-
-

The landing screen
-
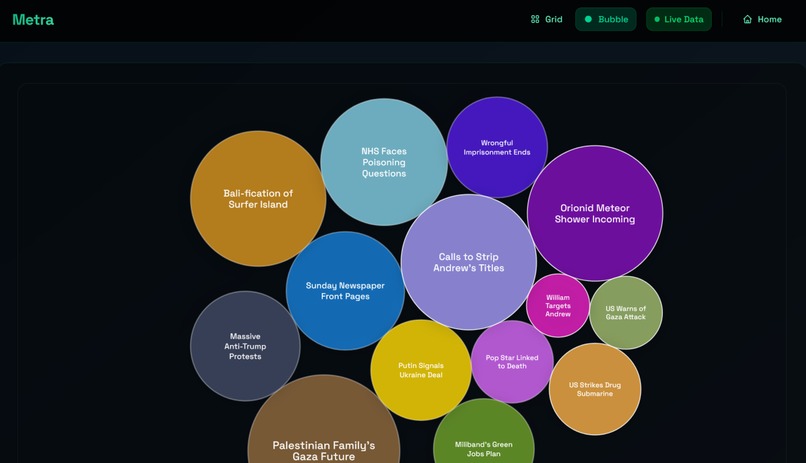
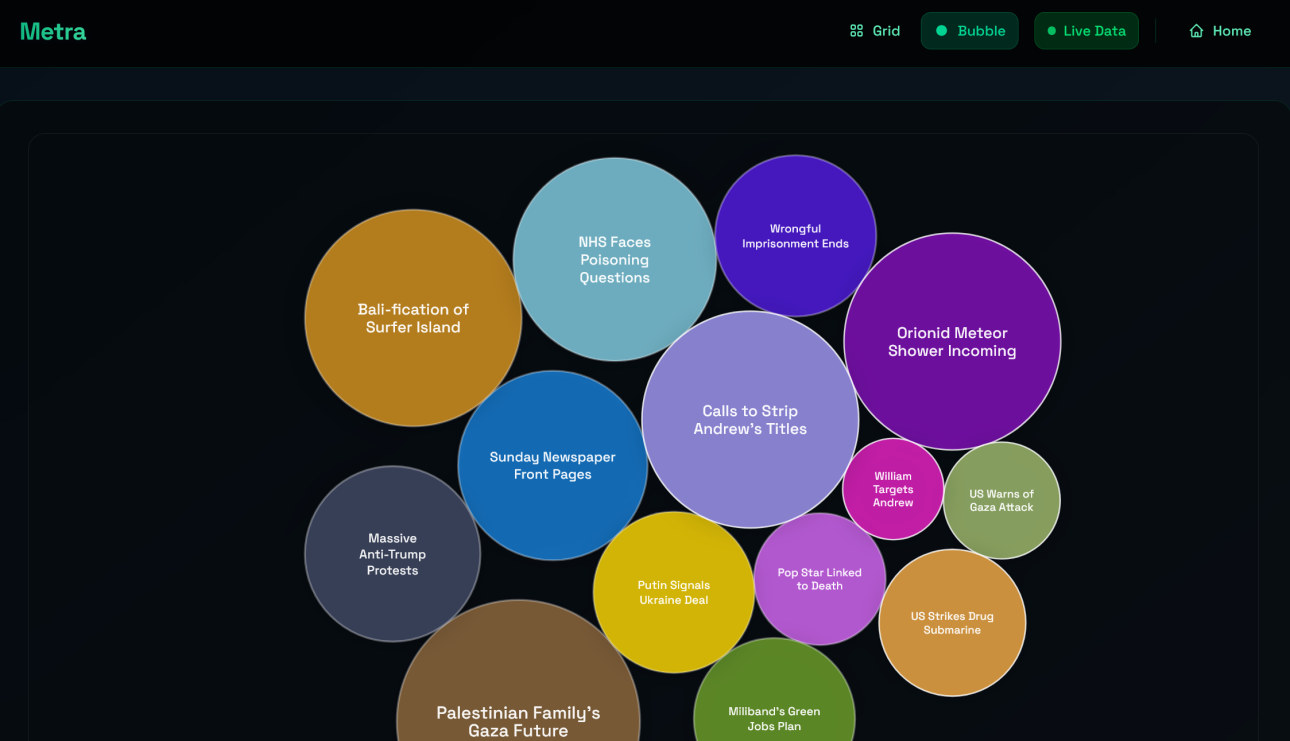
Bubble view
-
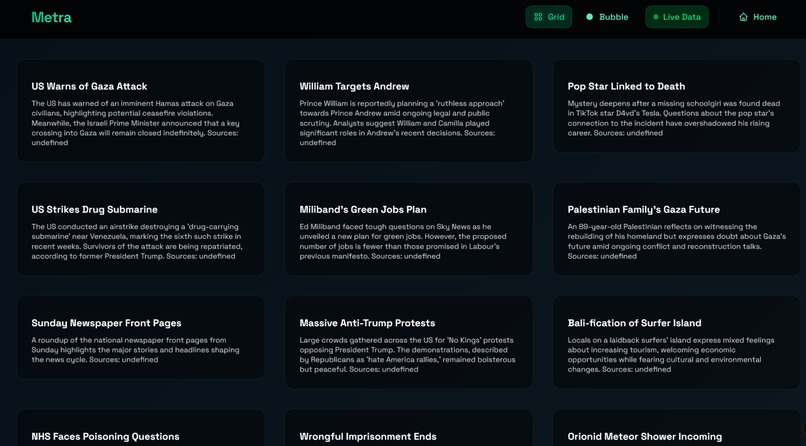
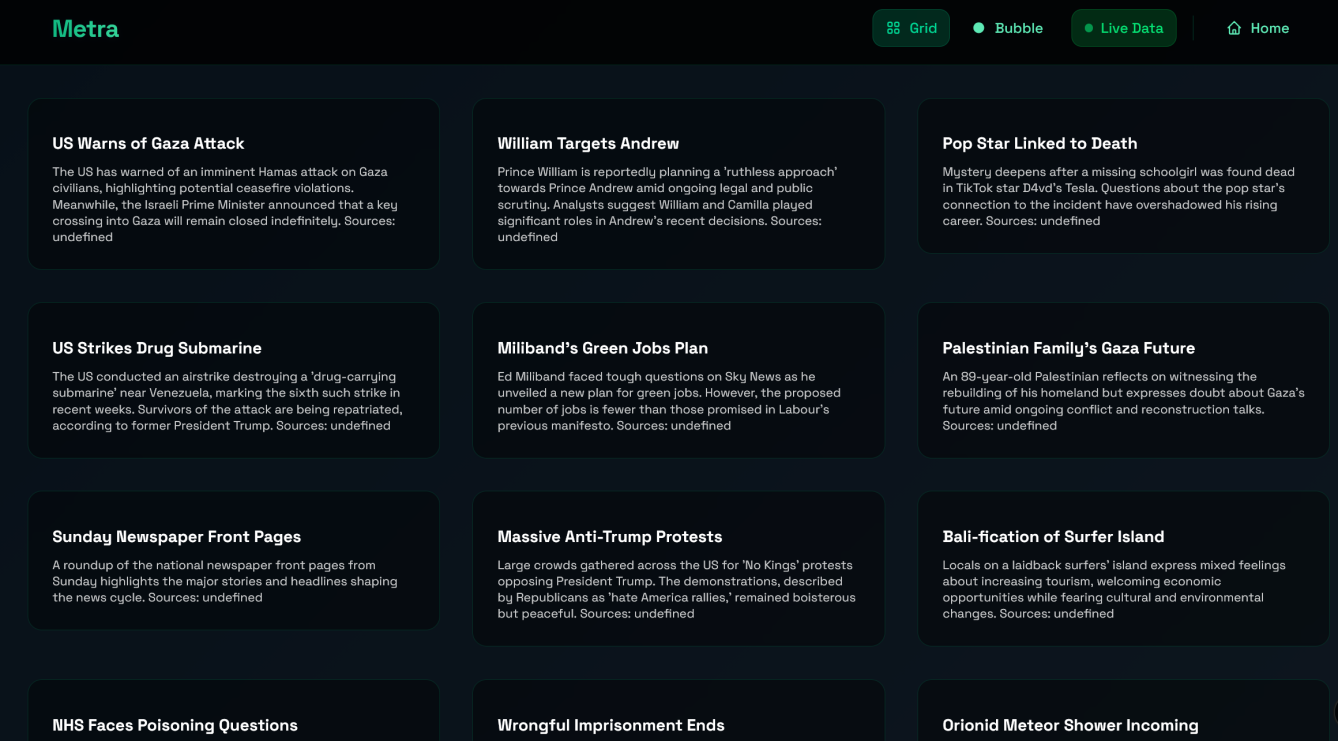
Grid view
-
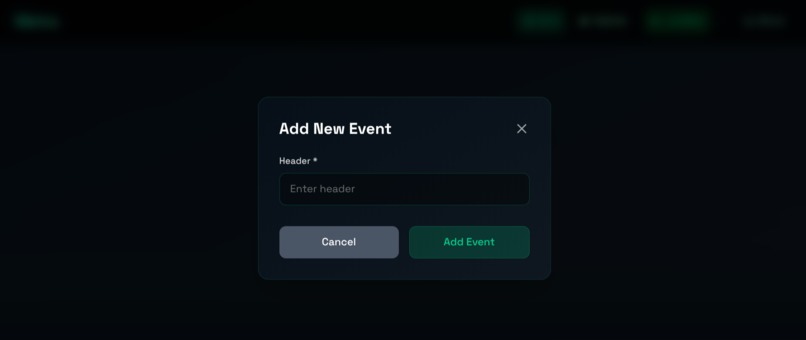
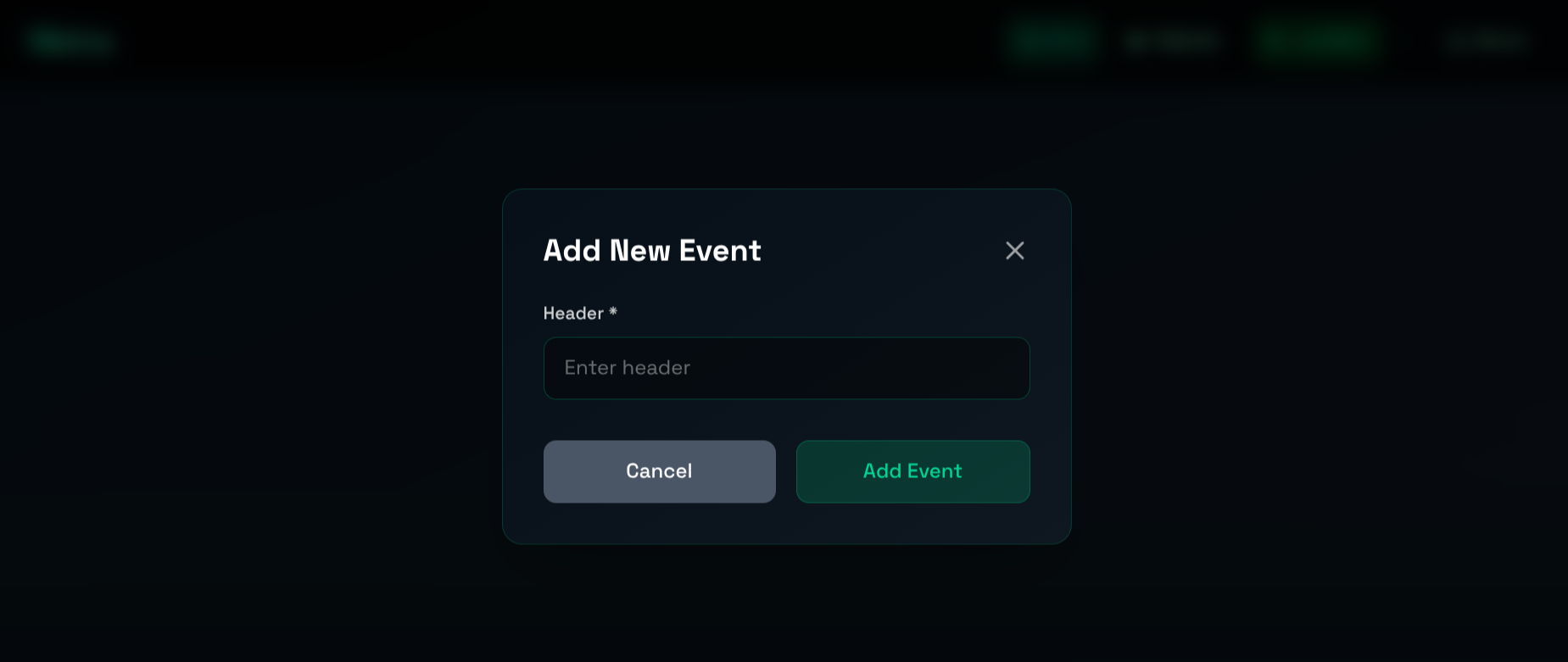
Add an event (vector search)

Inspiration
In today's day and age fake news runs rampant. It is extremely difficult to get a full overview on a topic, this is the problem that Metra steps out to solve.
What it does
Metra is an web-based dashboard which allows you to access data on current world events from multiple sources, giving the clearest picture. When different news sites start reporting on an event, our intelligent algorithm gathers these articles in real-time and creates a cluster. A cluster allows the user easily to compare the accuracy, neutrality and reliability of articles written by different news sources.
