-
-

Landing Page of Meta Harness
-
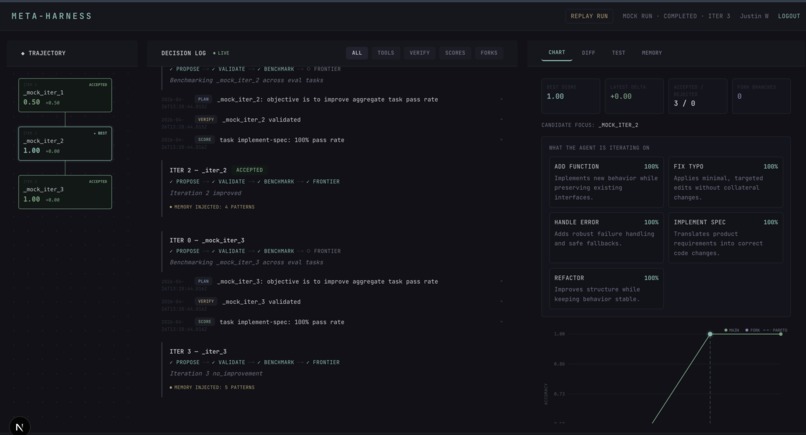
Sentry/Datadog Observability Layer for Harness Improvements by LLM
-
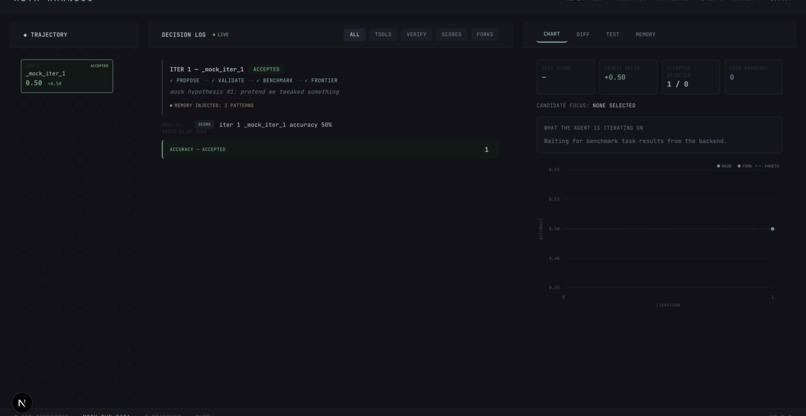
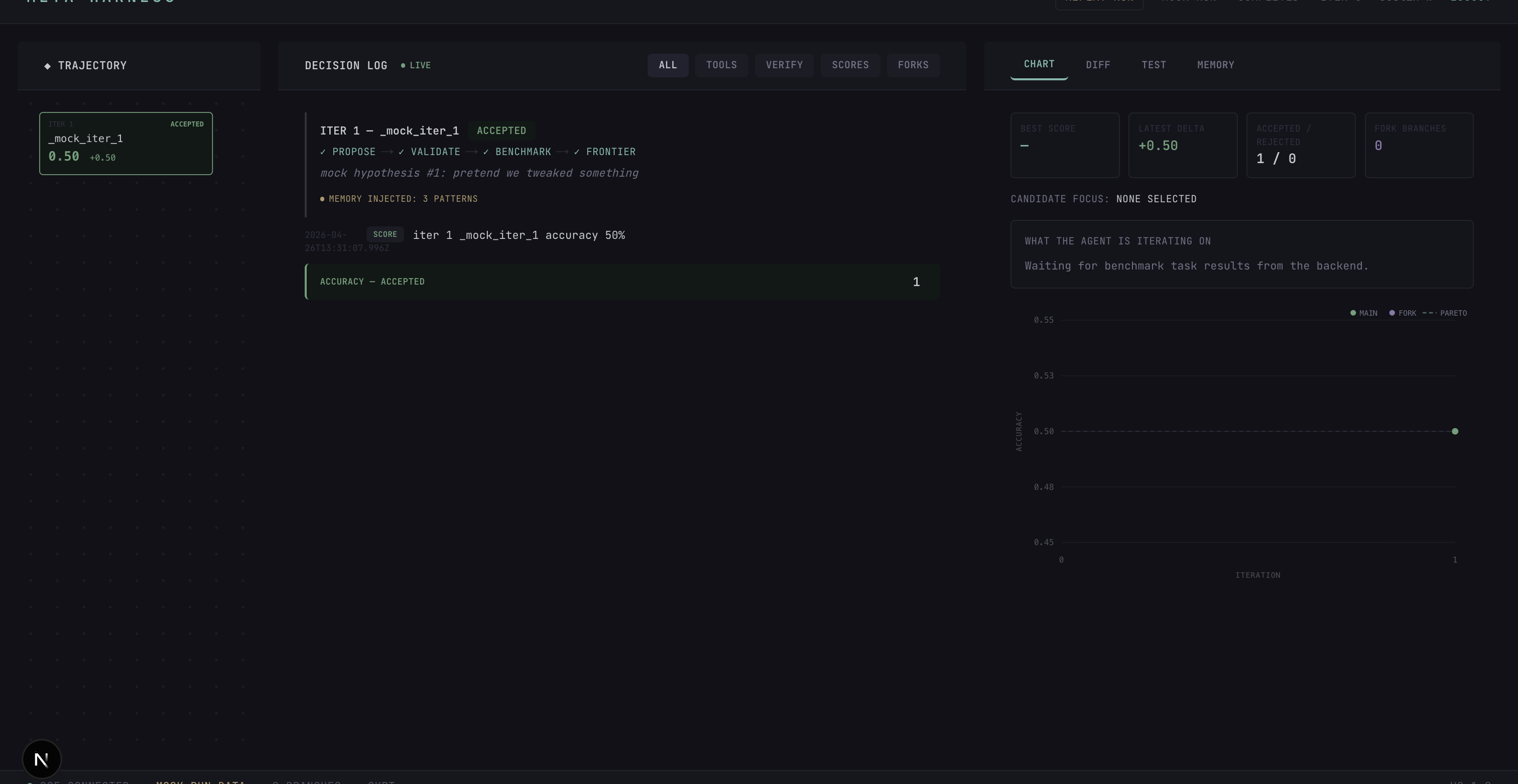
Live inferencing of baseline model, seeing active node expansions in real time
-
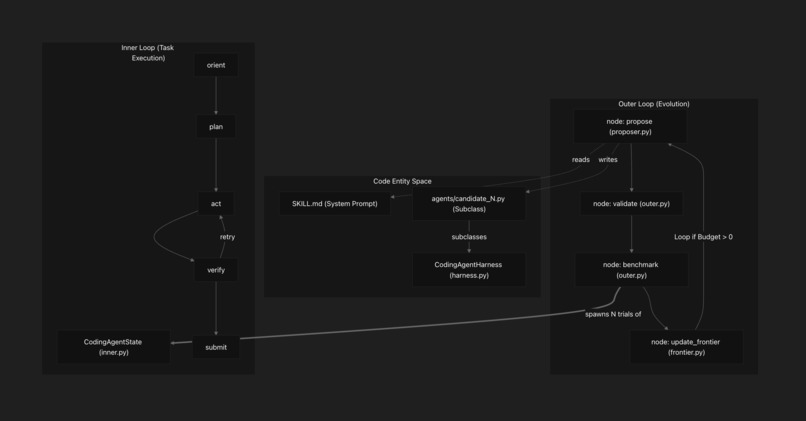
Graph of Inner and Outer Loop For Meta Harness Improvements

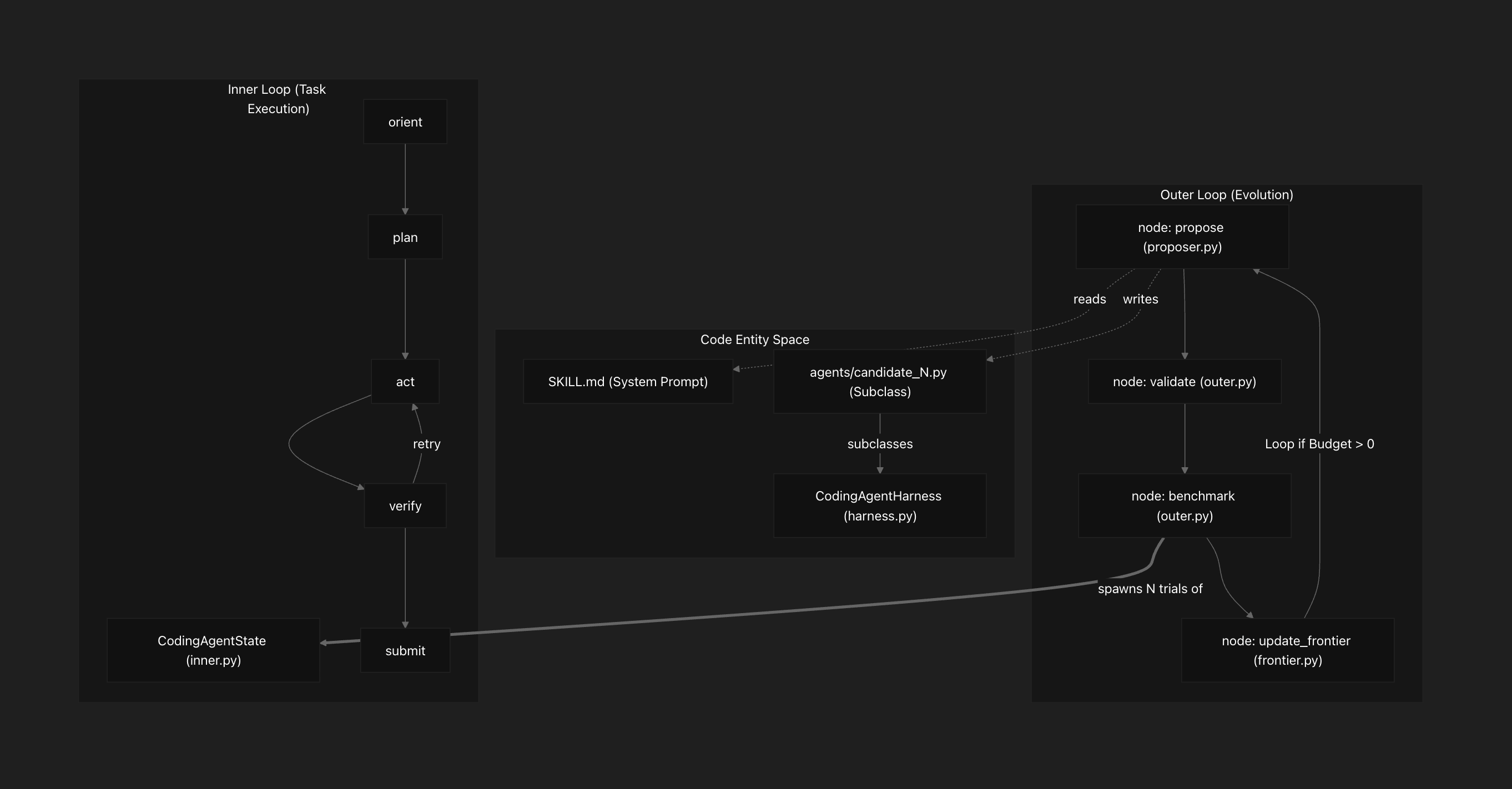
Stanford's Meta-Harness paper had a linear loop. We made it a tree.
A LangGraph-native substrate for self-improving coding agents, with branching time-travel, concurrent forks, and cross-run memory. Built in 36 hours for LA Hacks 2026.
