-
-
Poster for REDER
REDER (Related Domain Experience Replay)
Members
| Name | cslogin |
|---|---|
| Raymond Dai | rdai4 |
| Richard Tang | rtang26 |
| Akash Singirikonda | asingir1 |
| Kenta Yoshii | kyoshii |
Link to a Google Drive folder with the demo video and the write up. Check out some cool gifs of our model in action!
Introduction
Artificial Intelligence has been used to train models on increasingly complicated games, from Chess to Go to Starcraft 2. These models have mainly been trained on a specific game, using techniques such as adversarial search and deep reinforcement learning (RL) with Monte Carlo Tree Search (MCTS) to optimize performance on that single board game. While successful, these models essentially train on exorbitant amounts of data, and must re-learn novel games from scratch.
We hypothesize that while games have different rules, their underlying mechanics are largely similar, so training on one game should theoretically improve performance across other games. Specifically, using shared experience replay, we hope to employ RL to learn a general structure of similar games
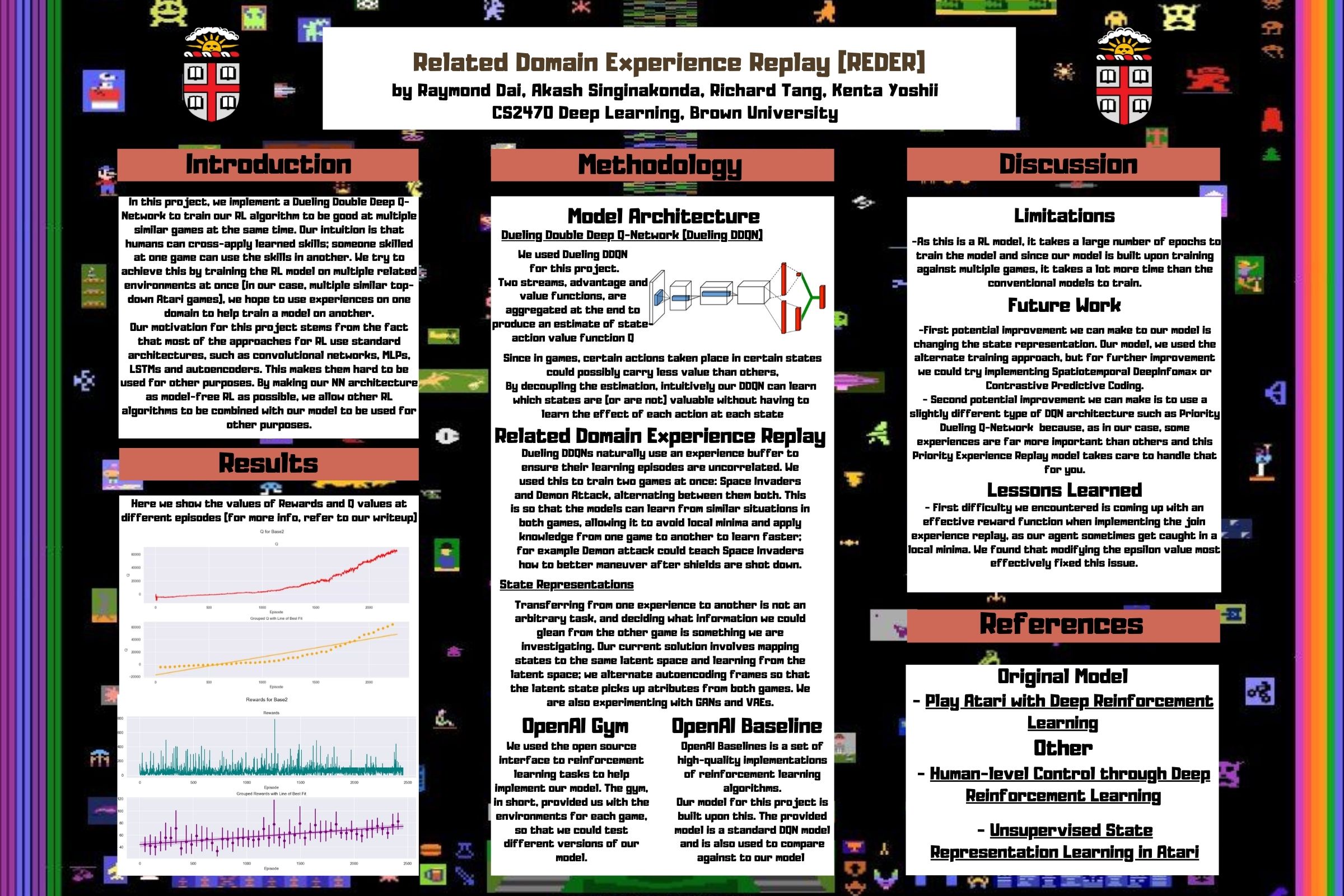
Results
Regular Dueling DDQN


Dueling DDQN with Joint Experience Replay (our model)


