
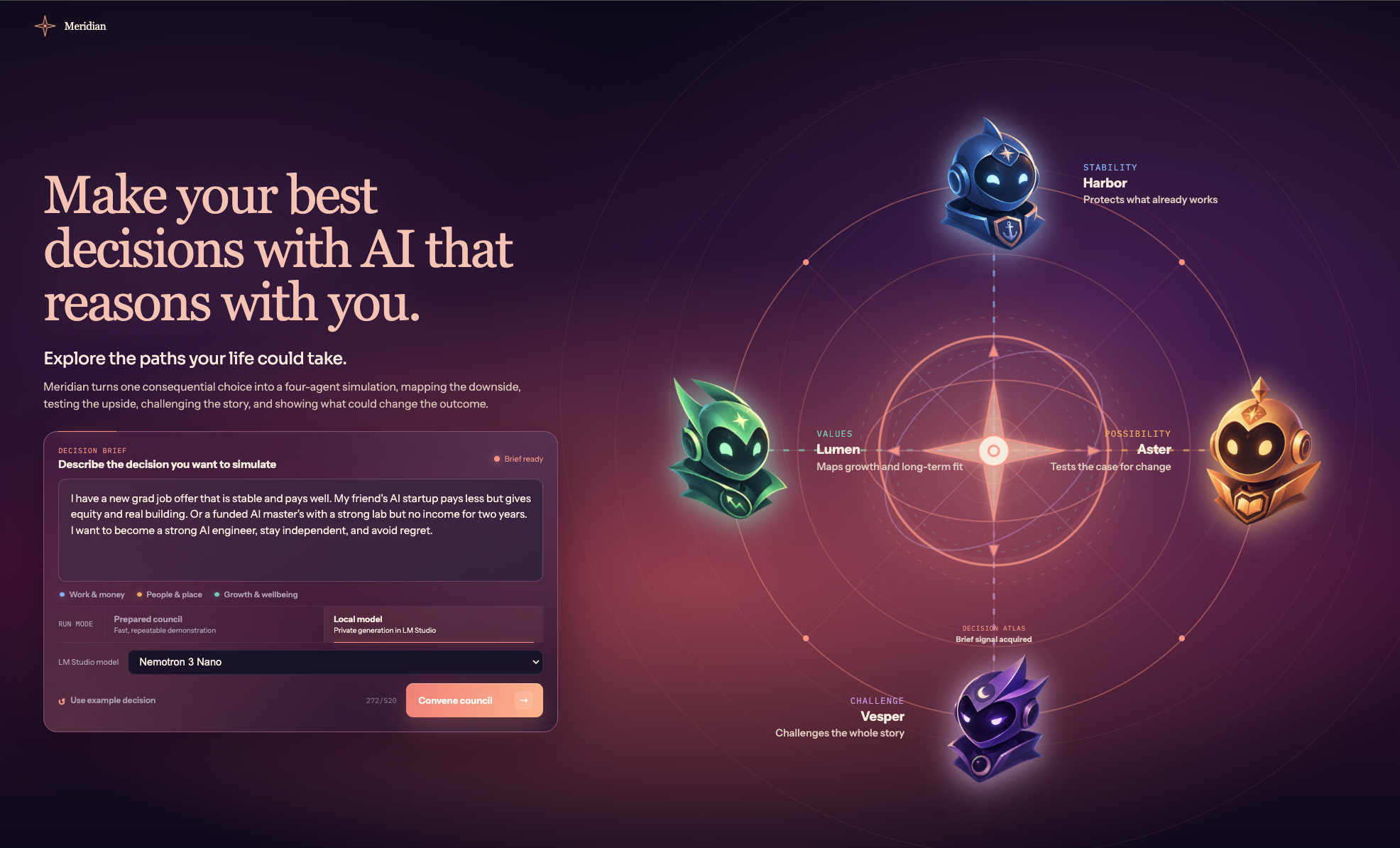

Inspiration
When we have a big decision to make, almost none of us trust a single opinion. We ask a mentor about playing it safe, a friend who took the leap about the upside, and someone blunt enough to tell us where we're kidding ourselves. Then we open an AI tool and do the opposite: one prompt, one model, one confident answer. The catch is that the assumption that matters most is usually the one nobody questioned. We were living this ourselves, weighing a job against a startup against grad school, so we built a room full of advisors who argue, show their reasoning, and hand the decision back to us.