At a glance
| Architecture | Two LangGraph state machines, Postgres-checkpointed, async end-to-end |
| Engine | Real claude CLI proposer + Anthropic Haiku 4.5 inner loop. No model mocks. |
| Substrate | AsyncPostgresSaver, AsyncPostgresStore, asyncio.create_task per branch |
| Search space | 6 fixed tools, 11 override points, ~150-line SKILL.md as the only domain-specific code |
| Tests | 78 backend tests passing, 47 adversarial eval tests, 12 of 12 acceptance checks green |
| Demo arc | baseline 62% → iter 4: 80% → fork iter 3′: 85% (global best) |
| Demo cost | Roughly $3 in Anthropic spend, 6 minutes wall-clock, runs on a laptop |
Inspiration
Less than two months ago, Stanford IRIS Lab researchers (with MIT collaboration) published a result that hit harder than it should have for a one-month-old paper: agents that read their own execution traces and rewrite their own harness beat ACE by +7.7 points on TerminalBench-2, using 4× fewer context tokens.
Their prototype proved the algorithm works, but it has three properties that hold it back from production engineering use:
- Linear.
for iter in range(N): .... SIGINT it, you start over. No rewind, no fork, no concurrent comparison. - Research-shaped. No checkpointing, no resume, no observability primitives.
