-
-
training curves
TL;DR:
We optimize data selection by calculating the gradient of eval loss wrt each data example. Taking metagradients is notoriously expensive, so to do this cheaply, we:
- Write our own custom ThunderKittens kernels for taking meta-gradients
- Train an auxiliary model to approximate a metagradient given a data example
We were inspired by the following papers:
- Synthetic Data for any Differentiable Target (Thrush et al., 2026)
- Optimizing ML Training with Metagradient Descent (Engstrom et al., 2025)
- Scalable Meta-Learning via Mixed-Mode Differentiation (Kemaev et al., 2025)
- Improving Pretraining Data Using Perplexity Correlations (Thrush et al., 2025)
- Datamodels: Predicting Predictions from Training Data (Ilyas et al., 2022)
Systems Optimizations
We needed finer-grained control over Hopper than naive JAX/Pallas exposes — the latter is occupancy-bound and naive autodiff OOMs by seq 32k. So we hand-wrote the primitive (the double-backward of causal attention) in ThunderKittens: warp-specialized, with TMA memory loads, wgmma (hopper mma instructions), bf16-in/fp32-accum. This makes the op much faster for 1.64× end-to-end over Pallas/Triton.
Setup
Our corpus is a mix of three datasets:
- "on-target": PubMed (biomedical abstracts)
- "off-target": C4 (common crawl/web data)
- "corrupt": PubMed but we randomly scrambled token sequences
Our downstream metric is loss/perplexity on held-out PubMed. We'd expect our method to correctly select the "on-target" data.
Results
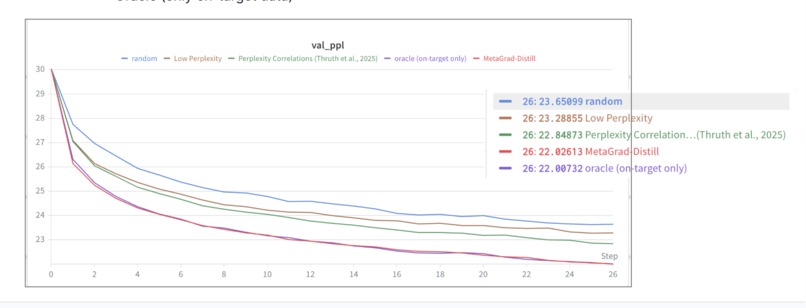
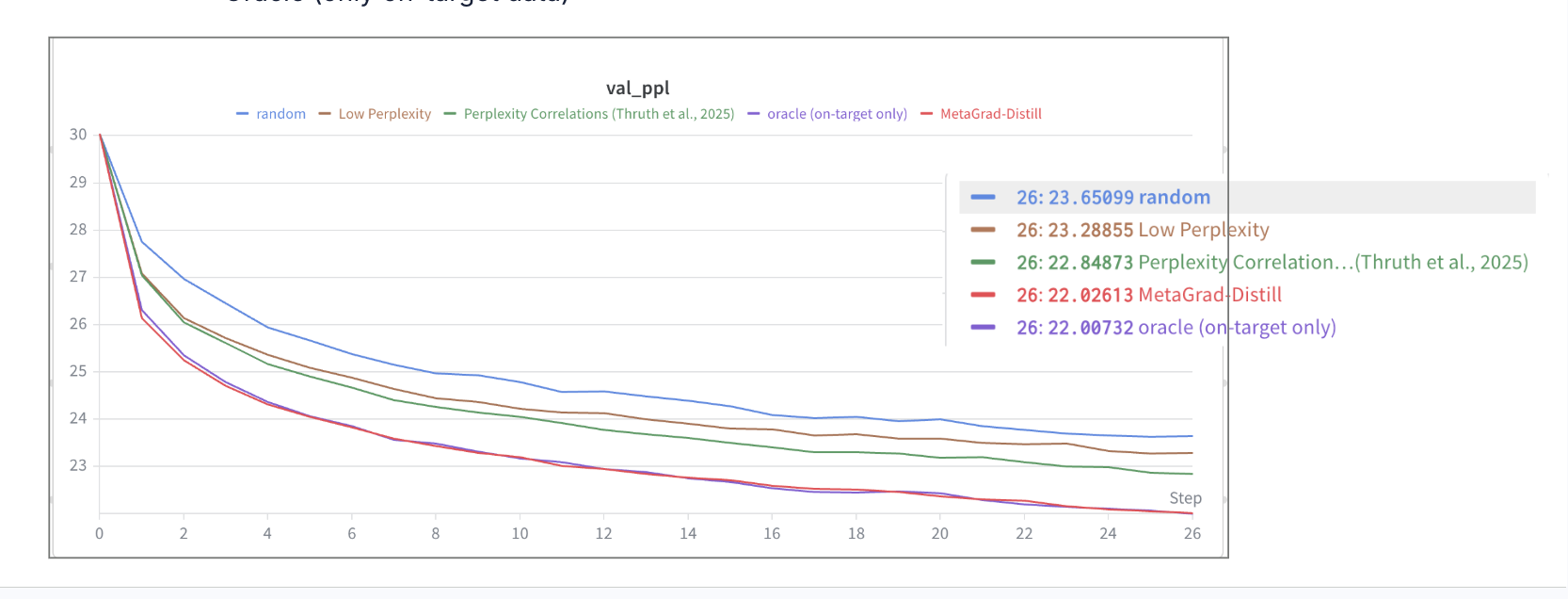
We evaluate on the following baselines: 1) Random selection of data 2) Low-perplexity filtering of data 3) Perplexity Correlations (Thrush et al., 2025) 4) Oracle (only train on on-target data)
We beat 1-3 and pretty much match the oracle, showing our method is extremely effective at selecting data. See our video presentation for Wandb plots :)
Novelty + Insights
Most data-attribution work treats the metagradient as the end product; our insight is to use it as a teacher, distilling an expensive, near-oracle data-quality signal into a cheap, reusable score to avoid this expensive cost. We show that we can leverage the insights of metagrads on a small scale to then model the decisions that metagrads would make with a cheap classifier and apply those decisions across an entire corpus, even to data the oracle never scored, for the cost of a single forward pass.
Impact + Trajectory
Lots of people have tried data attribution—seeing if we can attribute model behavior to specific data examples. Metagradients are, in theory, the exact mathematical signal we want. The problem is we have to differentiate through an entire run of continued pre-training which is extremely expensive. Our contributions address this.
In the wild there are no data domains, so there's no way to tell if, given an eval metric, if a data example was "on target" or "off target." If MetaGrad-Distill scales, we can apply this to find filter data without any human heuristic!
Built With
- jax
- thunderkittens


Log in or sign up for Devpost to join the conversation.