-
-
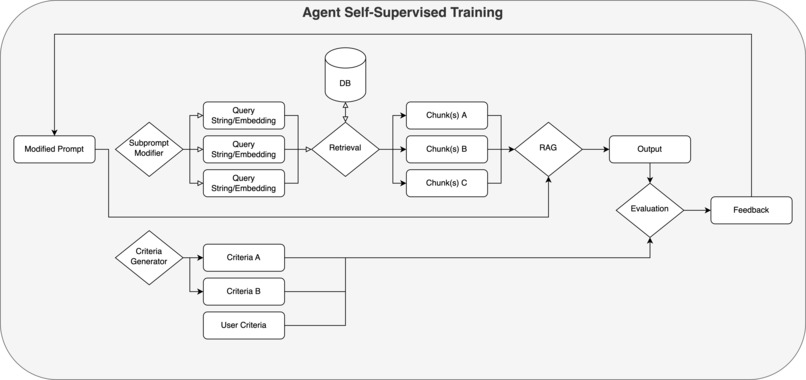
Midas Agent Training
-
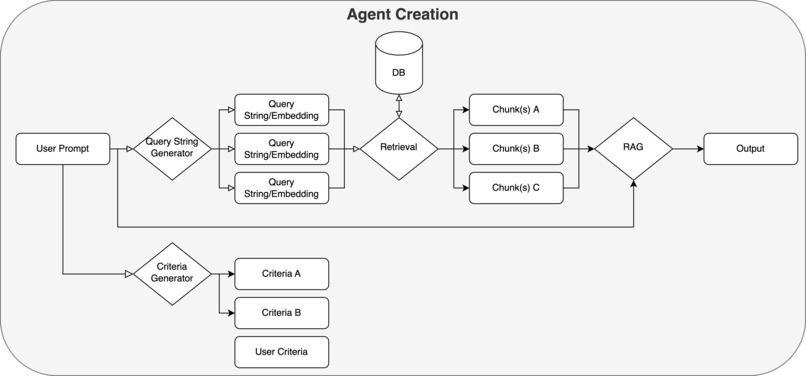
Midas Agent Creation
-
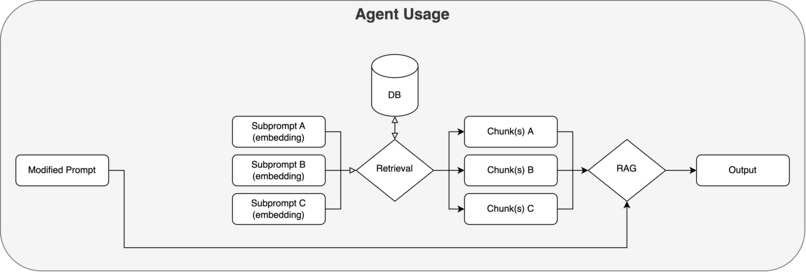
Midas Agent Usage
Inspiration
LLMs have recently seen a breakthrough in ability to general high quality natural language. However, one obstacle to widespread production-grade adoption is the inconsistency of the output, making it risky, unreliable, and impractical to implement in a production setting such as data pipelines.
High quality structured data is a necessity in modern data pipelines, with APIs and functions requiring precise inputs in designated fields to function correctly.
Current methods to achieve this with LLMs are often slow and manual, involving prompt tuning and a long chain of agents.
Midas provides a fast, low code, self-supervised, highly interpretable, production grade solution to this problem.
Our chosen use case focuses on sales representatives who need help summarizing a variety of complex and detailed interactions with their clients into eventual sales orders into applications like salesforce sales cloud.
