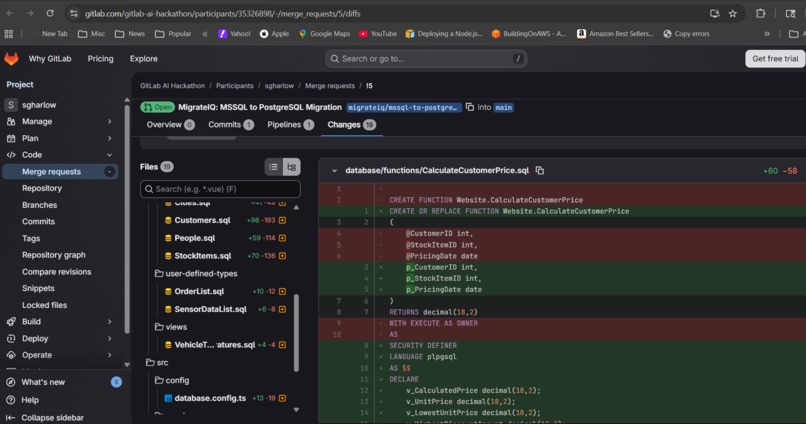
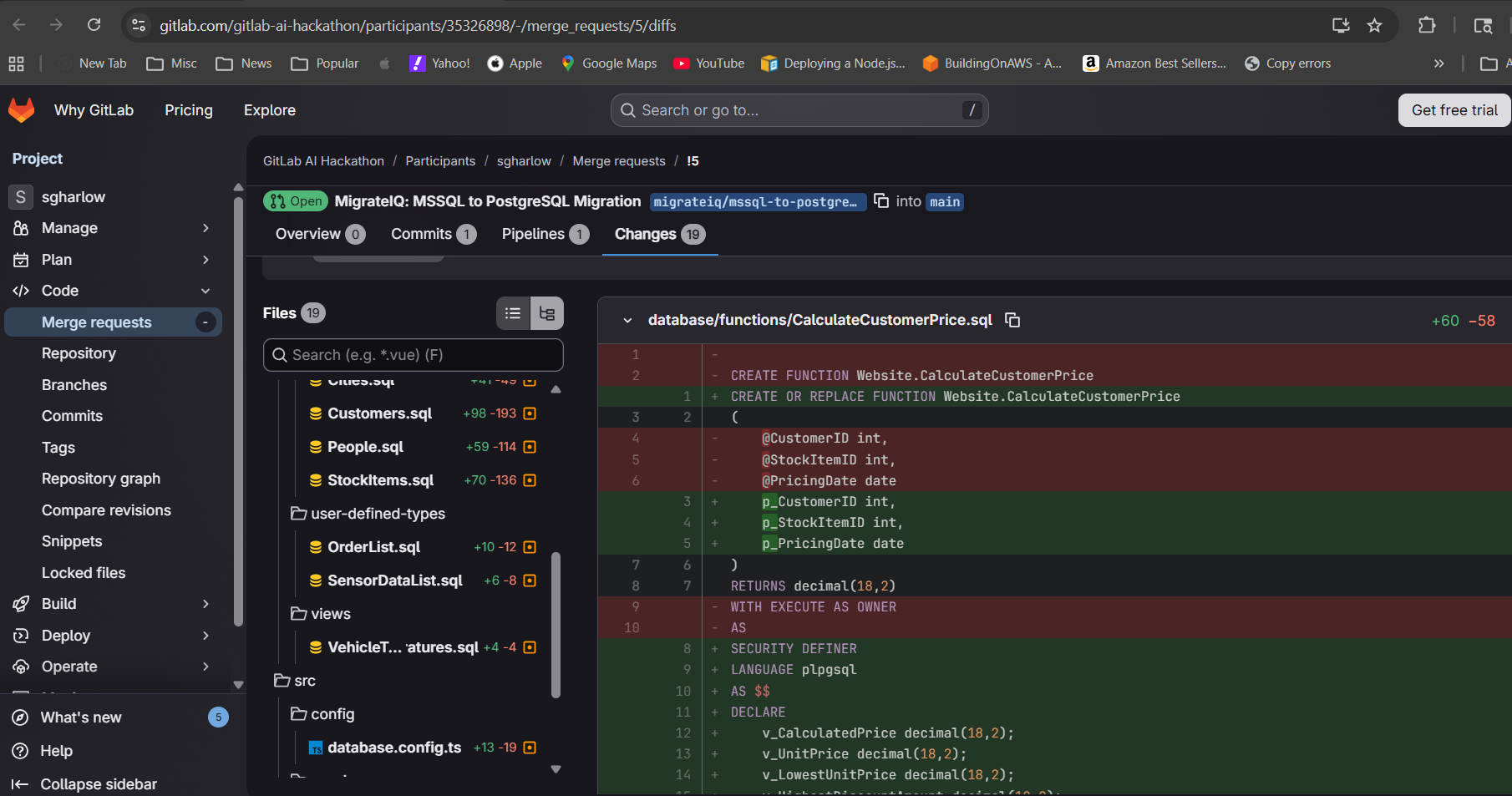
Here's the translated code. Native compilation removed. ATOMIC block converted to PL/pgSQL, memory-optimized TVP to composite type.