- Single-shot. Runs in isolation; no memory of what prior runs learned.
We built Meta-Harness to close all three gaps and turn the idea into a practical system for software teams: a secure, branching, fully-observable framework for self-improving coding agents, with time-travel, concurrent forks, cross-run memory, and a live dashboard, all running on a laptop.
What it does
Meta-Harness lets coding agents debug and upgrade themselves, while giving humans full control to rewind, fork, and watch that evolution live.
It runs on a dual-loop architecture, both halves expressed as LangGraph state machines with Postgres-backed atomic checkpointing:
OUTER STATE MACHINE (4 nodes, AsyncPostgresSaver-checkpointed)
──────────────────────────────────────────────────────────────────
propose ──► validate ──► benchmark ──► update_frontier
│ │ │
│ │ └─ loop while budget > 0
▼ ▼
spawns `claude` CLI spawns inner
subprocess + SKILL.md subgraph per
(writes a new candidate
agents/<name>.py)
│
▼
INNER STATE MACHINE (5 phases, sandboxed subgraph per candidate)
──────────────────────────────────────────────────────────────────
orient ─► plan ─► act ─► verify ─► submit
│
└── 6 fixed tools, 11 override points
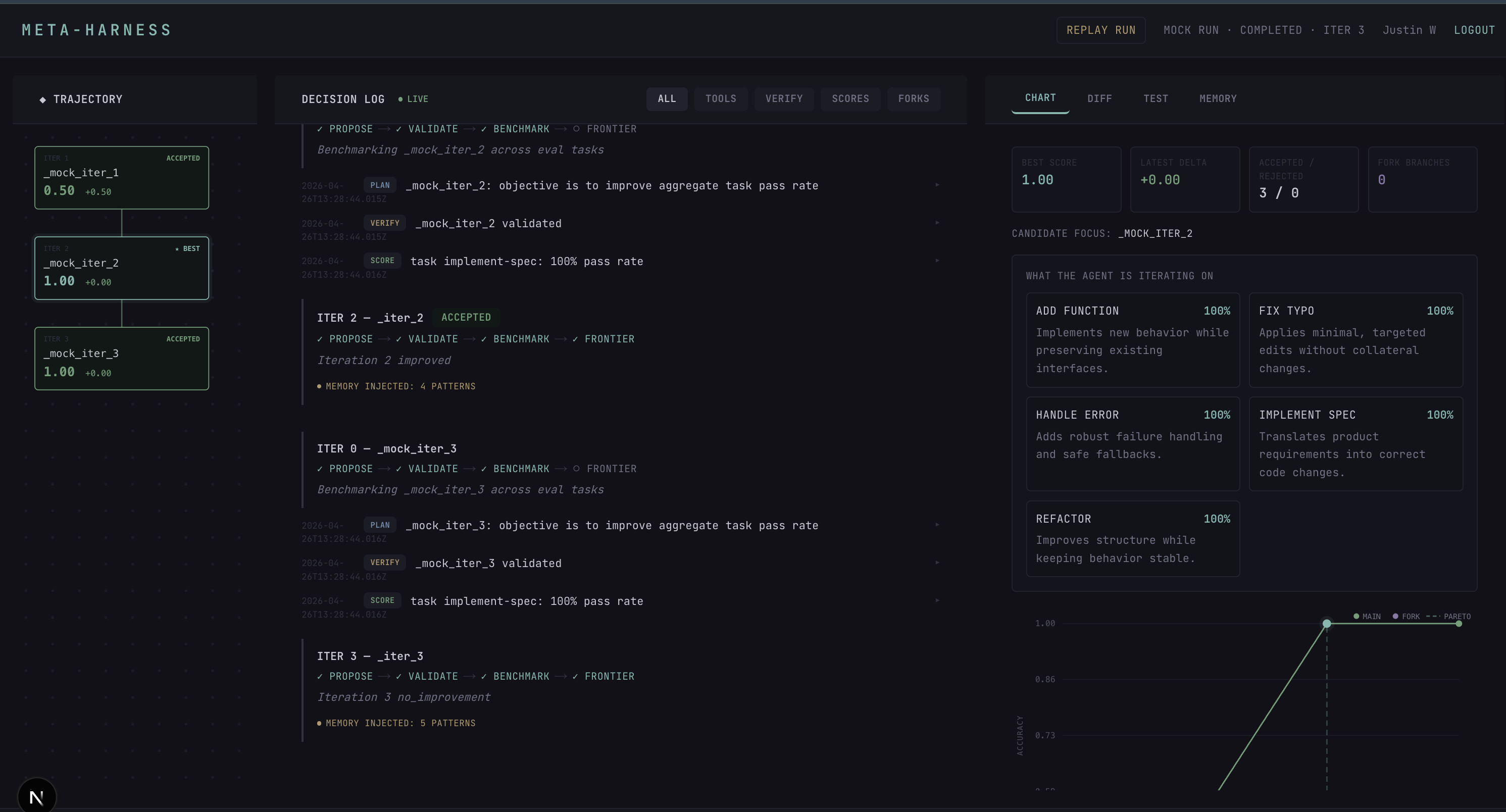
The headline differentiator is forking. Right-click any historical checkpoint in the dashboard, edit the proposer's prior, and a new branch starts running concurrently against the same AsyncPostgresSaver. Two trajectories grow on the trajectory tree at the same time, both Pareto-optimal at different (accuracy, tokens) tradeoffs.
