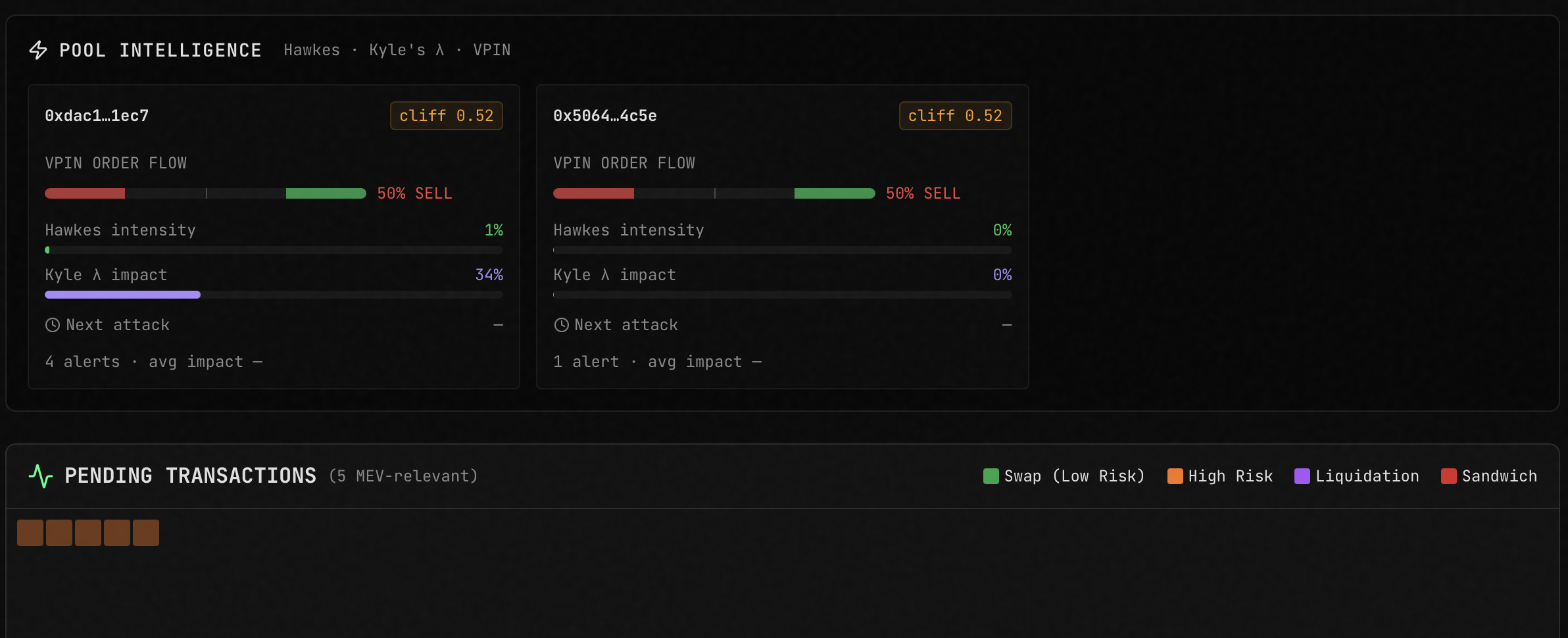
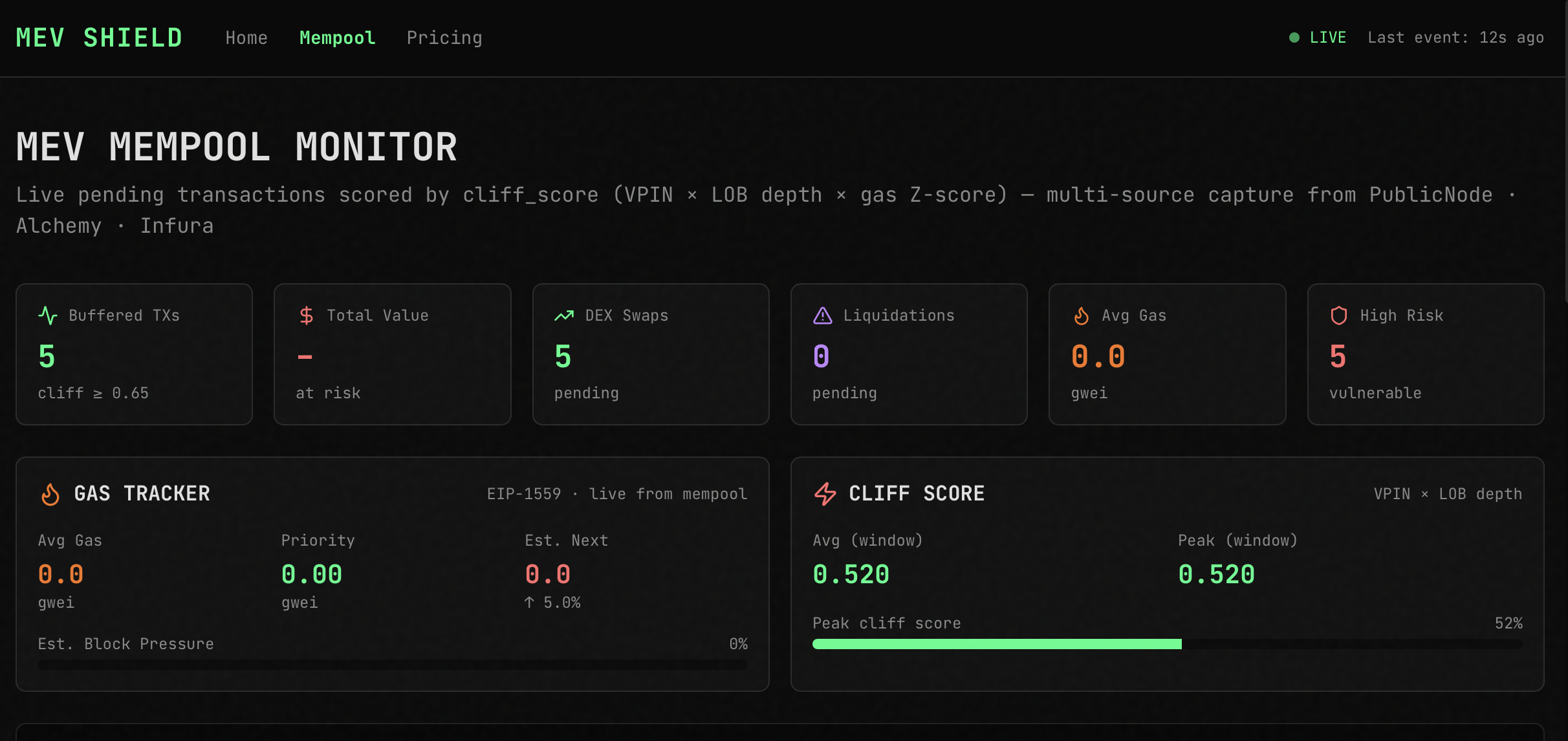
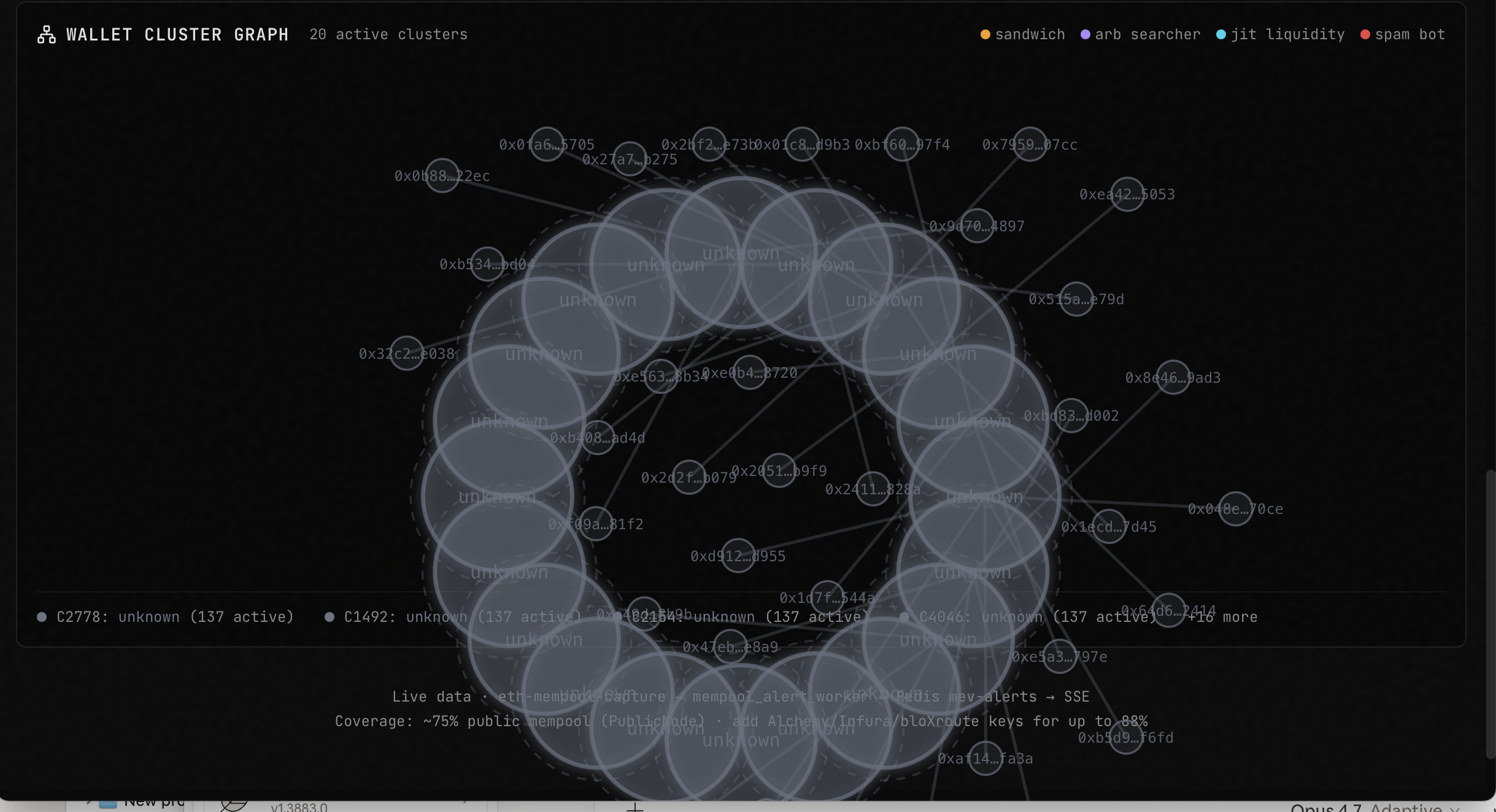
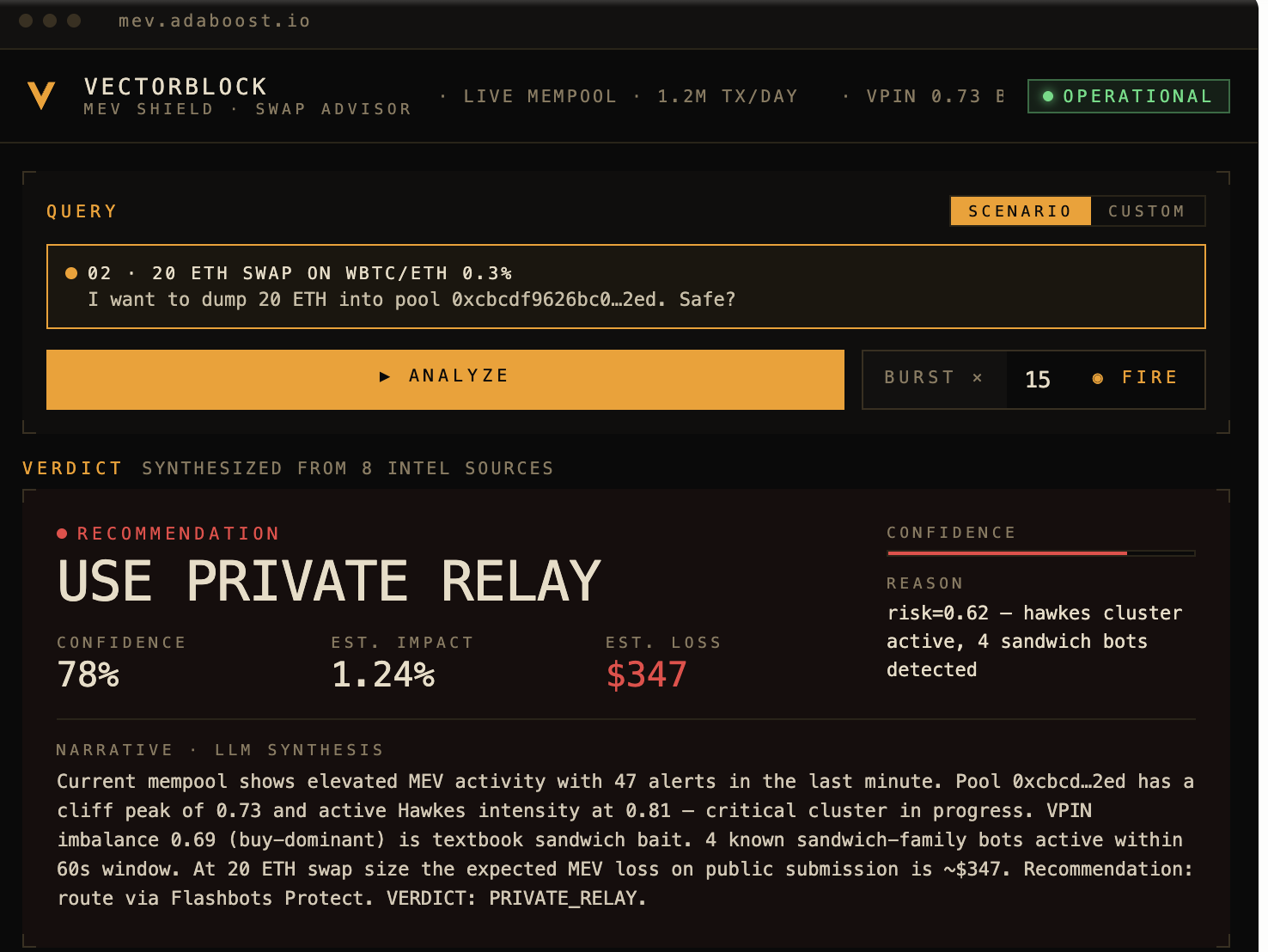
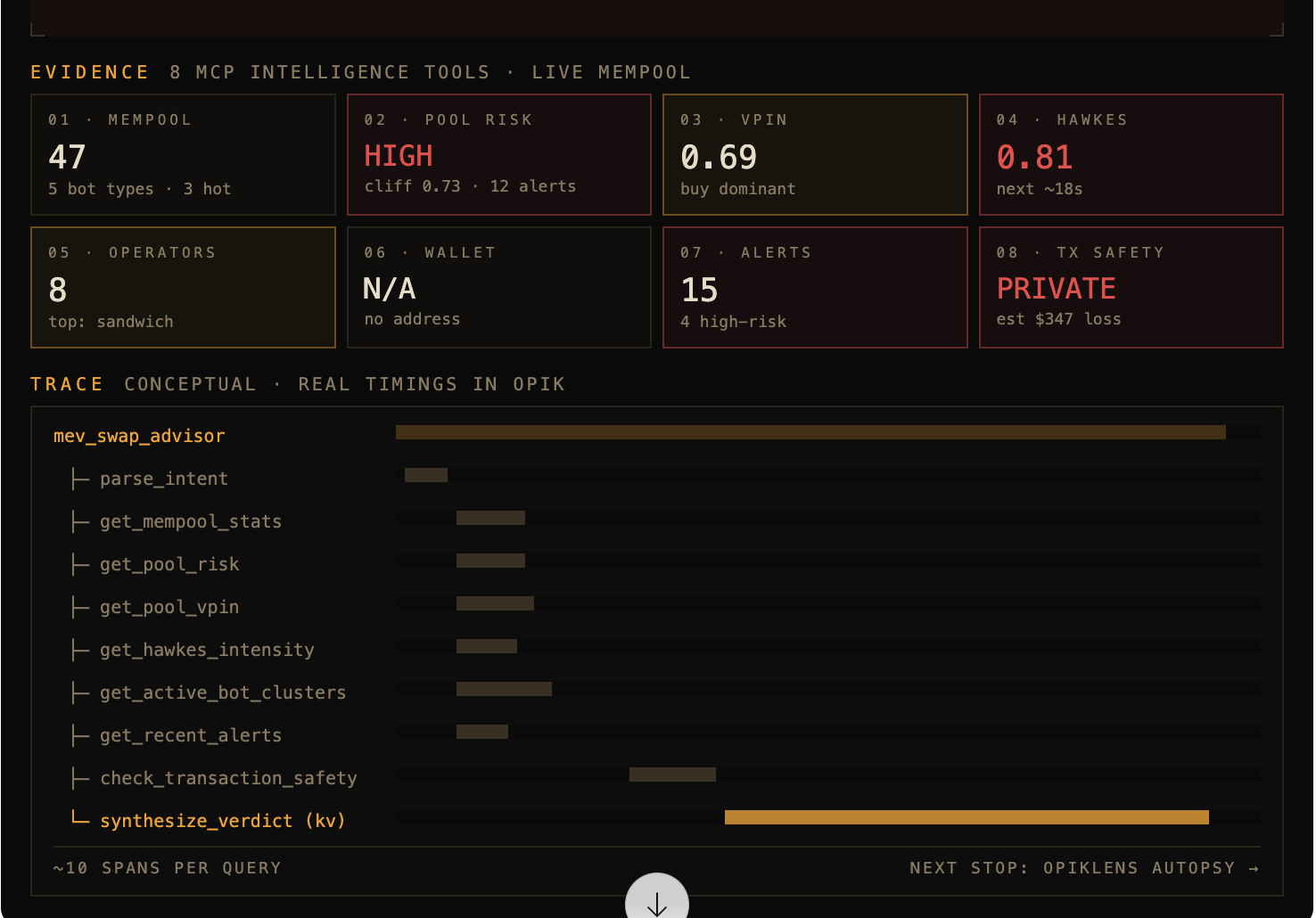
InspirationEvery DEX trader pays a hidden MEV tax — 50 to 150 basis points on volatile pairs, silently extracted by sandwich bots in the public mempool. Today, avoiding it requires deep mempool analytics, bot taxonomy, and Hawkes-process modeling — all behind institutional paywalls. We wanted to put that intelligence in an agent anyone can ask: "Should I route this swap publicly, or through Flashbots?"What it doesMEV Swap Advisor analyzes live Ethereum mempool data and recommends whether to submit a swap publicly or through a private relay. A user asks a natural-language question — "Swap 20 ETH on pool 0xcbcd...2ed, safe?" — and the agent calls 8 MCP intelligence tools in parallel against our live mempool index: pool risk scoring, VPIN order-flow toxicity, Hawkes intensity, active bot clusters, wallet reputation, and transaction safety