What it does
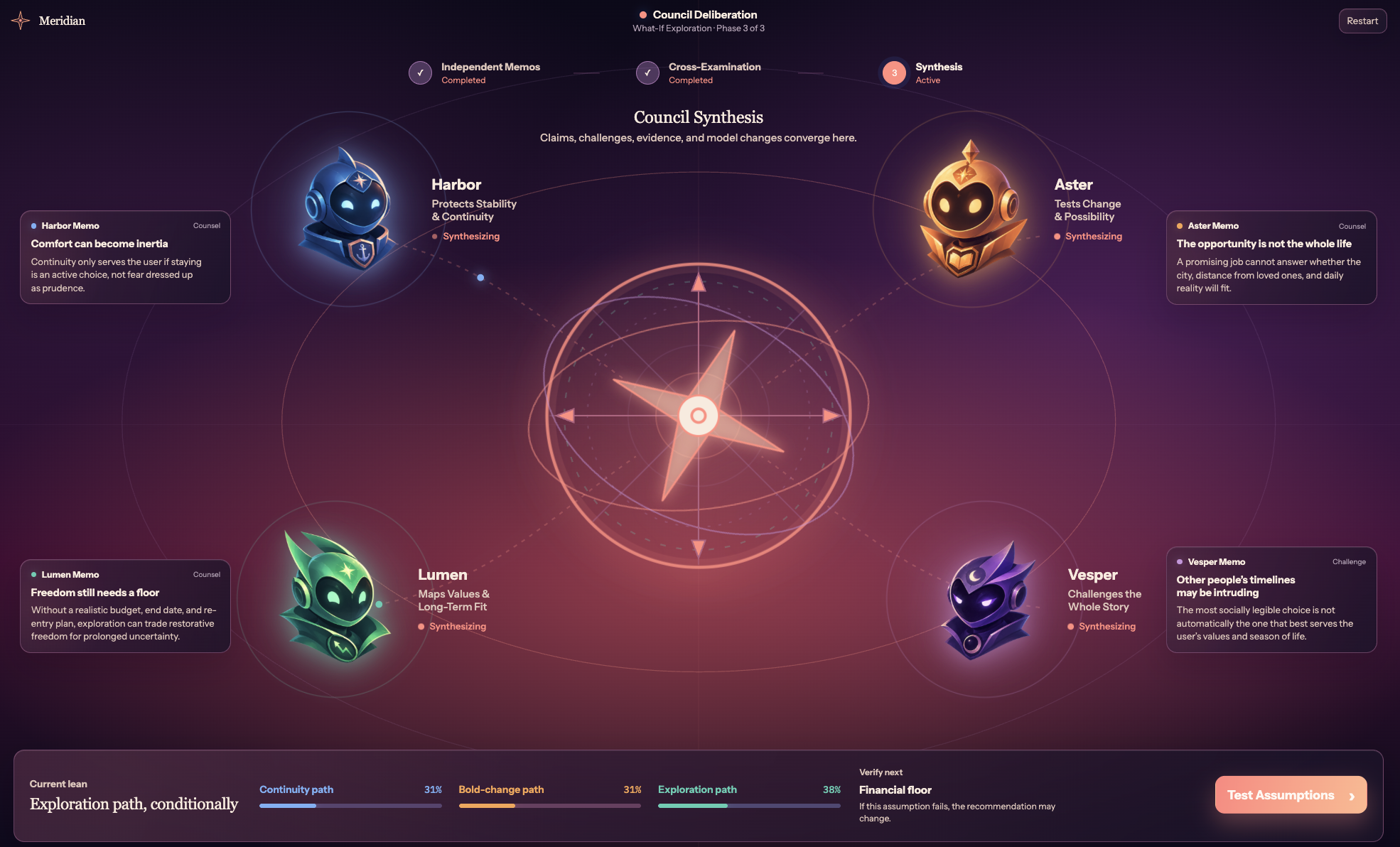
You describe a decision in a sentence or two, and four agents talk it through, each seeing it differently. Harbor cares about stability, Aster about change and upside, Lumen about what you value and who you want to become, and Vesper is the skeptic picking apart the other three. They pull from an evidence library, write up their takes, and argue. When Vesper catches something, like startup equity not being the same as a paycheck, the model updates and every change shows up in a ledger so you can see what moved and why.
Then it becomes numbers. Everything that matters is a range, not a single guess, and the engine plays out thousands of versions of how it could go. You get a recommendation, but you can grab the assumptions yourself and watch the answer shift, then read a straight brief: the call, the biggest risk, the one thing most likely to flip it, and what to do next. It all runs on your own machine, so the most personal thing you'd ask never leaves it. Meridian helps you decide; it never decides for you.
How we built it
It's a React and TypeScript app, and all the AI runs locally through LM Studio. The agents do the reasoning but never the arithmetic: they build the picture, and a separate engine produces every number you see, with nothing shown without a source behind it. The debate and the sliders run through that same engine, so an agent's revision mid-argument and your own slider drag use the same math, and the recommendation never contradicts itself.
Challenges and what we learned
The hardest part was that shared engine: making the debate and the live controls one system so they never disagree took real care, as did getting four agents to sound like four different ways of thinking instead of one assistant in four hats. The biggest lesson was that multiple agents only matter if their arguments actually change something. A council that just chats is theater; one that rewrites a shared model is reasoning. We also learned that honest uncertainty beats confidence, and that local models can run a grounded, four-way deliberation on a laptop.
What's next
We want to open Meridian up to any decision someone types in and let people revisit it as their life changes, while keeping the one thing we care about most: an AI that helps you think without pretending to think for you.

Log in or sign up for Devpost to join the conversation.