-
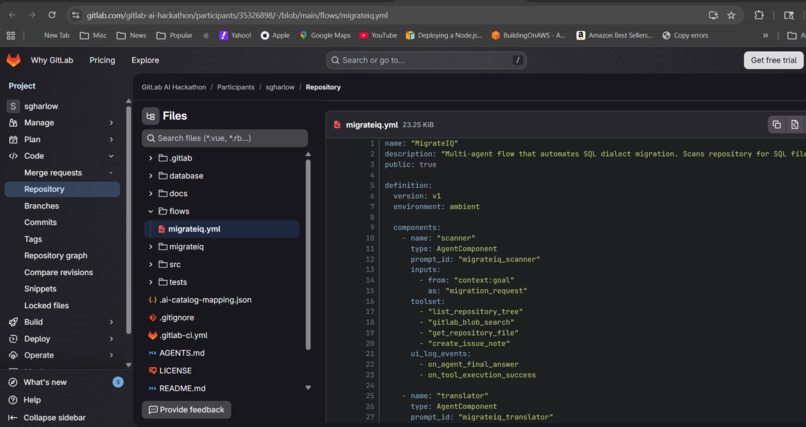
WideWorldImporters — natively compiled procedures, temporal tables, RLS, full-text search. Migrating to PostgreSQL: weeks of work,
-
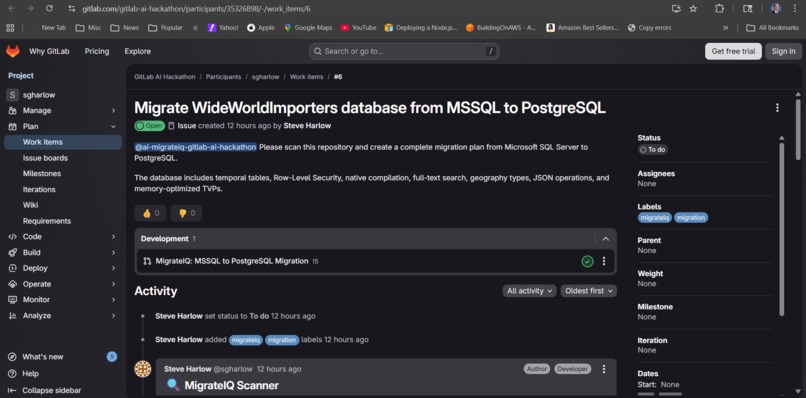
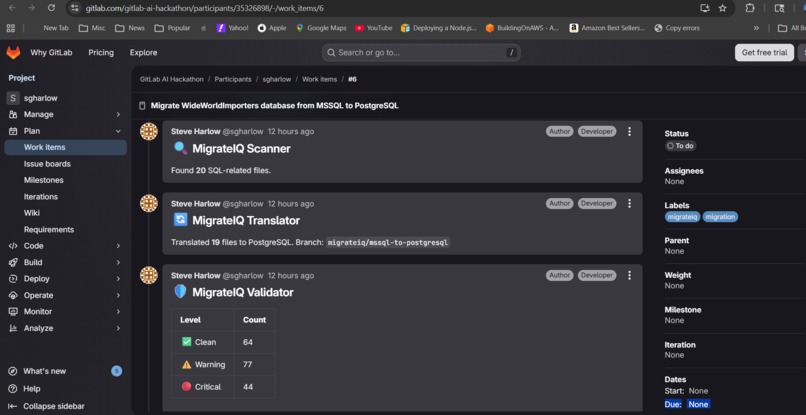
