-
-

Training of the model with several iterations to improve robustness and avoid overfitting
-

Selfmade Datasets (around 100 Images in total)
-

Testing the Pose Estimation Model in our deployed live server combined with the CNN classifier


Inspiration
70 million deaf people struggle to communicate in their daily life. Goal: Facilitate everyday communication making the world more accessible to people suffering from hearing disabilities.”
What it does
Our solution records the sign gestures of people and translate them into text or speech for non-deaf people. The NN algorithm is highly customizable for all the variety of signs languages around the world (300!). Furthermore, the solution makes it possible that deaf people can communicate between each other with different sign languages (there are 300 different ones)
How we built it
Our Demo consists of two separate Parts. A Frontend for Pose estimation, Landmark Prediction and feature extraction as well as a custom trained Image Classifier in the Azure Cloud.
The user Interface is a simple Javascript WebApplication which opens the users webcam and runs Google’s State-of-the-Art Holistic Pose Estimation Model. This Tensorflow lite models allows us to do realtime, clientside! human pose, face landmarks, and hand tracking. In Detail the prediction pipeline uses a two-stage approach where first the whole pose is detected followed by further usage of specialized models for hands and face. This results in a total of over 500 individual Landmarks which we also display back to the user. As soon as we captured the hands we crop the input image and send them to our Azure Cloud Endpoint to classify the Sign. We are well aware of the fact that the individual Landmarks offer a lot of additional information for gesture prediction but due to the format of this competition we decided to just use vision.
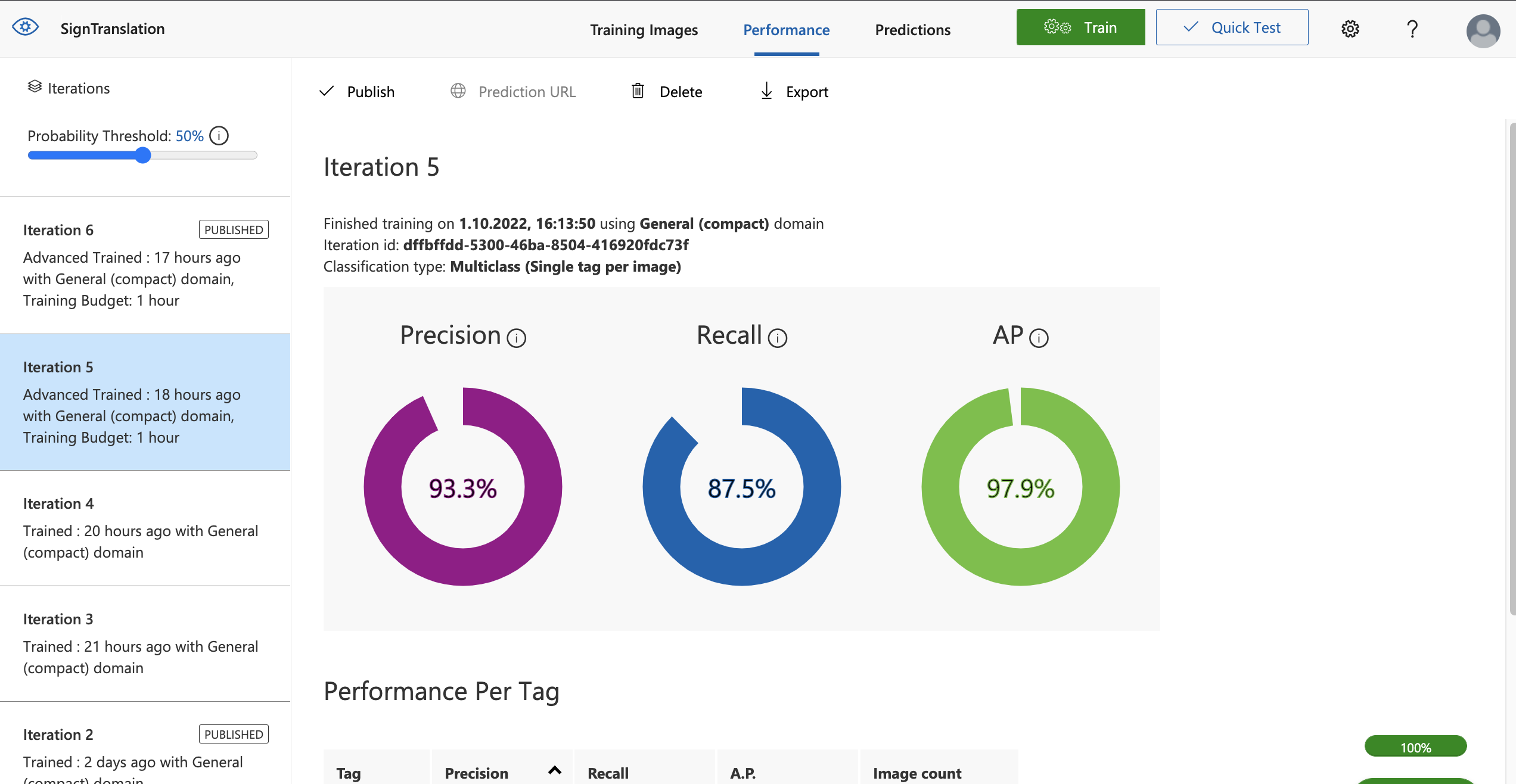
In order to train our Azure Image classifier we created a custom (own!) dataset containing around 100 unique images which we further preprocessed (rotated, cropped,..) to increase robustness. This dataset was given to Azures Custom Vision Service which managed to achieve 100% Accuracy after around 1 hour of training. The whole demo automatically deployed thanks to Netlifys Github commit hooks and can be reached under https://startling-moonbeam-d14aa0.netlify.app/.
Challenges we ran into
How can we record the gestures and poses of people only by having a video stream of it? How can a NN classify exactly the signs of people in a robust way and provide this information as text or speech for non deaf people?
Accomplishments that we're proud of
State-of-the-Art Holistic Pose Estimation Model which provides us the right input images for our classifier. Fully self learning supervised multiclass CNN which can in theory model all the variety of sign languages around the globe with prior robust training.
What we learned
The basics such as connecting our javascript with the Azure API (thanks to the old language Javascript) was often harder than the machine learning part. 3-4 Tech and 1-2 Business people are a great team mixture. Hard work but also had a lot of fun :)
What's next for Microsoft_Weekend Warriors
Making the classifier more robust and provide it with more classes (e.g. the complete Sign language alphabet). Improve the motion capturing of the pose estimation model. All for helping deaf people in their daily life :)
Built With
- 500individiallandmarks
- azureapi
- azurecustomvision
- cnn
- holisticposeestimationmodel
- javascript
- landmarkprediction
- netlifydeployer
- poseestimation
- tensorflowlitemodel


Log in or sign up for Devpost to join the conversation.