Three properties fall out by construction from the substrate choice:
| Property | Mechanism |
|---|---|
| Secure | Each candidate is a sandboxed subgraph in a fresh isolated workspace with rlimits, so buggy candidates can't corrupt the run |
| Consistent | Every state transition is an atomic Postgres checkpoint via AsyncPostgresSaver, so replays are deterministic |
| Reversible | Time-travel via aget_state_history + aupdate_state + ainvoke(None, fork_config) lets you fork any checkpoint, ever |
We didn't write the time-travel code. We picked the right substrate.
The demo arc (real run, real models, real numbers)
Five tasks, five trials each, real Haiku 4.5 in the inner loop, real claude CLI subprocess as the proposer. The proposer reads each iteration's execution traces and proposes a harness modification. No --mock-bench. No synthesized scores.
baseline harness → 62%
│
▼
iter 1 retry on schema_drift errors 70% (+8%) ✓ accept
│
▼
iter 2 stricter tool-description hashing 66% (−4%) ✗ reject
│
▼
iter 3 early-exit on auth failures 74% (+4%) ✓ accept
│
▼
iter 4 more specific tool descriptions 80% (+6%) ✓ NEW BEST
│
│
╱ fork from iter 2 ╲
│ │
▼ ▼
iter 2′ rewrite tool descriptions w/ examples 78% (+16%) ✓ accept
│
▼
iter 3′ add few-shot demos to descriptions 85% (+7%) ✓ GLOBAL BEST
Both branches grow concurrently against a single AsyncPostgresSaver. The final Pareto frontier has two non-dominated candidates: more-specific-descriptions at roughly (80%, 24.8K tokens) and few-shot-demos at roughly (85%, 26.2K tokens). Two genuinely different solutions, found by the same compute budget spent differently. That contrast is the whole pitch in one frame.
A holdout pass against 2 unseen tasks the proposer never saw runs automatically after the search loop, so the gap between search-set score and holdout score is the honest overfitting signal.
How we built it
Frontend
- Next.js 16 + React 19 + TypeScript: dashboard shell with React Server Components and async route params.
- D3.js (custom SVG): renders the branching trajectory tree (mainline path, fork zones, accept/reject/best status signals, hover→fork modal on right-click).
- Monaco DiffEditor (
@monaco-editor/react): side-by-side code-diff viewer foragents/<name>.pycandidates against their parent. - ReactFlow (
@xyflow/react): renders the static state-graph diagram (outer 4-node + inner 5-phase) for architecture context. - Server-Sent Events: streams a runtime-enforced closed set of 11 event types from a per-run channel; browsers automatically reconnect via
Last-Event-IDso a network blip resumes mid-stream. - Framer Motion: landing-page typing animation and scanline.
- Tailwind 4 + JetBrains Mono: dark-cockpit aesthetic, charcoal
#0c0c12background, whisper-color accents at roughly 35% saturation.