What it does
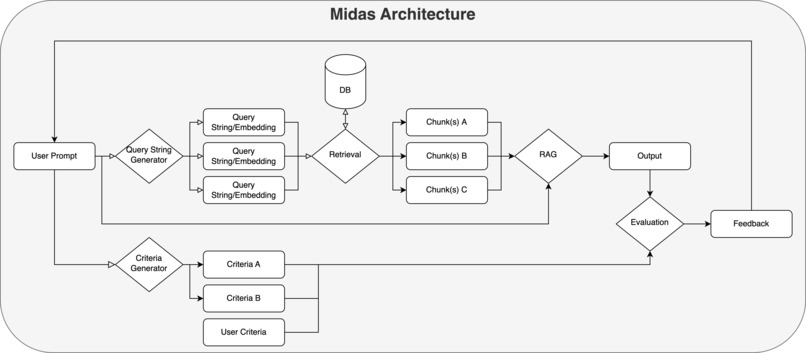
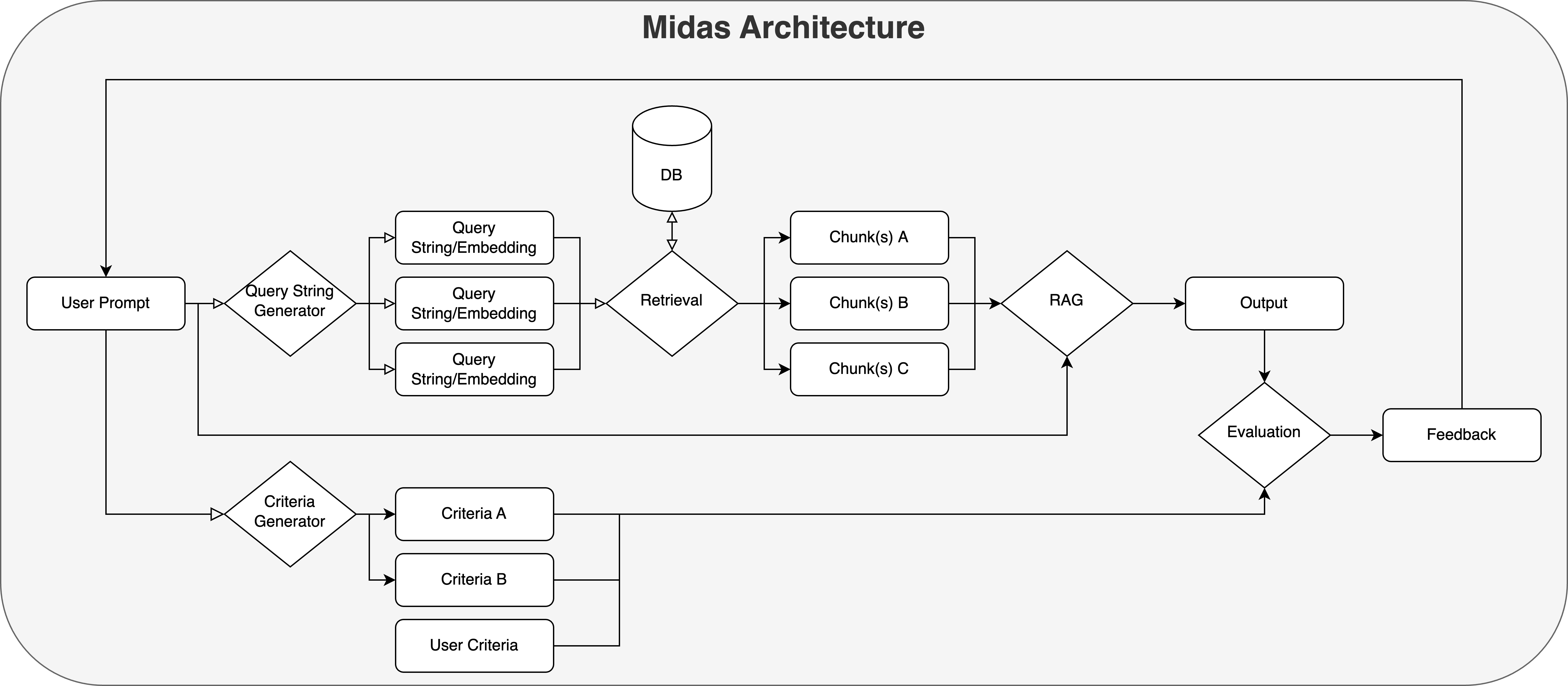
Midas is a library that provides a framework for creating, training, and running user defined agents. Our current version trains agents to parametrize unstructured email threads and transcripts into a structured JSON format through a novel RAG framework.
Our solution ensures seamless integration with tech pipelines, maintains consistent and accurate data structuring, and addresses the challenges traditional LLMs face with large datasets.