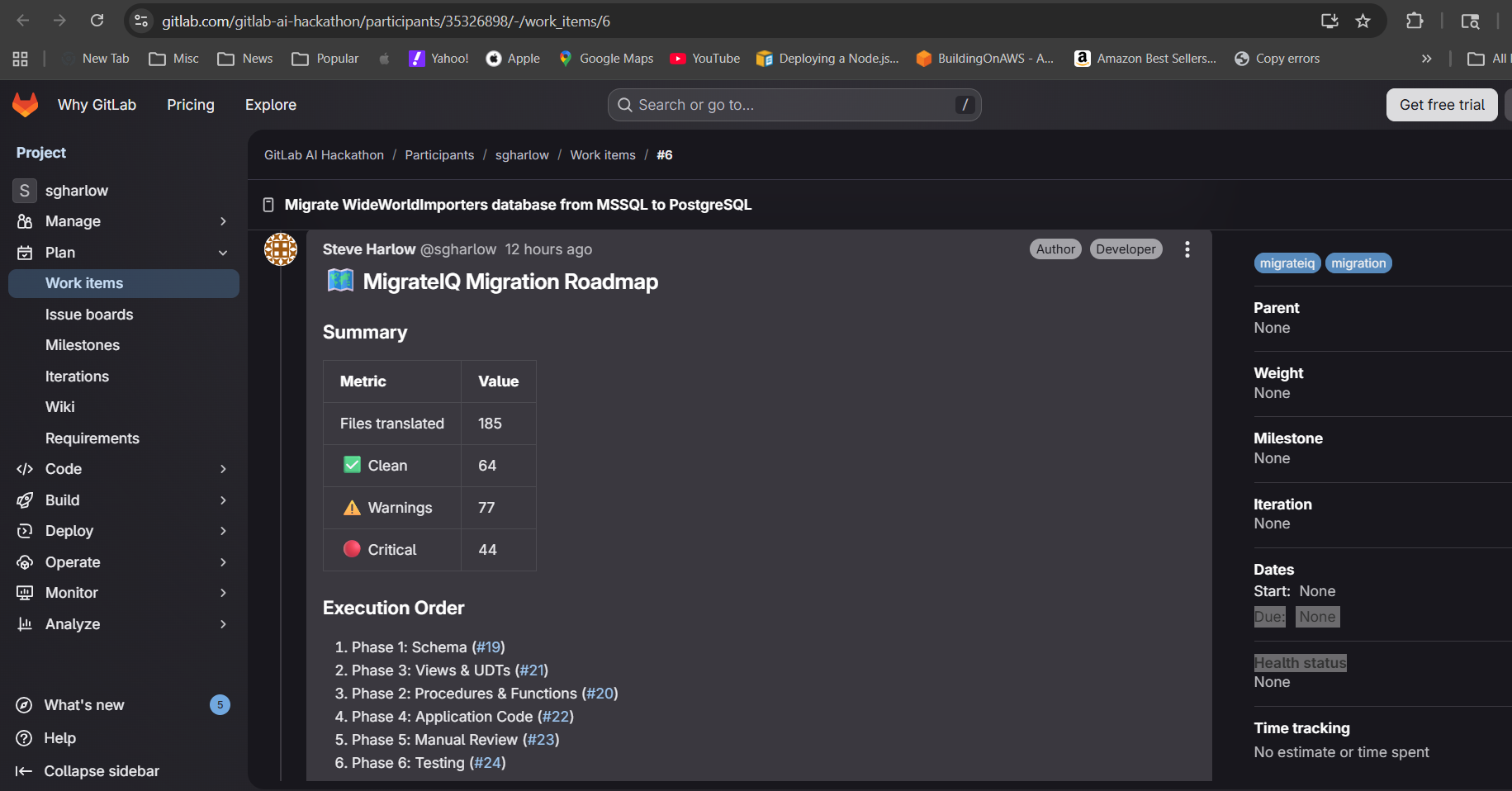
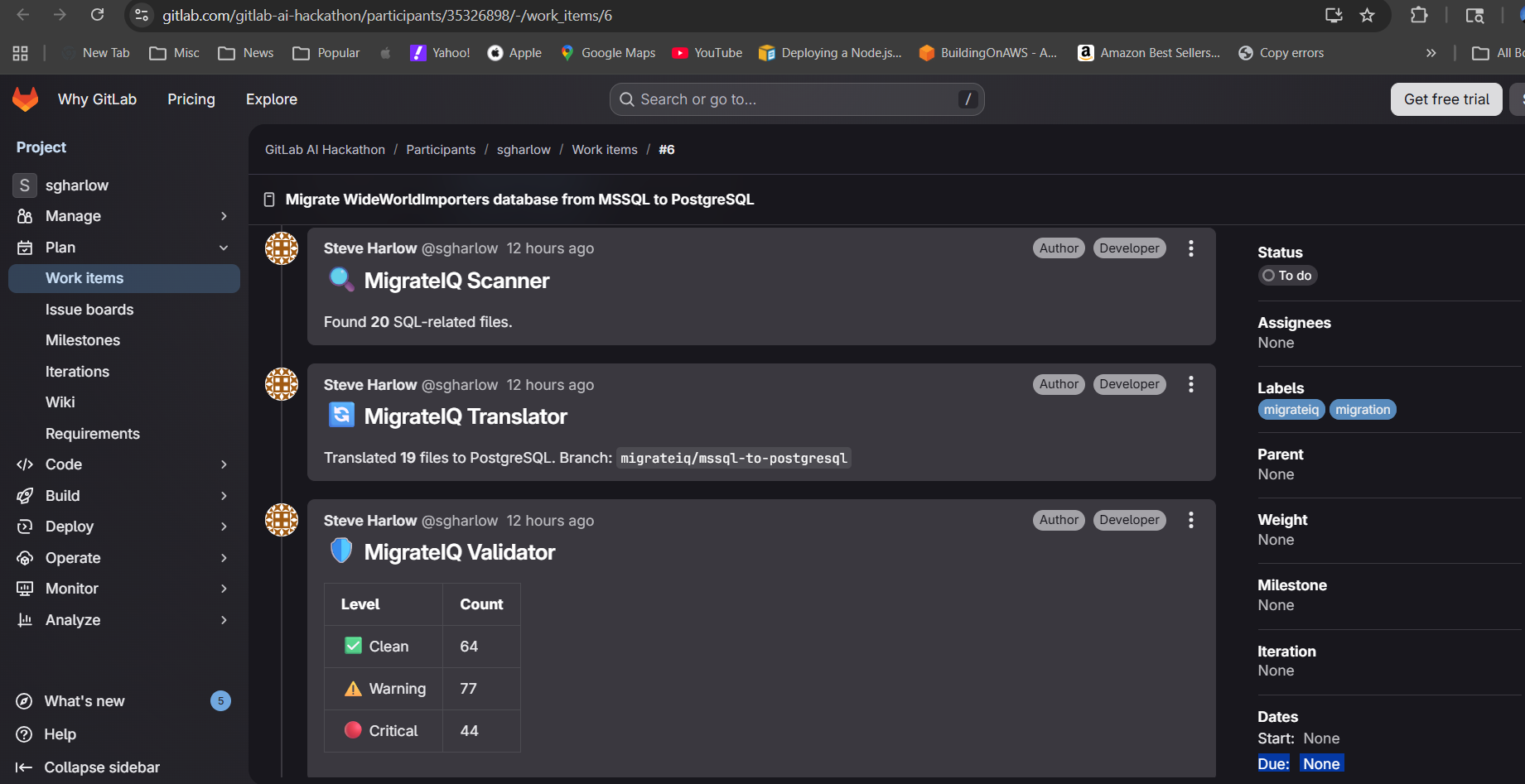
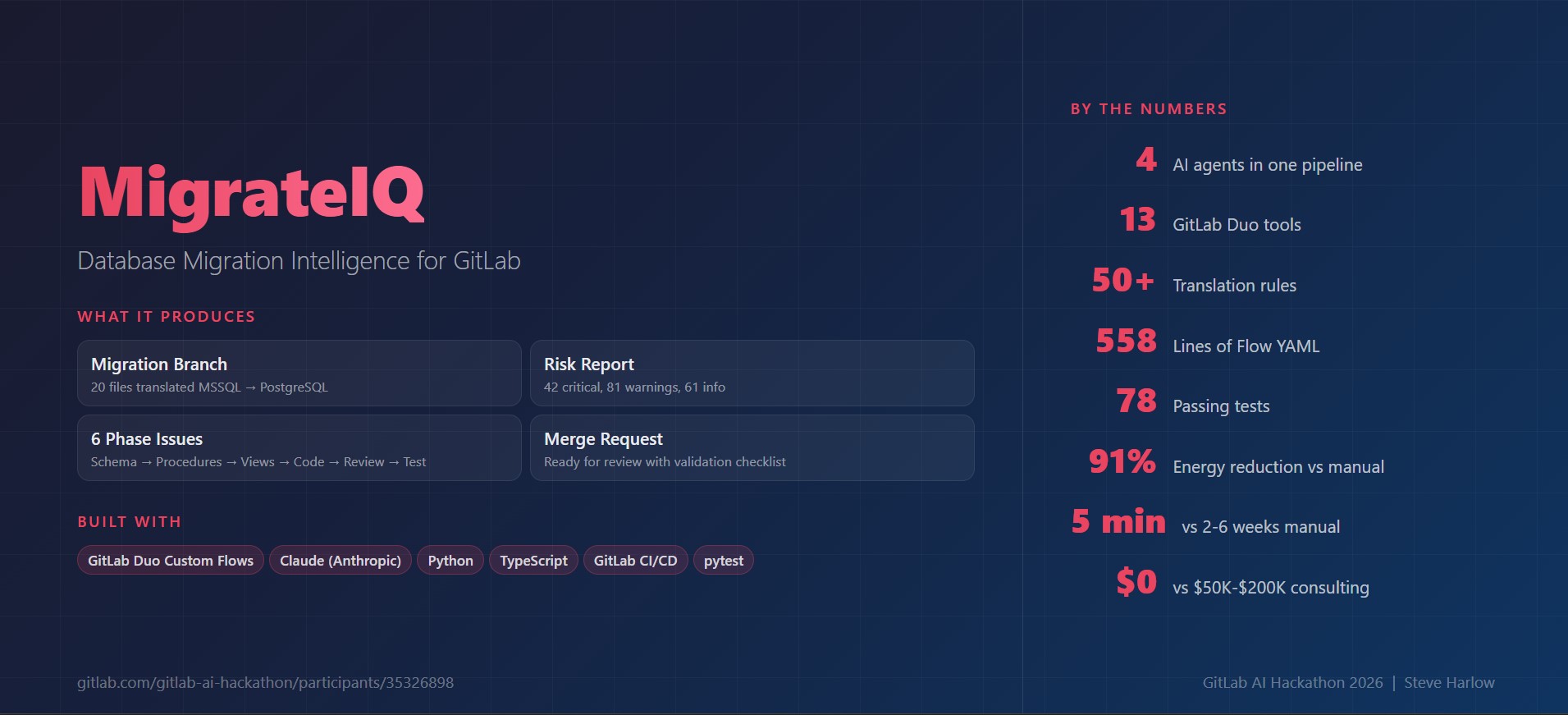
Scanner found 20 files. Translator converted all 19 using 50+ rules. Validator flagged 44 critical risks, 77 warnings.