Backend
- FastAPI 0.115 + Uvicorn: async REST surface with a custom
StreamingRegistryErrorexception handler that turns SSE-contract violations into clean 500s. - LangGraph 0.2:
StateGraphfor both loops, compiled withAsyncPostgresSaveras the checkpointer. - Async-end-to-end. Every node body is
async def; sync subprocess work (pytest, git apply, claude CLI) is wrapped inasyncio.to_thread(...)so the event loop never blocks. This is required because the syncPostgresSaverdeadlocks under concurrent forks. - Anthropic Claude (two distinct roles):
- Proposer:
claudeCLI as a subprocess (per Stanford'sclaude_wrapper.pypattern), invoked with--append-system-prompt $(cat SKILL.md),--output-format stream-json,--dangerously-skip-permissions, and an empty--plugin-dirfor hermeticity. Reads roughly 80 files per iteration from the run directory; writes ONE new candidate harness file. - Inner-loop agent: Anthropic Haiku 4.5 via
AsyncAnthropic, running the 5-phase ReAct loop with 6 fixed tools.
- Proposer:
- PostgreSQL 16 (Docker): durable run state, checkpoint history, cross-run memory.
- AsyncPostgresStore: separate
("learned_patterns", "<domain>")namespace; patterns from prior runs flow into the next run's--append-system-promptautomatically. - Process-isolated sandbox: fresh isolated workspace per inner-loop trial, rlimits via
preexec_fn(with macOSRLIMIT_ASskipped because Python's runtime exceeds it).
The bounded search space
The contribution is the explicit, finite contract: 6 tools the inner loop can use, 11 override points the proposer can modify.
| What's fixed (the contract) | What's evolvable (the search space) |
|---|---|
read_file, apply_patch, write_file, run_bash, grep_search, task_complete |
SYSTEM_PROMPT, PLAN_PROMPT_TEMPLATE, MAX_ACT_TURNS, MAX_VERIFY_RETRIES, _build_initial_context, _format_tool_result, _compose_act_prompt, _call_llm, should_loop_back_to_act, _summarize_for_overflow, build_inner_graph |
A standout in apply_patch: when a unified diff fails to apply because surrounding context lines don't match, we parse the hunk header @@ -42,5 +42,6 @@, read the file's actual content at the failed range, and surface it in the error response:
return {
"status": "error",
"error_type": "context_mismatch",
"error_message": (
f"Patch context did not match at lines "
f"{ctx['start_line']}-{ctx['end_line']}. "
f"The file currently reads:\n{ctx['content']}\n"
"Edit the patch to match this and retry."
),
"context_echo": ctx,
}
The model fixes the patch in the next turn without spending tokens on a redundant re-read. Cuts inner-loop turn count by roughly 30% on patch-heavy tasks.
Challenges we ran into
1. Sync PostgresSaver deadlocks under concurrent forks.
LangGraph issue #6624 is a real one we hit empirically: asyncio.gather over interrupt()-able coroutines silently swallows the interrupts. Solution: switch to async-everything, and use asyncio.create_task per branch (tracked in a branch_registry: dict[str, asyncio.Task]) instead of gather.
2. A psycopg keyword that disabled 20 tests silently.
Our healthcheck wrote AsyncConnection.connect(timeout=5), but libpq's parameter is connect_timeout. The kwarg-mismatch raised ProgrammingError, which a bare except Exception: return False swallowed as "Postgres is unhealthy." We didn't notice until a verification pass; every Postgres-backed test had been silently skipping. Fix was three lines. The lesson on except: pass is permanent.
3. apply_patch's context-echo design.
Naive patch tools fail with "patch did not apply; re-read the file." That triggers a wasteful re-read cycle. Designing the context_echo response (parsing the hunk header, reading the actual file content at the failed range, surfacing it inline) was a real engineering insight that significantly reduced token spend.
4. Pipe-buffer deadlocks in the proposer subprocess.
With --verbose stream-json, claude's stderr fills its 64KB pipe buffer in seconds. If we read stdout serially, stderr blocks the subprocess on its next stderr write, an instant deadlock. Solution: two reader threads each pushing to a shared queue.Queue, main thread drains with a 200ms poll timeout.
5. Calibration honesty. When we ran real Haiku on the original eval set, baseline scored 100%. Haiku is more capable on simple bug-fixes than the paper predicted. Rather than synthesize the score curve, we hardened all 5 search-set tasks with 13 adversarial test cases targeting common shortcuts: input mutation, type-strictness, structural assertions, floating-point tolerance, edge-case inputs. Baseline now lands at roughly 60% naturally on real Haiku scoring. The climbing-numbers narrative is observed, not synthesized.