The top gameplay is by the Dueling DDQN. The bottom two gameplays are by the Dueling DDQN with Joint Experience Replay. Due to time limitations, we only trained each model for certain number of steps. Based on this comparison, following points can be made:
The regular Dueling DDQN model knew to shoot the bonus point red ship whenever it comes out. In contrast, our model pretty much ignored it.
- This could be explained by the fact that since it is also trained on DemonAttack by means of Joint Experience Replay, the importance of the red ship (which does not exist in the latter) did not get much importance (experience did not get shared).
Dueling DDQN with Joint Experience Replay model could be interpreted as a little more "aggressive" than the baseline model as we can see from how it shoots off the objects from the get-go and by looking at the end result suggests.
Finally, as we can see from the two gameplays, the Doueling DDQN with joint experience replay does okay on both games. However, when comparing DemonAttack and SpaceInvaders, it becomes clear that it performs better on the latter. This might be attributed to the fact that some experiences are unequally prioritized over others.
Related Work
- Play Atari with Deep Reinforcement Learning
- Human-level Control through Deep Reinforcement Learning
- Unsupervised State Representation Learning in Atari
Data
Since REDER is a reinforcement model without any teacher enforcing, there is no need for us to collect data for this project. One thing to note is that we will be using OpenAI Gym to get access to the simulated environments for each game we will be using. With these simulated environments, our group is planning on training multiple models and comparing their performance to see how our REDER performs with respect to other existing models. Thankfully, OpenAI has baseline implementation entirely open to access, making the process of comparing a lot more simple. As for the actual games we are going to use to train our model, we will be using SpaceInvaders-v0 and DemonAttack-v0.
Methods
We used Dueling Double Q-Network(DDQN) for this project. Two streams, advantage and value functions, are aggregated at the end to produce an estimate of state-action value function Q. Since in games, certain actions taken place in certain states could possibly carry less value than others. By decoupling the estimation, intuitively our Dueling DDQN can learn which states are (or are not) valuable without having to
learn the effect of each action at each state.
The above model serves as our general model structure. To realize our goal of creating a model that is extensible among similar atari games, we first tried implementing a GAN as our shared buffer. However, this approach turned out to be infeasible since GAN required us to have even more weights and added significant amount of time for our model training (running for 1 epoch took us 10 minutes). Instead of using GAN, we followed a naive approach where we first initialized the experience buffer with randomly generated experiences from each game (Half from each). We then alternate playing each game by frame while training, storing each stack of frames in the experience buffer. We hypothesize that the q function would learn to identify similar situations in both games and use that experience to learn faster and avoid local minima. SpaceInvaders becomes similar to DemonAttack when the shields disappear.
Finally, we test our model on each game to see how well the model perform when compared with the OpenAI Baseline model.
Metrics
We will consider OpenAI baseline implementation as our standard and will compare our model against it.
A success constitutes an experimental architecture training correctly to convergence, even if it might not perform as well.
The training and testing environments will be chosen from OpenAI Gym.
Accuracy does not apply; rather having an agent maximize its reward quickly as possible is an important metric to track in RL.
Base goals: Implement DDQN and a standard RL model. Our model should be able to learn from SpaceInvaders-v0 and reach the score of 300 per episode.
Target Goals: Implemented Dueling DDQN with naive state representation shows moderate signs of learning from SpaceInvaders-v0 and DemonAttack-v0. This model then should be able to achieve 500 per episode on SpaceInvaders-v0.
Stretch Goals: Implemented Dueling DDQN with complex state representation shows strong signs of learning from SpaceInvaders-v0 and DemonAttack-v0. This model then should be able to achieve 700 per episode on SpaceInvaders-v0
Ethics
Why is Deep Learning a good approach to this problem?
In games, environment, rules, and operations are relatively complicated. In order to achieve the goal of letting the machine play the game, we need to make it perceive the screen display or information of the game, understand the rules of the game, and be able to find a way to correctly lead to higher scores in practice. The deep convolutional neural network in deep learning is very suitable for processing visual information and can solve the problem of visual information perception. Deep neural networks can be used to fit most functions, including the rules of the game. Deep reinforcement learning has the ability to learn all kinds of behaviors needed to play a game well. Compared with other methods, deep learning methods can also reduce the dependence on a large number of manually set action rules. Based on the above reasons, we believe that deep learning is a very good choice for machines to play games.
How are you planning to quantify or measure error or success? What implications does your quantification have?
In the field of games, we usually use a score to mark the achievements and progress of game players. The reinforcement learning model we use should be able to describe the actual situation corresponding to the score, and make the correct response and action to maximize the score. Under normal circumstances, the game will set a rule and a total score. Whenever the player completes a certain behavior, the player's score will increase. Of course, there are many complicated situations. In some games, the game will have multiple scores. And even in some cases these scores will be used and reduced. In this case, we need to set some importance, upper and lower bound limits for these different scores. For example, some games have the value of money, and players can choose to consume a certain amount of money in exchange for other scores or changes the game content. We need to set a more refined reinforcement learning reward function to accomplish these things. Some games do not have a clear and fixed score to indicate the current state of the game, or the state is not clear before the end of the game, such as chess. For this, we need to use other deep learning methods to describe the state. In general, for the games we are studying, we can use a single score to quantify our success and failure. The higher the single score, the better and more successful our method is.
Division of Labor
Richard:
- Base model research and implementation of the Dueling DDQN Model
- Shared experience buffer research and ideation
- OpenAI Gym environment pre-processing
- Python environment setup, user command-line integration, model checkpoint saving/loading
- Episodic visualization, metrics logging
- Model training data generation
- Final technical report write-up
Raymond:
- Shared experience buffer and state representation research, ideation, and implementation
- State-to-State Translation, Delta (with Time) Mapping, VAE + GAN latent space implementation
- Model training data generation
- Metrics (loss, Q-values, rewards, episodes) visualization
- Model metrics analysis
Kenta:
- Base model research and implementation of DQN Model
- Shared experience buffer research and ideation
- Google Cloud Compute Engine integration
- Model training data generation
- Poster presentation, DevPost write-up, Final Video editing
- Model visualization
Akash:
- Shared experience buffer and state representation research, ideation, and implementation
- Implementation of joint naive shared experience Dueling DDQN Model
- Google Cloud Compute Engine integration
- Model training data generation
- Episodic visualization
Useful Links
Link to a Google Drive folder with the demo video and the write up. Check out some cool gifs of our model in action!






Log in or sign up for Devpost to join the conversation.