-
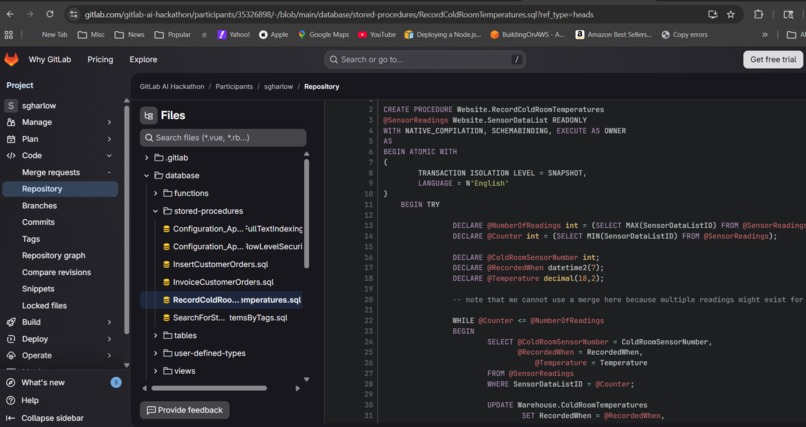
MigrateIQ runs 4 AI agents. One trigger, and Scanner, Translator, Validator, and Planner execute automatically.
-
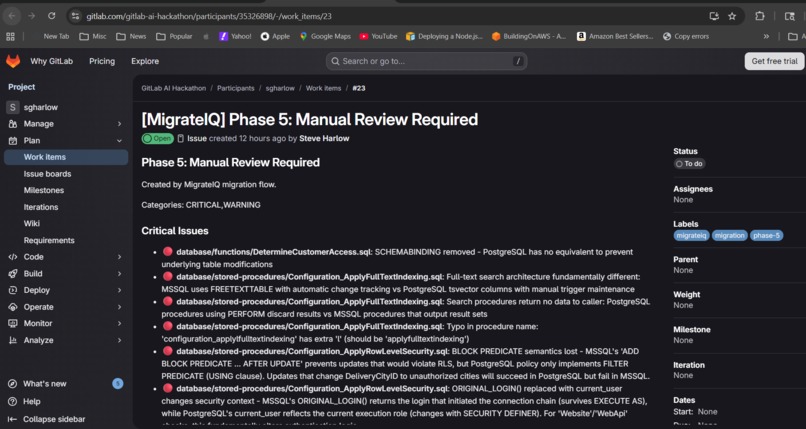
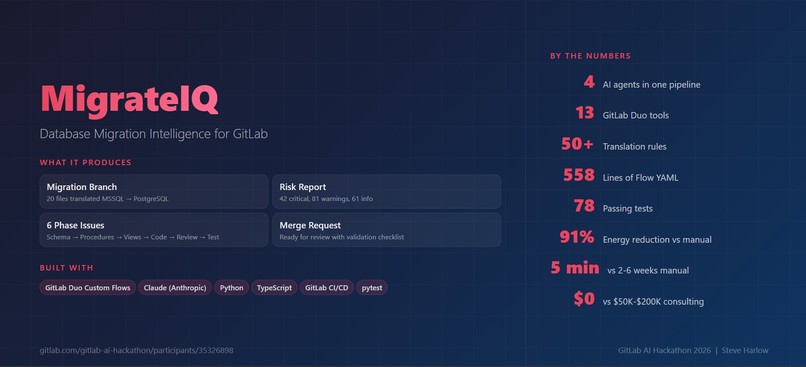
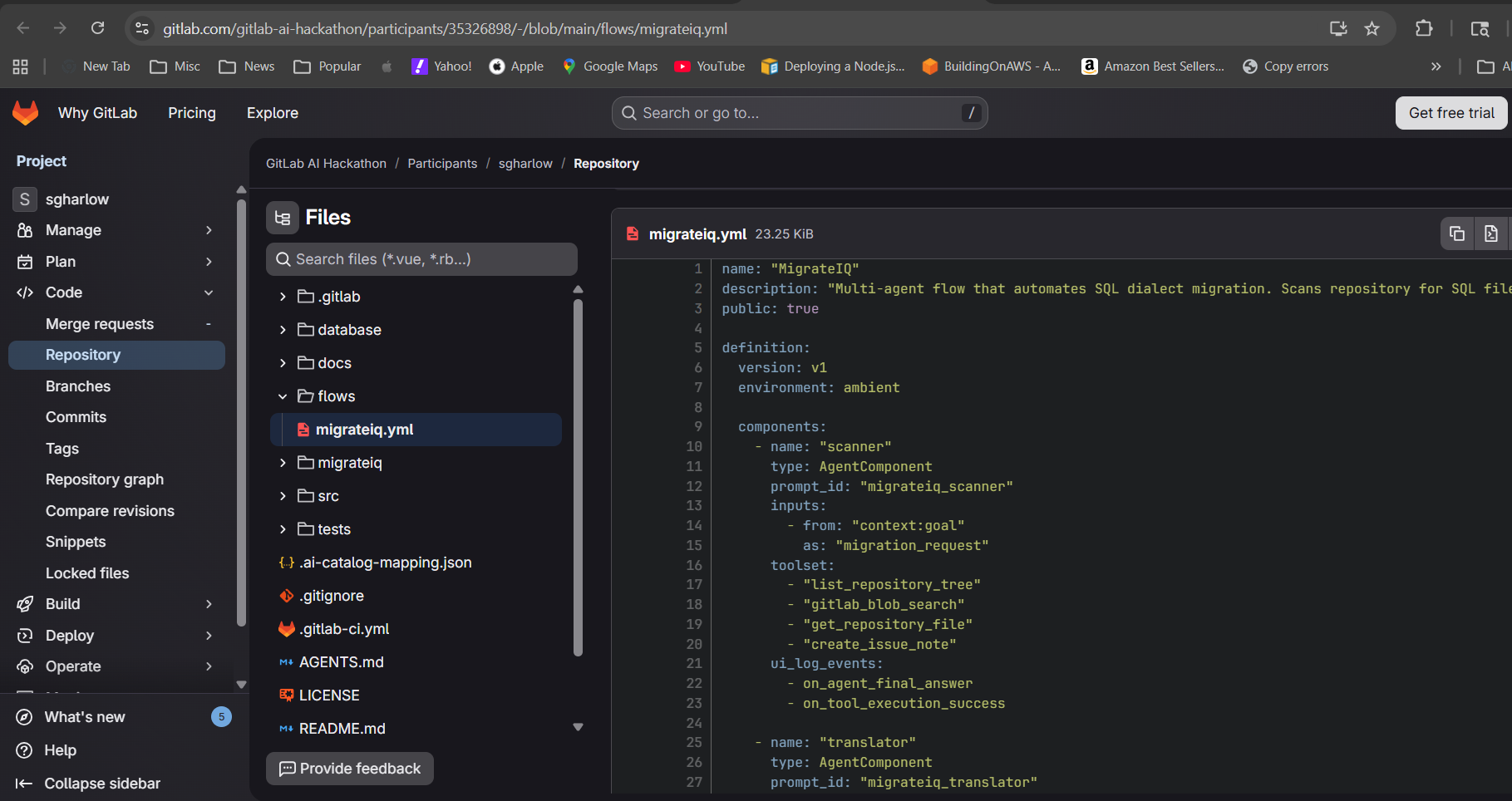
558 lines of YAML, 4 agents, 13 tools, powered by Claude. MigrateIQ — Database Migration Intelligence for GitLab.
-

Inspiration
Database migrations are one of the most expensive, tedious, and error-prone tasks in enterprise software. Migrating from Microsoft SQL Server