How we built it
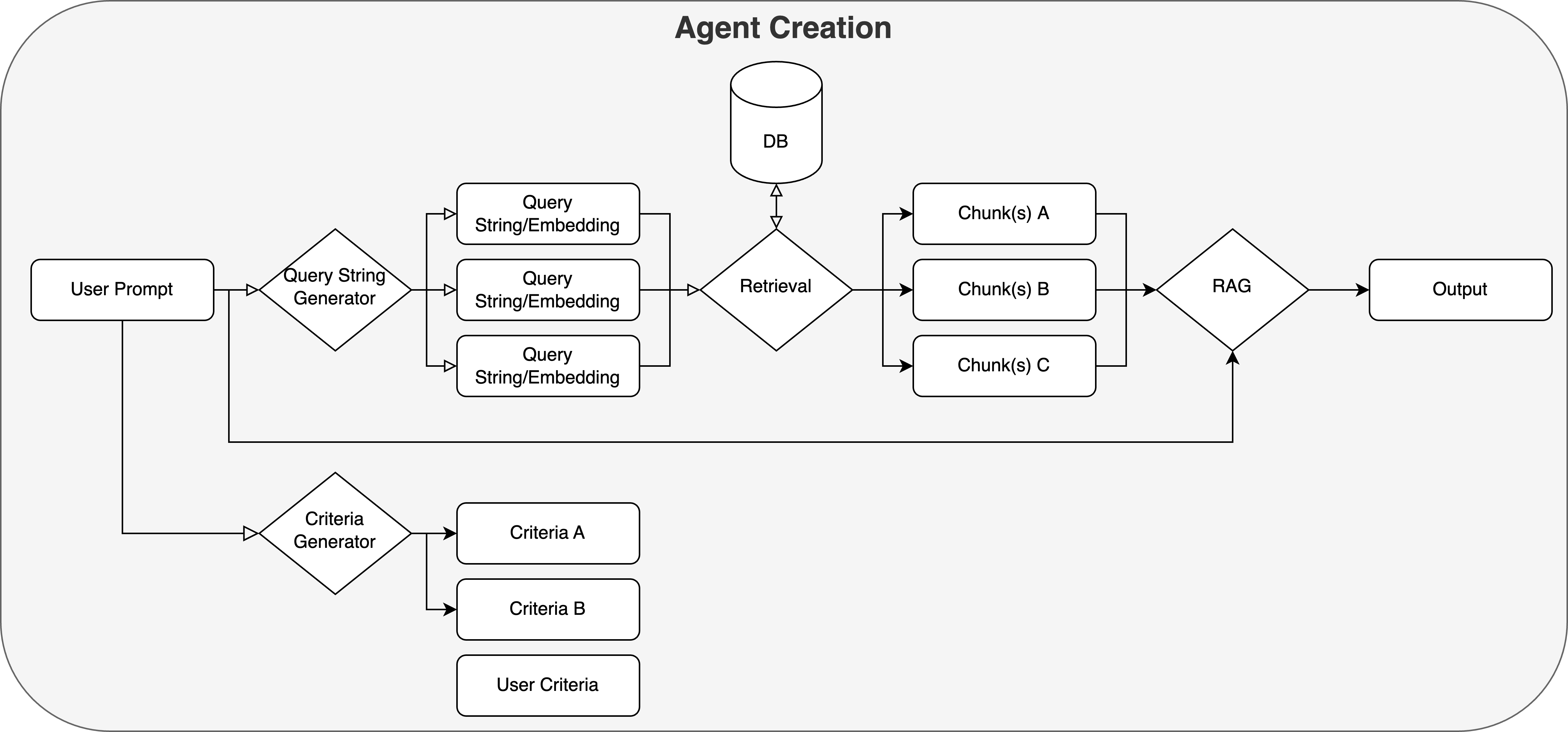
Agent Creation
Our agent first uses a subquery generator to identify key topics in the user’s original prompt, generating a list of specific topics that aid in semantic search during. These are then embedded using bge-small-en-v1.5 for use during RAG.
Midas also generates (and allows the user to input) a list of criteria in order to evaluate the eventual output that is generated by the agent.
