-
-
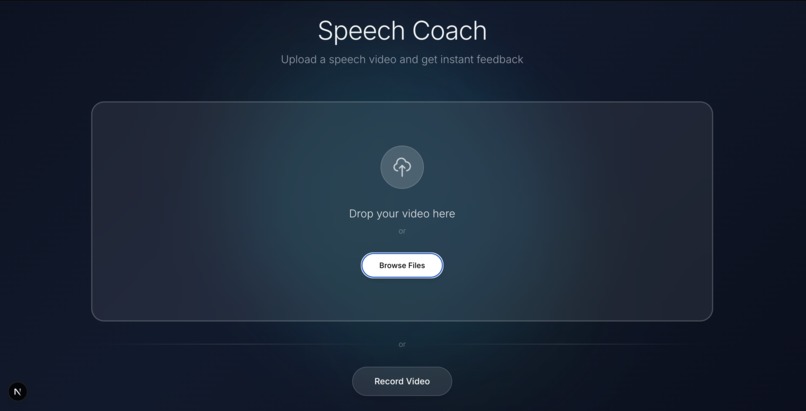
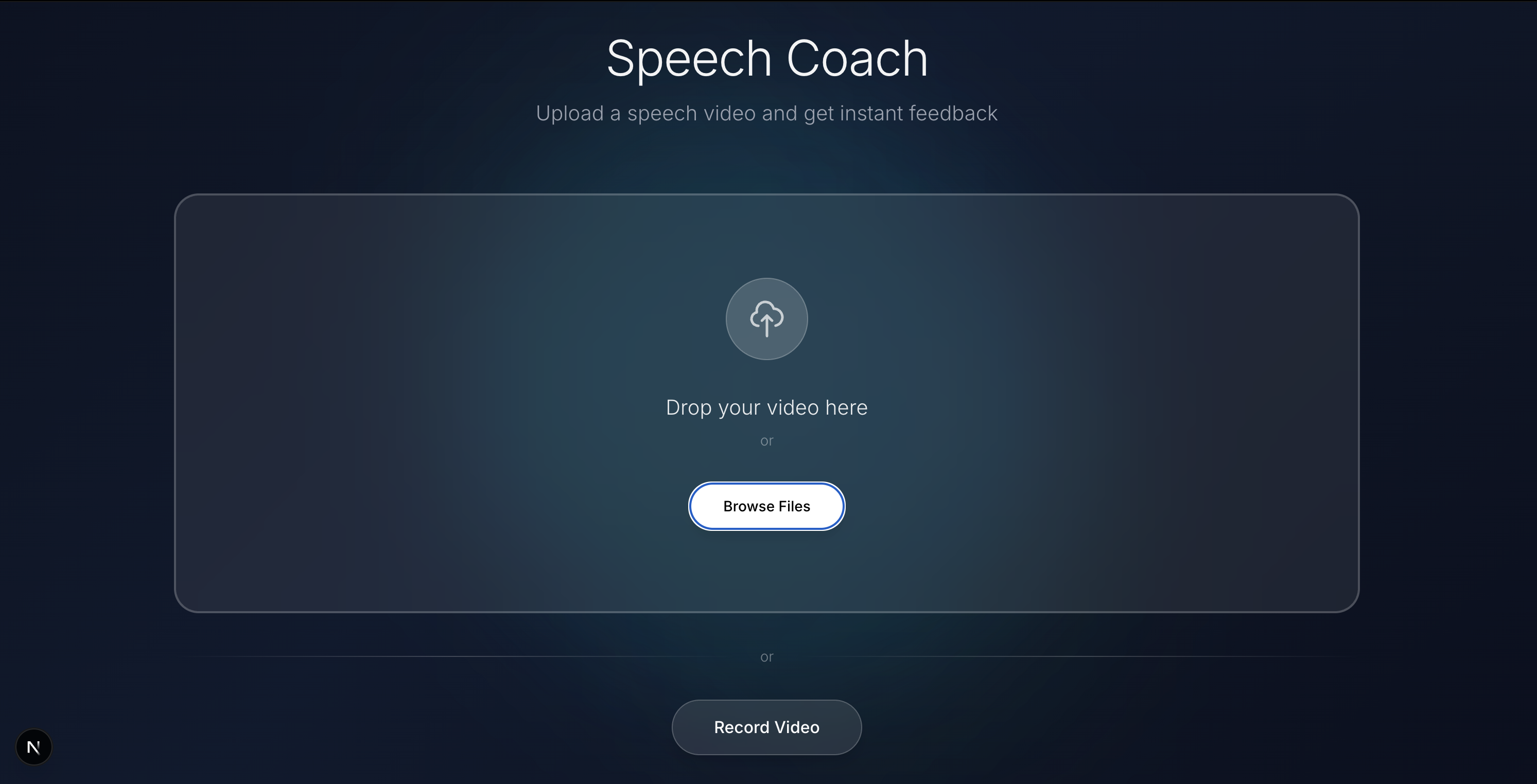
Upload page
-
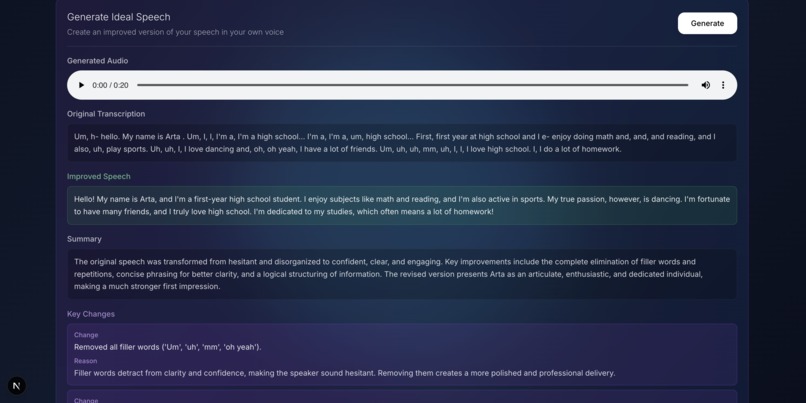
Video replay with timestamps
-
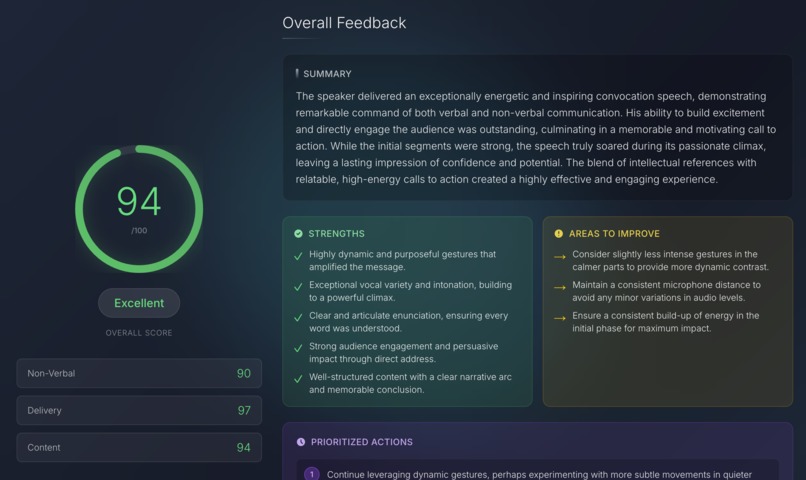
Analysis page
-

Strength analysis
-
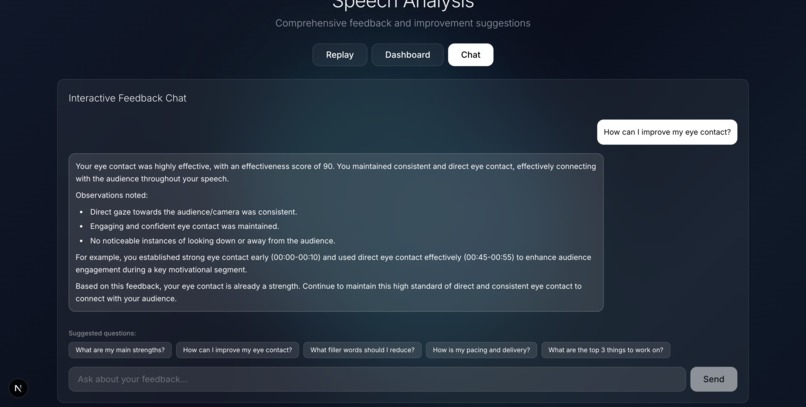
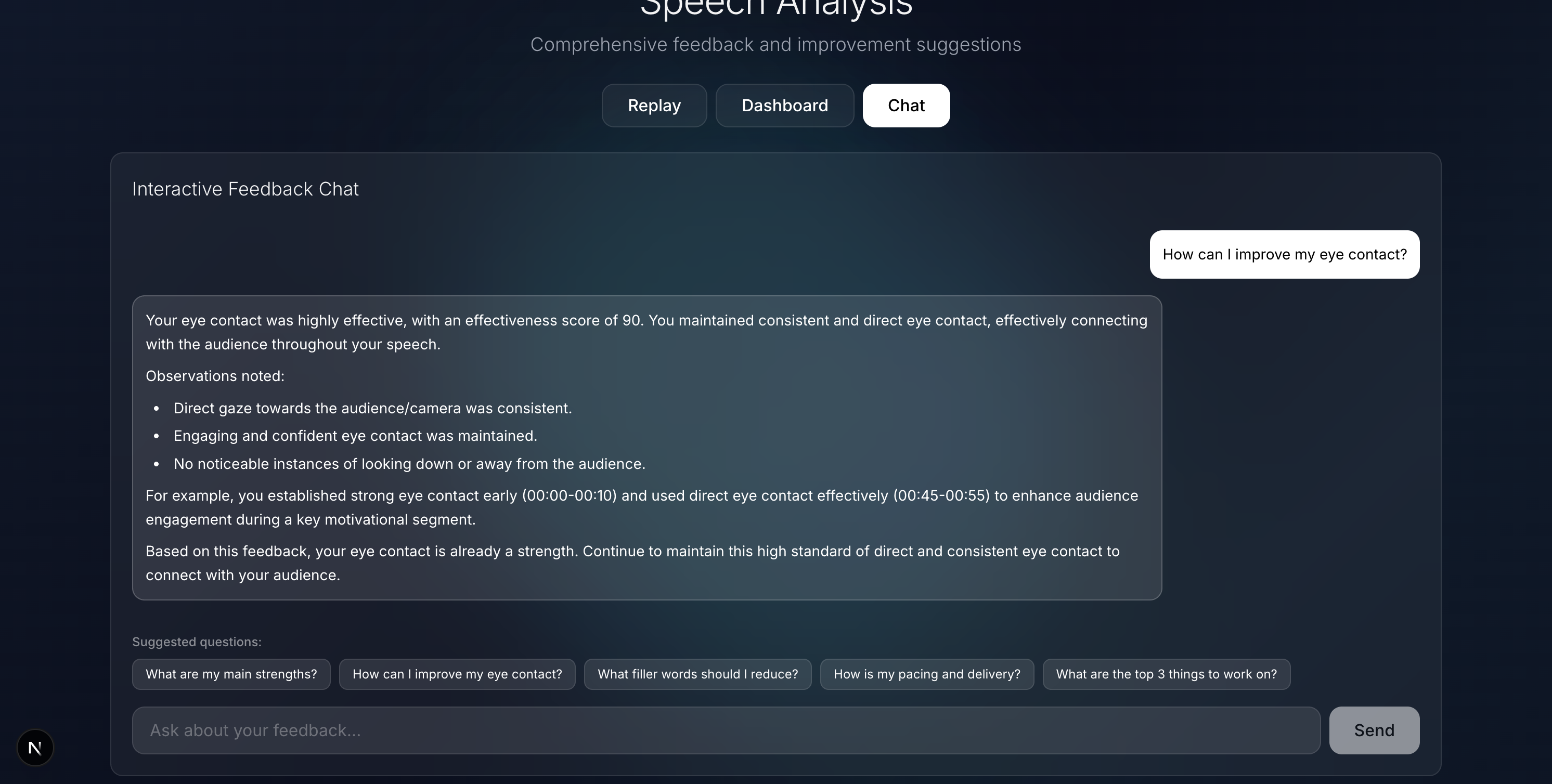
Chat with AI


Inspiration
Public speaking is one of the most valuable yet anxiety-inducing skills. Many people practice speeches alone without knowing how they appear or sound — missing out on feedback that could dramatically improve their delivery. We wanted to build MicDrop, a friendly AI speech coach that gives everyone access to professional-level feedback on how they speak, move, and engage an audience. Our goal: make communication coaching as accessible as running a spell check.