to PostgreSQL for a mid-size application typically costs $50K--$200K in consulting fees and takes 2--6 weeks of manual effort. Every stored procedure, every table definition, every line of application code with inline SQL needs to be read, understood, rewritten, and validated by hand.
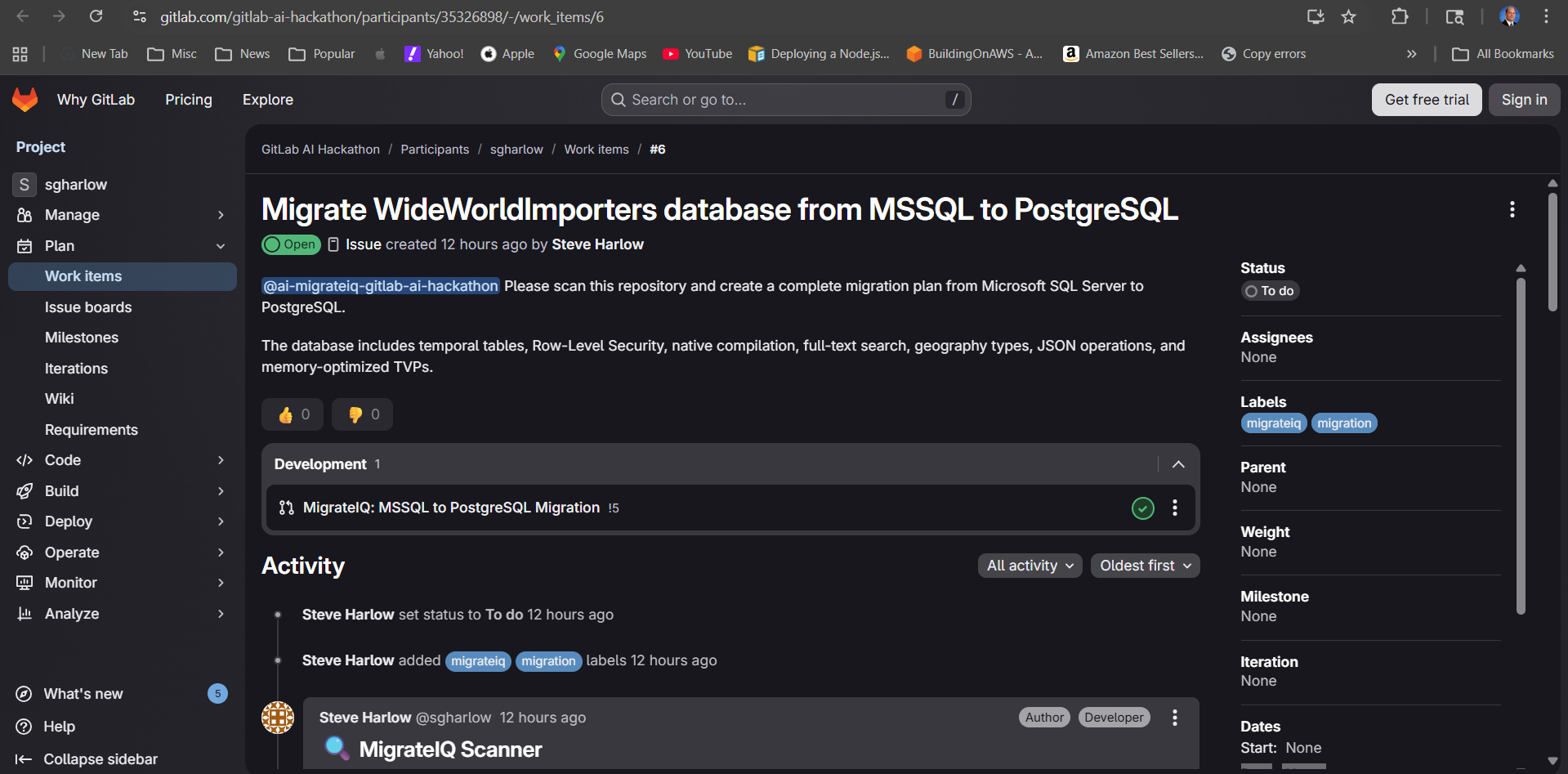
We wanted to know: what if a developer could create a GitLab issue, assign an agent, and walk away with a complete migration plan, translated code, and a risk report -- all generated inside the platform they already use?