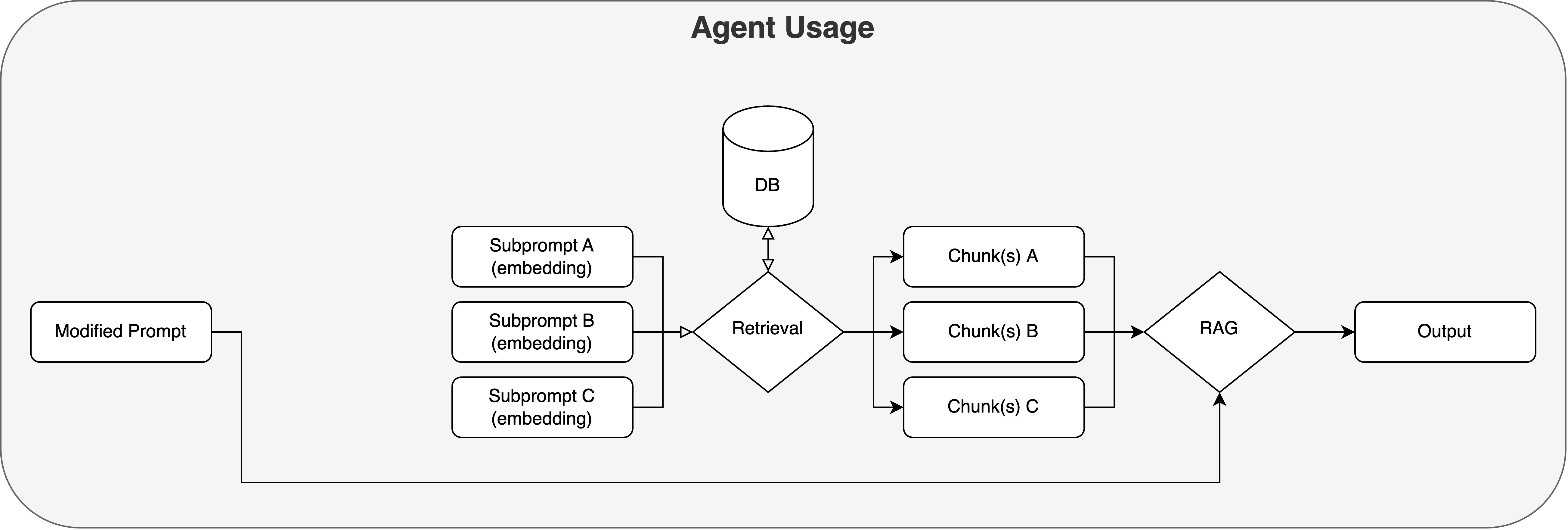
Agent Run
Our agent uses the generated subquery embeddings to retrieve the relevant, metadata and topic-laden chunks, in addition with the original prompt and the agent/user defined criteria in order to produce an output.
This usually only takes a few seconds because all the subqueries embeddings can chunks in parallel, and only one generation step is performed.