simulation. An LLM synthesizes the evidence into a single verdict — PRIVATE_RELAY or PUBLIC_OK — with a confidence score and estimated MEV loss in USD. Every step is traced in Opik, so you can see exactly how the agent reached its conclusion.How we built itThe stack is three tiers connected over a shared Docker network:Intelligence layer. An Ethereum mempool capture pipeline streams raw pending transactions into Redis and Neo4j, building a real-time index of pool activity, bot clusters, and risk signals. This feeds an MCP server that exposes 8 tools over SSE.Agent layer. A FastAPI service consumes all 8 MCP tools via a short-lived SSE client session per request. It runs an intent-parsing step, 6 parallel tool calls, 2 sequential ones, and a final LLM synthesis. Every call is wrapped with Opik's @track decorator, producing ~10 spans per query under one parent trace. Inference runs on a local llama.cpp server, giving us full control over the model and zero external API costs.Presentation layer. A single-file React frontend served by nginx, proxying /api/* to the agent. Terminal-aesthetic design — dark charcoal, amber accents, corner brackets — to signal "production financial tool" rather than "AI demo." A burst mode fires N concurrent analyses to stress the inference backend while the observability layer records everything.Challenges we ran into Dependency conflicts. Our initial pins had fastapi==0.115.0 requiring starlette<0.39, while mcp==1.1.0 required starlette>=0.39. Unresolvable. Bumped both to newer versions. Custom llama.cpp patches going stale. Our llama.cpp build used three custom patches written months earlier against a specific commit. Upstream had refactored server.cpp extensively; patches no longer applied. We removed the custom telemetry patches and ran plain upstream llama.cpp — keeping /slots, /metrics, and /v1/*, which is everything our demo actually needed. Shared-library linking inside the runtime image. libllama.so was present as libllama.so.1 but the binary looked for the unversioned name. Wrote a bidirectional symlink loop so either direction works. Port