What it does
MicDrop analyzes your entire presentation — from your voice to your body language — and gives actionable, timestamped feedback.
It evaluates:
- 👀 Non-verbal cues: eye contact, gestures, and posture
- 🎙️ Delivery: clarity, enunciation, intonation, and filler word control
- 💬 Content: organization, persuasiveness, and clarity of message
After analysis, MicDrop:
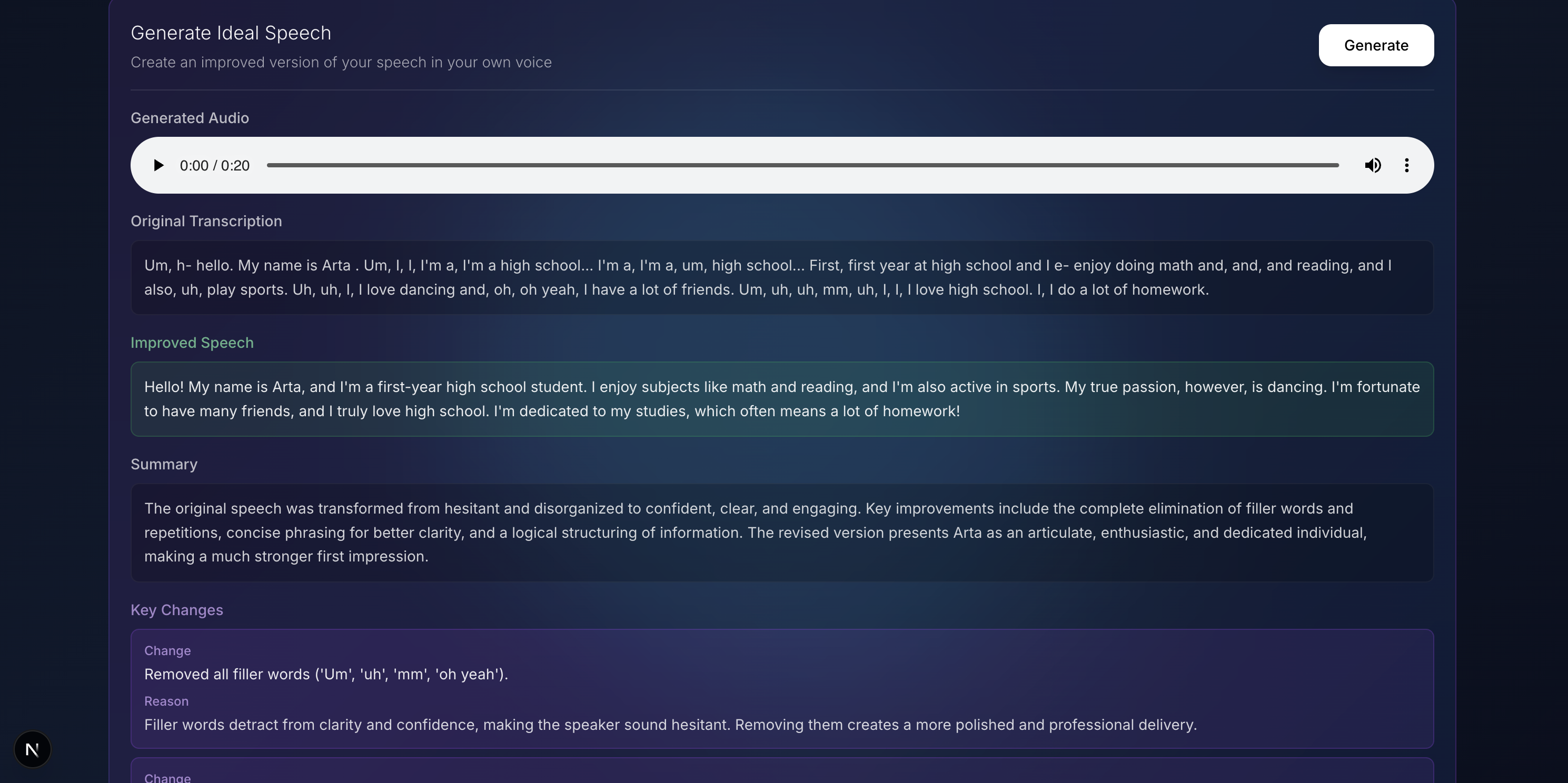
- Generates section-specific insights linked to video timestamps
- Provides overall scores and detailed feedback across categories
- Replays key moments with annotated tips
- Suggests improved speech phrasing and text, audio, and video ideal exemplars in 74 languages using AI-generated voice and video delivery
How we built it