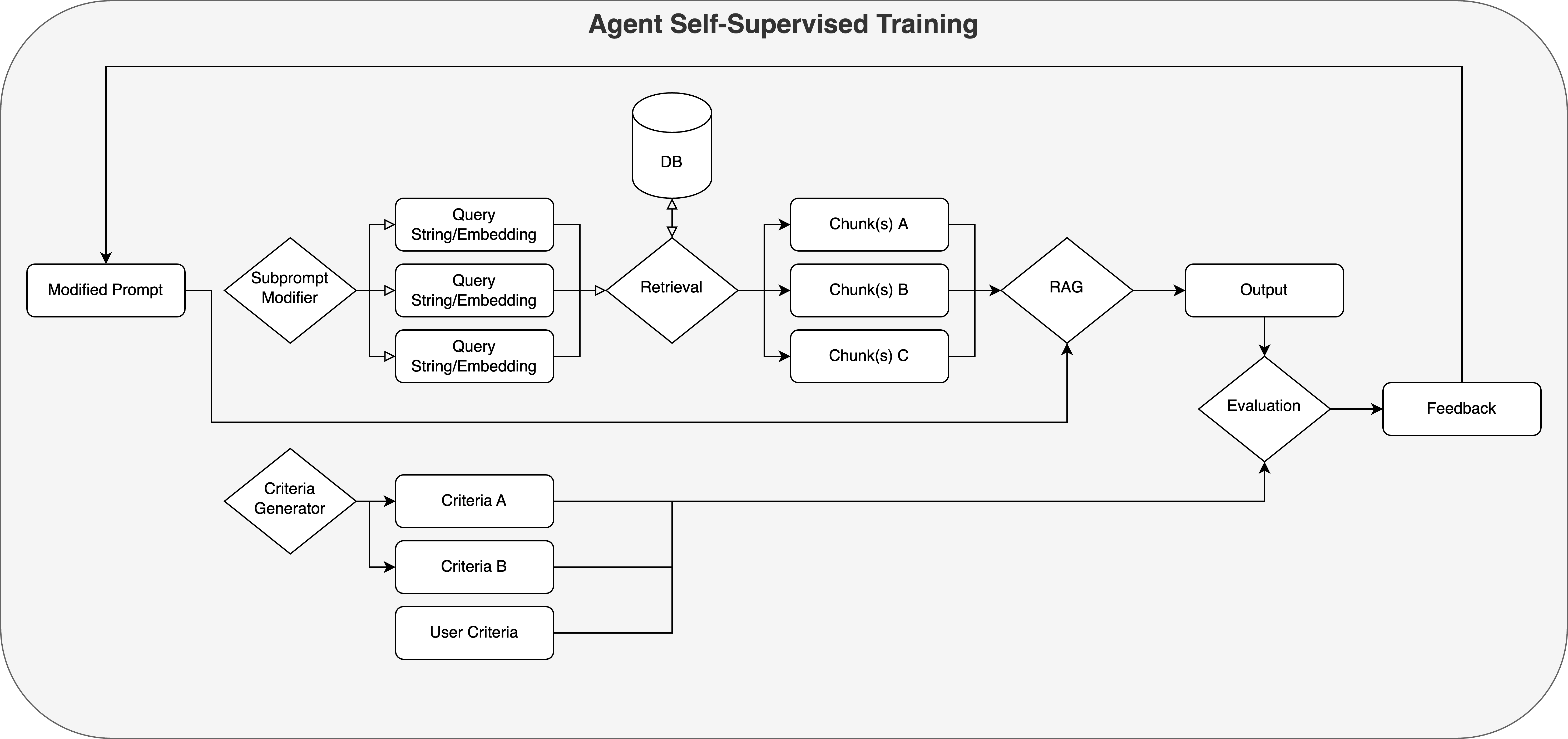
Agent Training
Using the output of a run, the Agent goes through the criteria and provides feedback of the generated response and suggesting potential improvements to improve the quality of the output.
Then, it uses this performance evaluation to update and override the initial user prompt to create an improved version of the query for use in future iterations.
Agent Saving/Loading
All the parameters needed to store and run an Agent are in a single, easily interpretable JSON file.
Challenges we ran into
The challenges we encountered during the project ultimately inspired the architecture we created during this hackathon. Initially, we planned to use GPT to perform a basic RAG on email threads and transcripts. Upon doing so, we encountered inconsistent outputs with our JSON data structures and inaccurate ones. We implemented a recursive loop to optimize our prompts to solve this problem.
Another challenge we ran into was that some email threads were not large enough to split up threads into clean chunks which we addressed through creating subqueries to better retrieve our data.
Accomplishments that we're proud of
Our proposed architecture significantly improves LLM performance compared to native GPT performance, both in consistency and accuracy of results. The solution can eventually be created into a package that can be utilized by a range of users and applied to a range of use cases.
What's next for Midas
For this solution to be utilized, it will have to integrate with tools already used in industry. In our use case, we want to be able to convert our JSON to a sales receipt and upload it to salesforce cloud to complete our use case. Additionally, we’d like to more closely quantify the improvements of the improved performance of our trained prompts. Finally, we’d like to package this method (potentially with LlamaIndex) for broad use.
Built With
- astradb
- gpt
- huggingface
- llamaindex
- python
- streamlit



Log in or sign up for Devpost to join the conversation.