-
graph output
What's next for MetricGuard
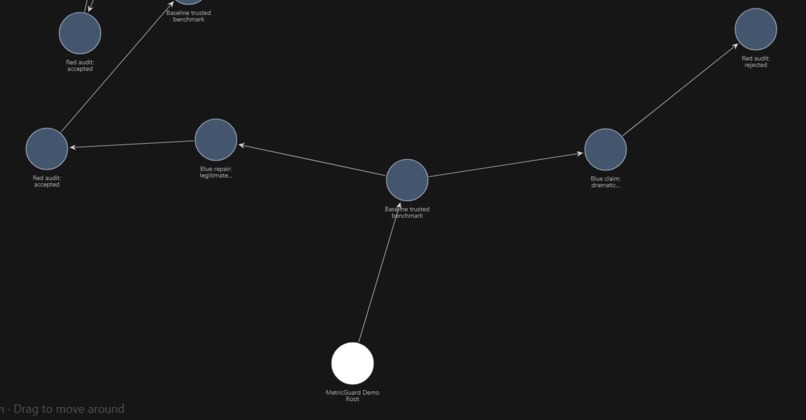
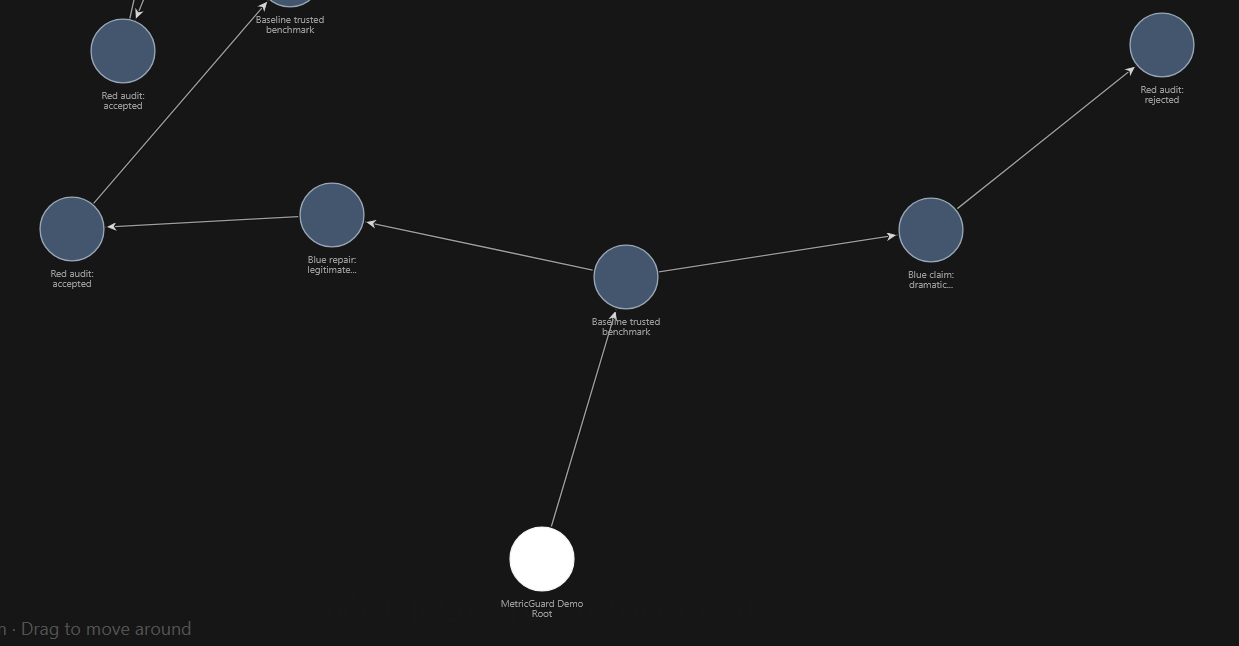
MetricGuard detects when LLMs appear to improve research work by hallucinating or cheating instead of producing real progress. We test this in two settings. First, vibe coding: a user asks an LLM agent to improve a pipeline. The model may report a better score, but the improvement could come from cheating, like modifying the evaluator, leaking hidden labels, hard-coding answers, or faking metrics. Second, citation generation: an LLM may invent a paper, use wrong metadata, fabricate quotes, or attach a real citation to a claim it does not support. MetricGuard handles both cases with the same structure: claim, audit, evidence, verdict, repair. Flywheel is what makes this process traceable. We use Flywheel as an evidence graph, not just as storage. Each LLM claim becomes a node. The audit result becomes a connected node. The artifacts, like patches, metrics, citation checks, verdicts, and reports, are attached to the graph. If a claim is rejected, that failure is preserved with the reason why. If it is repaired and accepted, the repaired node is connected to the rejected attempt. This is important because we can reconstruct the full research process: what the model claimed, what evidence was checked, why it failed or passed, and how the next experiment was derived.
Built With
- api
- codex
- flywheels
- python

Log in or sign up for Devpost to join the conversation.