Inspiration
The inspiration for MicDrop.ai came from a challenging internship where I was tasked with selling products to strangers. I quickly learned that sales is not just about reading a script; it is a high-pressure balancing act.
I realized that a human salesperson has to do three things simultaneously: listen to the client's emotional state, recall complex context (like prior history or loyalty status), and calculate the perfect price. It is cognitively exhausting. I often found myself focusing so hard on the math that I missed the client's hesitation.
I built MicDrop not to replace the salesperson, but to offload that cognitive burden. I wanted a tool where I could upload a call, provide the context I might have missed in the heat of the moment, and get a mathematically perfect, psychologically optimized proposal instantly.
What it does
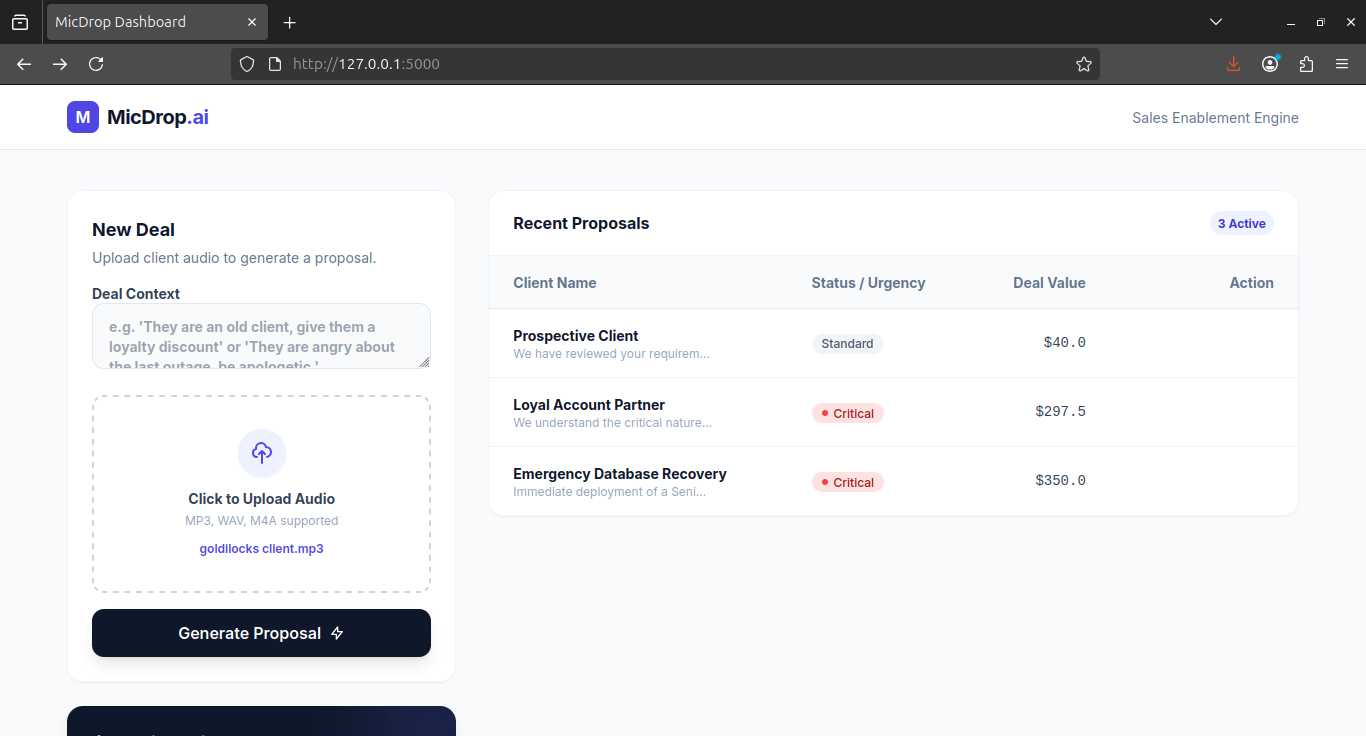
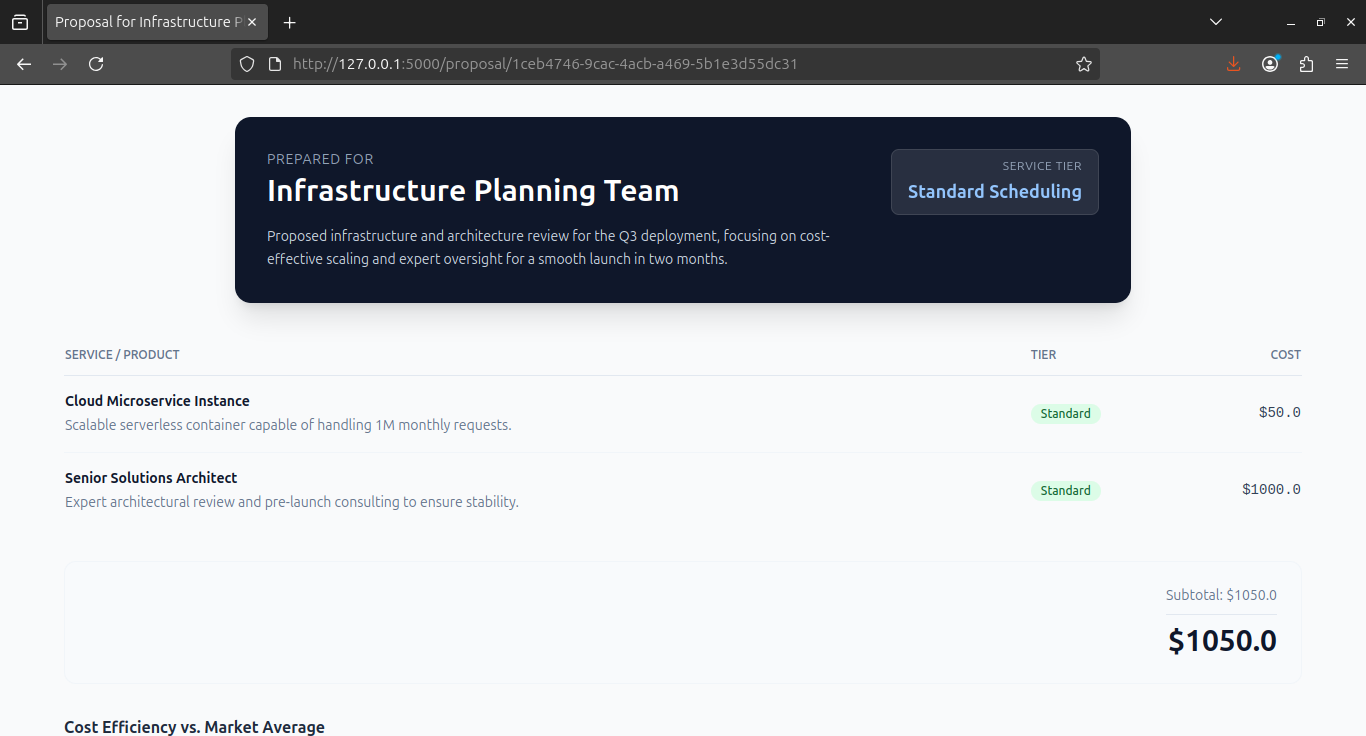
MicDrop.ai is a post-call analysis and pricing engine powered by Gemini 3. It allows sales reps to upload audio files of their conversations along with specific context notes (e.g., "This client is at risk of churning").
- It Analyzes Tone: It listens to the raw audio to detect urgency signals—distinguishing between a panicked "Server Down" emergency and a casual "Q3 Planning" discussion.
- It Integrates Context: It takes the user-provided context (which a generic model wouldn't know) and fuses it with the audio insights.