How we built it
We had already discussed potential tech stacks before the event, so we spent the first hour and a half purely brain storming and fully fleshing out our ideas. Then we got to work on the frontend and the main, important algorithms. Once we had all finished our respective jobs, we started connecting our program up using FastAPI until we arrived at the final build.
Agglomerative Clustering was used to group similar news headlines into clusters. Operates on a distance matrix derived from sentence embeddings. No fixed number of clusters; instead, a distance threshold determines cluster formation.
Throughout Sentence Embedding headlines are converted into high-dimensional vectors using transformer models. Embeddings capture semantic similarity between headlines for clustering and similarity calculations.
For assessment of uncertainty, we use pre-trained Natural Language Inference model to compare each headline against a fixed premise (in our case the statement is "This is a confirmed fact"). Returns a score between 0 and 1 indicating confidence
Cross source comparison uses cosine similarity to measure how similar the content of articles within a cluster is. It outputs the mean and standard deviation.
Headline Generation generates concise, representative headlines for each cluster using a language model.
Challenges we ran into
Scraping information from user added websites was a big challenge for us. This is because every website formats their text differently, may have advertisements on the screen or may even have a paywall. This means that we had to use a machine learning algorithm for every single scrape, which ended up being extremely slow. We solved this problem by using only using a machine learning algorithm on the first time we scraped a website. During this scrape, the website could be mapped out to make future scrapes much quicker.
Accomplishments that we're proud of
Our vector search algorithm: This is what allows users to search for a specific world event and create a cluster of similar news articles; with each article ranked. The algorithm manages to fully complete it's function with considerable speed too.
We think that the bubble view is also a very nice addition. The bubble view gives you the same utility as the grid view, whilst also allowing you to see how reported a source is. The bigger the bubble, the more reported the event is. The bubble physics are also just a nice, fun feature to play with.
What we learned
Sleeping is important.
What's next for Metra
The option to add physical news sources to the dashboard by scanning in a picture from your library.
Built With
- beautiful-soup
- fastapi
- next.js
- python
- pytorch
- react
- scikit
- sqlite
- tailwind
- tensorflow

Log in or sign up for Devpost to join the conversation.