The GitLab AI Hackathon challenge asked for agents that "react to triggers and take action." Database migration is the perfect fit: a clearly scoped, high-value problem where the agent can do real work -- not just chat about it.
What it does
MigrateIQ is a 4-agent pipeline built as a GitLab Duo Custom Flow that automates SQL dialect migration end-to-end. It activates when you mention @ai-migrateiq-gitlab-ai-hackathon on a GitLab issue. No CLI. No separate tool. One issue assignment starts the entire pipeline.
Here is what happens in the next five minutes:
Scanner Agent walks the full repository tree, reads every file, and classifies 19 SQL and TypeScript files into 6 categories (DDL, stored procedures, functions, views, user-defined types, application code). It detects the source dialect as MSSQL from patterns like
[bracketed]identifiers,IDENTITY,CROSS APPLY, andFOR JSON.Translator Agent converts every file from T-SQL to PostgreSQL 15+, applying 50+ translation rules covering data types (
MONEYtoNUMERIC(19,4)), syntax (TOPtoLIMIT,ISNULLtoCOALESCE), procedures (TRY/CATCHtoEXCEPTION), JSON operations (FOR JSON AUTOtojson_agg), security (SECURITY POLICYtoCREATE POLICY), full-text search (FREETEXTTABLEtotsvector/tsquery), and application code (mssqlnpm driver topg). It commits all translated files to amigrateiq/mssql-to-postgresqlbranch in logical batches.Validator Agent reviews every translation and flags risks at three severity levels:
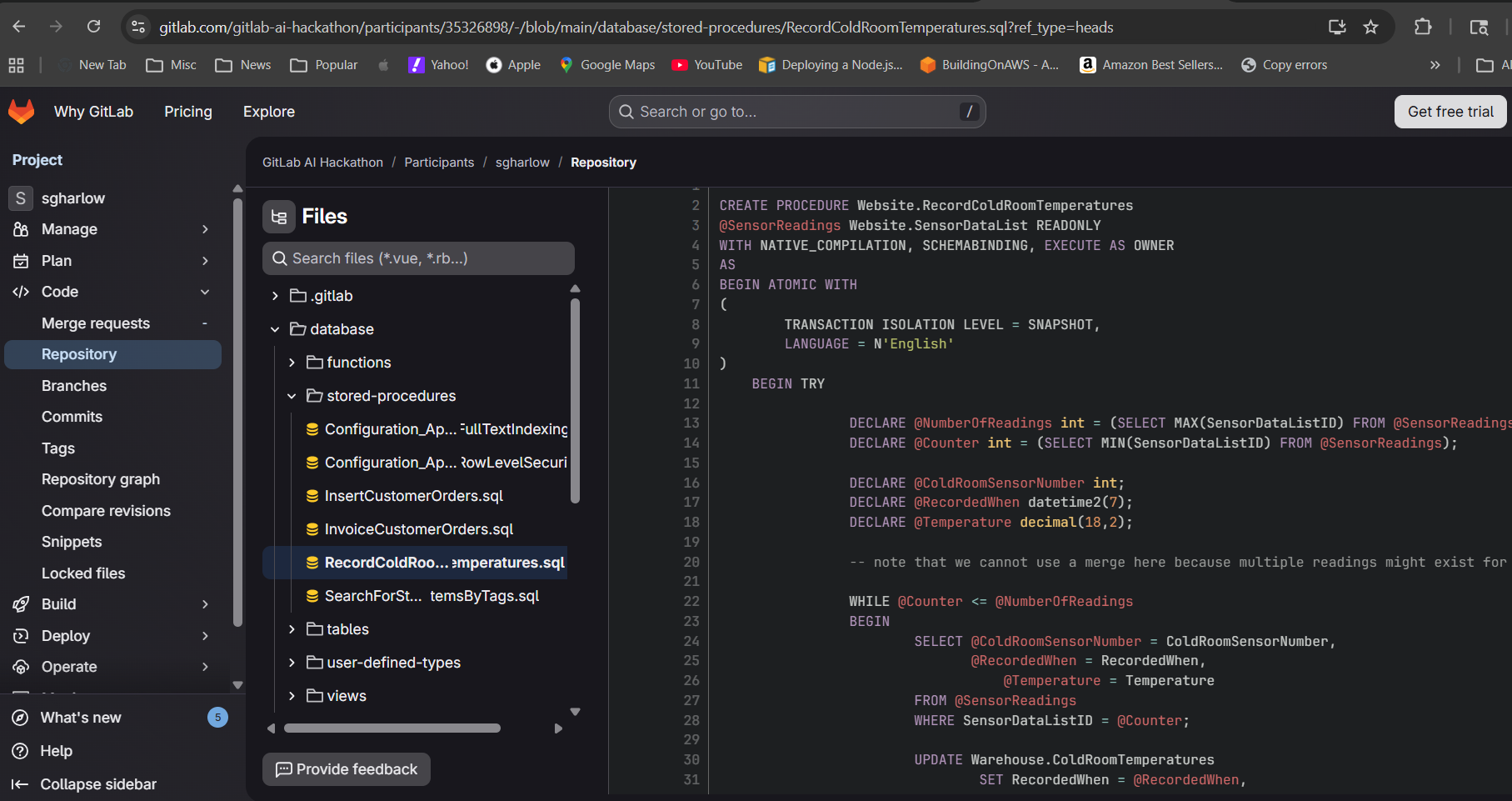
- Critical: Features with no PostgreSQL equivalent -- natively compiled procedures (
WITH NATIVE_COMPILATION),DECOMPRESS()with no direct PG match, memory-optimized table types - Warning: Behavioral differences -- Row-Level Security implementation semantics, temporal table trigger-based approach vs native system versioning, full-text search ranking algorithm differences, PostGIS extension requirements
- Info: Clean translations that need no further review
- Planner Agent creates 6 sub-issues (one per migration phase: schema, procedures, views/types, application code, manual review, testing), a merge request with a review checklist tied to every critical and warning finding, and a migration roadmap with effort estimates, dependency ordering, and prerequisite steps (e.g., install PostGIS, configure GUC namespace for RLS).