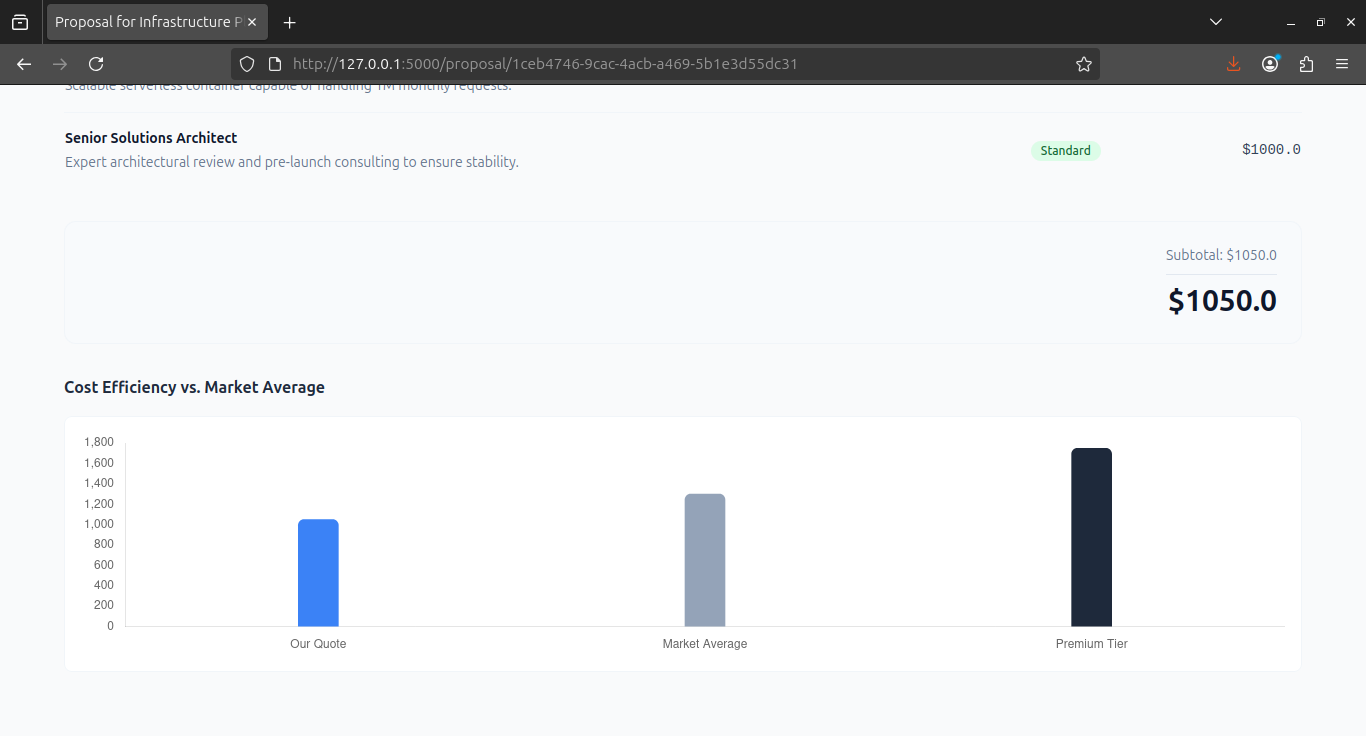
- It Optimizes Revenue: It generates a structured proposal where the pricing strategy is automatically adjusted—applying "Loyalty Discounts" or "Urgency Premiums"—ensuring the rep never leaves money on the table.
How we built it
The project is built on a Python (Flask) backend with a Tailwind CSS frontend.
The most critical technical decision was the architecture of the AI pipeline. Initially, I built a traditional workflow: using a Speech-to-Text model to transcribe the audio, and then feeding that text into an LLM.
However, I realized this approach lost the most valuable data: the tonality. A transcript reads "I need this now" the same way whether it's said calmly or screaming.
I scrapped that architecture and switched to Gemini 3’s native multimodal audio capabilities. By feeding raw audio tokens directly into the model, MicDrop captures the nuance of the conversation that text-only models miss.
Challenges we ran into
The biggest technical hurdle was "The Hallucination of Quantity."
In early tests, the AI would hear a client say "I need help" and arbitrarily guess that meant "8 hours" of consulting, while other times it assumed "1 hour." This made the final pricing unreliable.
I solved this by implementing strict Schema Validation (using Pydantic) and a hard-coded "Default=1" rule in the system prompt. This forced the AI to be conservative with its assumptions—defaulting to a single unit unless the audio explicitly stated a duration—ensuring the math remained consistent and accurate every time.

Log in or sign up for Devpost to join the conversation.