collisions. Our inference server defaulted to :8080, which was already bound by an unrelated service. Remapped to :8096. MCP session lifecycle. Persistent SSE sessions across asyncio request boundaries are fragile. Chose a short-lived session per request — 100ms overhead in exchange for reliability. Accomplishments that we're proud of A working end-to-end agent that calls real on-chain intelligence, not mocked data. Every trace is backed by actual Ethereum mempool activity. Rich Opik trace granularity: 10 spans per query (1 parent + 2 LLM calls + 8 tool calls), with visible parallelism in the timeline. This is the kind of trace data that makes observability actually useful. A frontend that looks like a product, not a hackathon project. Judges remember what they saw. Burst mode: one button fires 15 concurrent analyses and drives the inference backend into slot contention, making the observability story tangible rather than abstract. What we learned Separation of concerns pays off under time pressure. Keeping the mempool intelligence, inference, agent, and UI as independent containers connected by a shared Docker network meant that when any one piece broke, we could fix it in isolation. If we had merged them into a monolith, the custom-patch failure would have blocked the whole demo. Observability is a UX feature, not a debugging tool. Once we had Opik traces visible, we caught three bugs in the agent's tool-call ordering that would have been invisible otherwise. The trace view became our primary debugging interface. Regex before LLM is underrated. The intent-parsing step has a regex pre-pass that handles 90% of queries without touching the model. That's 90% of queries with zero token cost and millisecond latency. Patch-based build pipelines age badly. Upstream projects move; patches rot. Where possible, use upstream as-is. What's next for mev-swap-advisor OpikLens. A correlator service that joins Opik traces with llama.cpp KV-cache telemetry by timestamp, so any slow trace can be auto-diagnosed: "Your p99 spike happened because KV was at 87%, fragmentation 43%, 4 concurrent prefill-heavy requests." A Hawkes-process predictor projects next saturation event. Live on-chain integration. Replace pool analytics mocks with direct queries against our existing Vectorblock Vertica store of 20+ years of microstructure data. Streaming verdicts. Move the synthesis step to token-level streaming so users see the verdict forming in real time instead of waiting 5-8s. explain_slow_trace MCP tool. One new tool in our existing MCP bridge, callable from Claude Desktop: "Why was my last agent call slow?" → Claude returns the autopsy conversationally. Autonomous monitoring mode. An agent that polls pool risk continuously and emits alerts when cliff_score crosses a threshold, so users don't have to ask — they get notified.
Built With
- claude
- claude-desktop
- clickhouse
- cloudflare
- cloudflared
- css
- cypher
- docker
- fastapi
- fastmcp
- html
- huggingface
- javascript
- lambda-labs
- linux
- llama.cpp
- mcp
- neo4j
- nginx
- opik
- pydantic
- python
- react
- redis
- sql
- tailwindcss
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.