The developer gets back a complete, actionable migration plan -- not a summary, not a suggestion, but real translated code on a branch, real issues in their backlog, and a real MR ready for review.
How we built it
Platform: GitLab Duo Custom Flows (Agent Platform)
The core is a 550+ line flow definition (flows/migrateiq.yml) that chains four AgentComponent nodes with explicit routing: Scanner -> Translator -> Validator -> Planner -> end. Each agent has a dedicated system prompt with detailed translation rules, output contracts (JSON schemas), and error handling instructions.
13 unique GitLab Duo tools across the pipeline:
| Agent | Tools | What They Do |
|---|---|---|
| Scanner (4) | list_repository_tree, gitlab_blob_search, get_repository_file, create_issue_note |
Walk the repo, search for SQL patterns, read files, post scan report |
| Translator (3) | get_repository_file, create_commit, create_issue_note |
Read originals, commit translations to migration branch, post progress |
| Validator (3) | get_repository_file, get_commit_diff, create_issue_note |
Read translations, compare diffs, post risk report |
| Planner (8) | create_issue, update_issue, create_merge_request, create_merge_request_note, create_issue_note, create_plan, add_new_task, set_task_status |
Create sub-issues, MR, review checklist, roadmap |
LLM: Claude (Anthropic) via GitLab AI Gateway -- every inference call routes through GitLab's AI Gateway to the Anthropic API, automatically qualifying for the Anthropic sponsor track.
Demo repository: A curated subset of Microsoft's WideWorldImporters sample database (MIT licensed) -- 15 SQL files and 4 TypeScript files that exercise 17+ MSSQL-specific features including natively compiled stored procedures, temporal tables, Row-Level Security, full-text search, geography types, JSON operations, memory-optimized table-valued parameters, and DECOMPRESS.
External Agent fallback: A Python orchestrator (migrateiq/orchestrator.py) that replicates the same 4-agent pipeline via direct Claude API calls, runnable in GitLab CI/CD. This provides a backup execution path if the Custom Flow YAML has platform limitations, and demonstrates the same architecture in imperative code.
Test suite: 78 pytest tests covering all orchestrator functions -- JSON extraction (4 paths), GitLab API helpers, Claude API calls with token tracking, and each agent's logic (scanner classification, translator commit creation, validator risk categorization, planner issue/MR generation). All tests use mocked external dependencies; no real API calls.
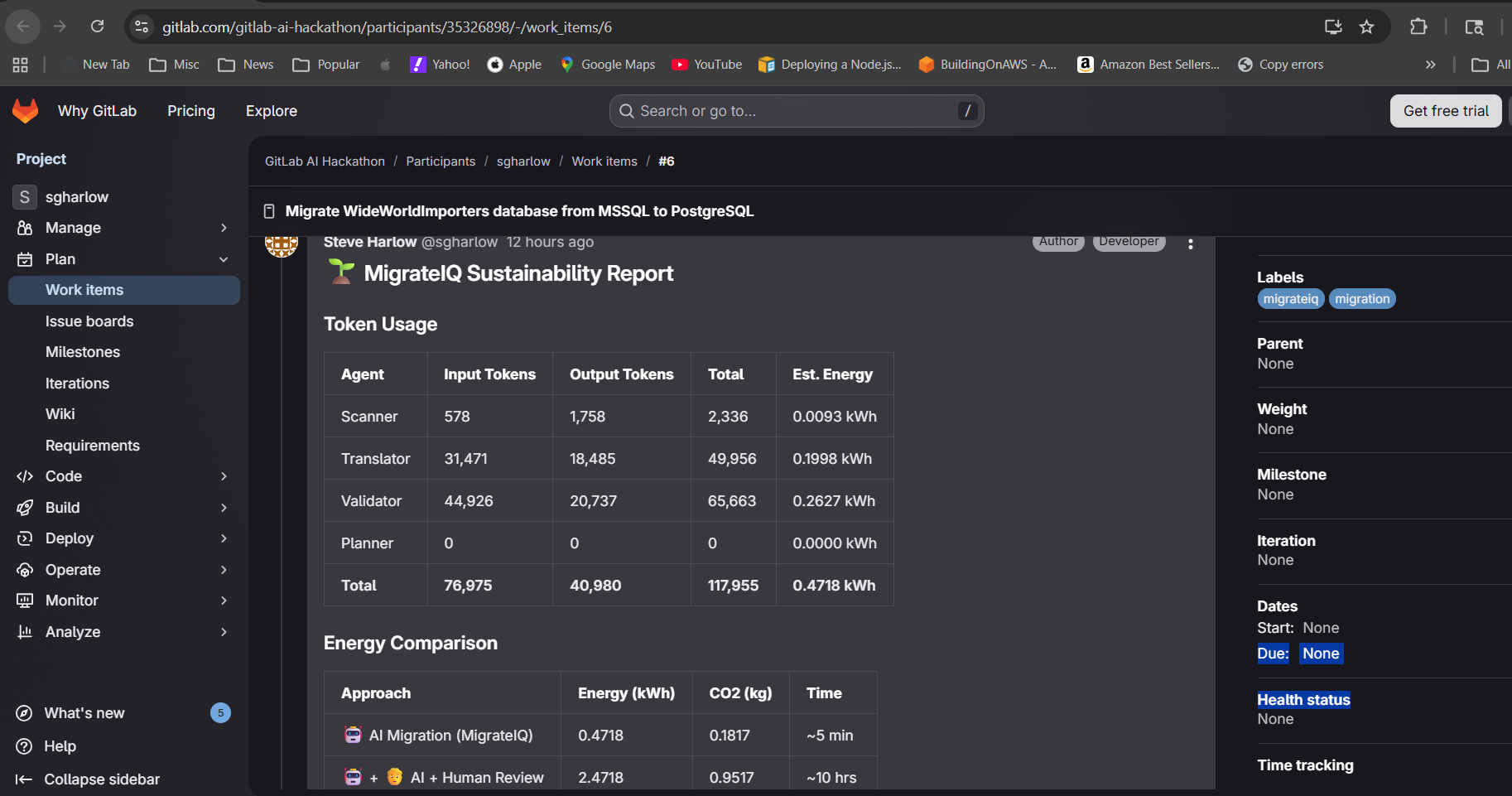
Sustainability tracking: A dedicated module (migrateiq/sustainability.py) tracks token usage per agent and estimates energy consumption. For this 19-file migration: ~0.68 kWh for AI inference vs ~7.6 kWh for a developer doing it manually. That is a 91% energy reduction.