We combined Gemini API and ElevenLabs to create a multi-layer AI feedback system:
- Frontend (UI/UX): Captures user video and manages uploads
- Backend: Handles video/audio processing and data flow
- Gemini API: Performs gesture, posture, eye contact, and overall communication feedback
- ElevenLabs API: Transcribes speech, identifies filler words, and provides voice cloning for improved delivery examples
- Integration: Gemini generates section-specific timestamps and detailed reports → ElevenLabs refines intonation → results visualized through our output dashboard
Each analysis phase feeds into a structured JSON schema, ensuring consistent, interpretable data across categories.
Challenges we ran into
- Synchronizing multimodal analysis (audio + video) while maintaining accuracy and speed
- Creating timestamp-level alignment between gestures and speech content
- Designing a universal JSON schema that’s both human-readable and machine-parseable
- Integrating APIs that have different latency and output formats
- Making feedback constructive, not robotic, so users feel encouraged, not judged
Accomplishments that we're proud of
- Built a fully functional AI-driven feedback system that integrates both visual and auditory cues
- Designed a granular timestamp-based feedback structure for precise user improvement
- Created realistic exemplar speeches using voice cloning — allowing users to hear and see their improved versions
- Established a scalable architecture ready for future LLM and emotion-detection integrations
What we learned
- Multimodal AI (voice + video) requires careful synchronization and data cleaning
- Human-like feedback depends on tone, phrasing, and emotional context — not just metrics
- Real users appreciate actionable and encouraging feedback more than numerical scores
- Developing transparent and ethical AI coaching systems builds long-term trust
What's next for MicDrop
- Add real-time feedback mode during live rehearsals
- Incorporate gesture heatmaps and eye-contact tracking overlays
- Build customized training modules (e.g., “Pitch like a founder,” “Ace your interview”)
- Expand support for multilingual speech coaching
- Integrate with platforms like Zoom or Google Meet for instant post-meeting feedback
✨ MicDrop empowers everyone to own their stage — one confident speech at a time.





Log in or sign up for Devpost to join the conversation.