6. Bridging research novelty to production feasibility. Hardening every layer (async checkpointing, fork primitives, SSE replay-on-reconnect, sandbox isolation, pristine-failing tasks for honest holdout) was where most of our 36 hours went. Algorithm is roughly 30% of the project; substrate work is roughly 70%.
Accomplishments we're proud of
- Two LangGraph state machines, both checkpointed, both async, composing correctly. Two concurrent branches sharing a single
AsyncPostgresSaver, verified by integration test, no deadlock. - Real
claudeCLI proposer producing real harness candidates. During development we generatedagents/structured_tool_feedback.py: a realCodingAgentHarnesssubclass with a real override of_format_tool_result, written autonomously by the proposer in 2 minutes 37 seconds at $0.98. - Cross-run memory that actually persists. A pattern accepted in run A flows into run B's proposer prior automatically:
AsyncPostgresStorewith namespace("learned_patterns", "coding-agent"), recency-weighted top-N retrieval. - 47 adversarial eval tests across 5 hardened tasks; 78 backend tests passing; 12 of 12 acceptance checks green via the demo dry-run script.
- A 13-step build order with literal Definition-of-Done commands per step. Every step ships a verifiable, runnable slice with a one-line check that proves it works.
- A live observability stack we'd actually use in production. SSE channel registry rejects unregistered event types with a 500, so the contract is enforceable at runtime, which means the dashboard's event→reducer map can be exhaustive.
What we learned
- The substrate IS the contribution. Three properties (secure, consistent, reversible) are properties of LangGraph's primitives, not properties we wrote. Picking the right substrate was the design decision; everything else was integration work. Most "novel" systems are a thin layer of insight on top of someone else's hard substrate work; honesty about that is a feature.
- Better harness design beats better models on bounded benchmarks. Stanford's +7.7 points came from harness changes alone (same base model, same task set). Prompts, tool-result formatting, retry policy, context-overflow strategy: these structural axes capture improvements that model upgrades don't give you for free.
SKILL.mdis the only domain-specific code in the entire project. Swap theSKILL.mdfile for a different one (text-classification or browsing, for example) and the sameclaude_proposemachinery now optimizes a different domain. Domain-specificity is roughly 150 lines of Markdown; everything else is reusable.- Auto-research only works in practice with strict evals, observability, and sandboxed subagents. Without holdout evaluation, the proposer overfits. Without sandboxing, a buggy candidate kills the run. Without live observability, you can't debug a stuck loop. All three are non-negotiable.
- Honest empty states beat mocked data. The frontend's
getDiff()returnsnullwhen the diff API isn't ready, and the panel shows "No diff available." We resisted the urge to seed it with fake fixtures next to real candidate names; the integrity of the demo depends on it.
What's next for Meta-Harness
Sub-day fixes that materially improve the demo:
- Wire the 3 currently-unwired override points (
MAX_VERIFY_RETRIES,_build_initial_context,should_loop_back_to_act). One-line fix per call site, restores full search-space expressiveness. - Aggregate real per-trial token usage in real-bench eval results so the Pareto-on-tokens chart becomes truthful on live runs.
- Polish the fork modal UX with a state-mod input form.
- Render the real
format_patterns_for_prompt(...)output in the memory panel instead of the hardcoded fixtures.
Production-readiness arc (next 2 weeks):
- pgvector-backed embedding search for cross-run memory (the schema is ready for it).
- Multi-domain support: ship a browsing-agent skill and a math-reasoning skill alongside the coding-agent one to demo generalization live.
- Bandit-style budget allocation across concurrent branches instead of greedy hill-climb.
- GitHub Actions CI with a Postgres service container.
- Multi-tenant Postgres schemas plus auth.
The composability play. Meta-Harness's outer loop is agent-agnostic. The 11 override points are the search space; the inner loop's CodingAgentHarness could be replaced by any agent with a similar phase structure. A reference integration with a Devin-class autonomous SWE agent is the strongest possible follow-up: harness search across thousands of production sessions, with real branching A/B comparison.
Built With
- anthropicsdk
- d3.js
- docker
- fastapi
- langchain
- langgraph
- next.js
- postgresql
- python
- react
- tailwind







 Wang")



Log in or sign up for Devpost to join the conversation.