Challenges we ran into
1. Designing output contracts between agents. Each agent's output becomes the next agent's input. Getting the JSON schema right -- especially passing the branch name and translations array from Translator through Validator to Planner -- required careful contract design. A missing field in the Validator's passthrough would silently break the Planner's merge request creation.
2. Translation edge cases that LLMs get wrong. MSSQL's JSON_MODIFY with nested paths, CONVERT with style codes (like style 126 for ISO 8601), and FOR JSON AUTO with ROOT wrapping all have subtle PostgreSQL equivalents. We had to encode 50+ explicit rules in the Translator's system prompt to prevent the LLM from hallucinating incorrect syntax.
3. The "no PG equivalent" problem. Some MSSQL features genuinely have no PostgreSQL equivalent -- WITH NATIVE_COMPILATION (In-Memory OLTP), DECOMPRESS() (built-in compression), and MEMORY_OPTIMIZED table types. The Validator needed to correctly identify these as critical risks rather than attempting a broken translation. This required making the Validator agent aware of what is missing, not just what is different.
4. Trigger-based activation on GitLab. The hackathon requirement is "agents that react to triggers." We configured the flow to activate on @ai-migrateiq-gitlab-ai-hackathon mention on an issue -- a native GitLab trigger, not a manual CLI invocation. Getting the trigger wiring right within the Duo Agent Platform constraints was non-trivial.
5. Keeping the pipeline idempotent. Running the flow twice on the same issue should not create duplicate branches or conflicting merge requests. The branch naming convention (migrateiq/mssql-to-postgresql) and the Planner's use of create_merge_request with a fixed source/target handle this gracefully.
6. Platform token scoping limitation. During development, we discovered that the GitLab Duo Flow executor generates tokens with insufficient scopes for tools like create_merge_request and create_issue_note (a known platform issue affecting multiple hackathon participants). We solved this by building a Python orchestrator (migrateiq/orchestrator.py) that implements the identical 4-agent pipeline via direct Claude API calls, executable in GitLab CI/CD. The Flow YAML defines the architecture; the orchestrator provides a working execution path. Both use the same agent prompts, tool set, and output contracts.
Accomplishments that we're proud of
One trigger, full pipeline: Mention the agent on an issue and receive translated code, a risk report, 6 phase sub-issues, a merge request with review checklist, and a migration roadmap. No human touches any translation code.
Real translation depth: 50+ translation patterns covering data types, query syntax, stored procedures, JSON operations, security (RLS), full-text search, temporal tables, application code driver migration, and MSSQL-specific features like native compilation and memory-optimized types.
Honest risk assessment: The Validator does not just rubber-stamp translations. It catches real issues -- native compilation removal with likely performance regression,
DECOMPRESSwith no direct equivalent, RLS semantic differences betweenSECURITY POLICYandCREATE POLICY, and temporal table implementation gaps.13 GitLab Duo tools in one flow: Scanner, Translator, Validator, and Planner each use a distinct combination of tools, demonstrating deep integration with the GitLab platform beyond simple chat.
78 passing tests with full mocking of external dependencies -- proving the orchestrator logic is correct without requiring API keys or a live GitLab instance.
Sustainability built in: Every run tracks its own token usage and compares AI energy consumption against manual developer effort. The 91% energy savings figure is based on published GPU power consumption research and EPA carbon intensity data.
What we learned
Agents need contracts, not just prompts. The biggest lesson was that multi-agent pipelines fail silently when agents do not have strict output schemas. Adding JSON output contracts to each agent's system prompt -- and making the Validator explicitly pass through Translator fields -- was the difference between a demo that works once and a pipeline that works reliably.
Translation is not the hard part; knowing what cannot be translated is. Any LLM can convert TOP to LIMIT. The real value is in the Validator correctly identifying that WITH NATIVE_COMPILATION has no PostgreSQL equivalent and flagging it as critical rather than silently dropping it. Risk classification is harder than translation.
GitLab Duo flows are powerful but require careful tool selection. Each agent can only access the tools in its toolset. Giving the Planner 8 tools and the Translator only 3 forces clean separation of concerns. This constraint actually improved the architecture.
Sustainability tracking changes how you think about AI workflows. When you can see that your 4-agent pipeline uses 0.68 kWh versus 7.6 kWh for a human doing the same work, it reframes the "should we use AI for this?" conversation from cost to environmental impact.
What's next for MigrateIQ
MySQL and Oracle PL/SQL to PostgreSQL: Extend the translation rules to cover the two other most common enterprise migration paths.
Incremental migration mode: Instead of translating the entire codebase at once, detect which files changed since the last run and translate only the delta.
Automated testing generation: Have the Planner agent create test cases (pgTAP or pytest) that verify each translated procedure produces the same output as the original.
Cost estimation: Add estimated migration cost (hours x rate) to the roadmap so teams can compare the agent's output against a consulting quote.
GitLab CI/CD integration tests: Run the translated PostgreSQL code against a real PostgreSQL instance in a CI pipeline to catch runtime errors before the merge request is reviewed.
Bidirectional migration: Support PostgreSQL-to-MSSQL for teams moving in the other direction.
Built With
- agent
- ai
- antropic
- ci/cd
- claude
- claude-sonnet-4-5
- duo
- gateway
- gitlab
- microsoft
- postgresql
- python
- server
- sql
- typescript
Log in or sign up for Devpost to join the conversation.