Meridian
Inspiration
One of us has a younger sister who, as a teenager, struggled with suicidal thoughts and saw a school therapist. What she remembers isn't the therapist's words — it's that the therapist felt like a robot, sitting behind a clipboard, scratching notes, never looking up. She needed a person. What she got was someone taking minutes.
That wasn't that therapist's fault. Mental health providers spend 35% of their work hours on documentation — fourteen hours a week. It's the number-one driver of burnout in the field. The research is unambiguous: you cannot take detailed notes during a session without breaking eye contact and disrupting the therapeutic alliance — the single strongest predictor of whether therapy works, accounting for roughly 80% of outcome variance.
Meanwhile, 40–60% of patients drop out of therapy, most before session ten. The reasons aren't financial — they're losing the thread between sessions, not feeling heard, not seeing progress. All solvable with better tooling.
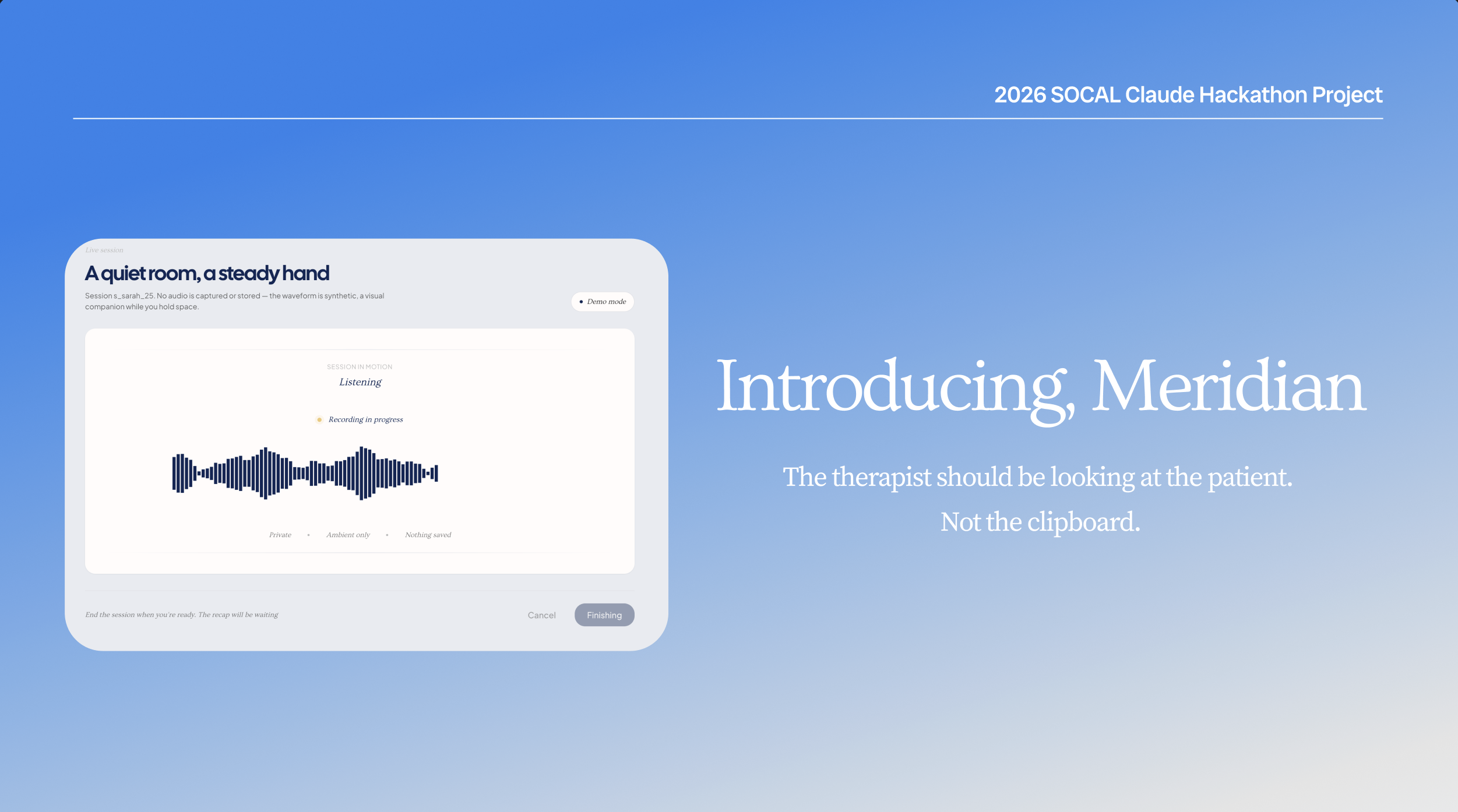
Meridian is what we wish that therapist had — and what we wish Sarah had been able to write into.
What it does
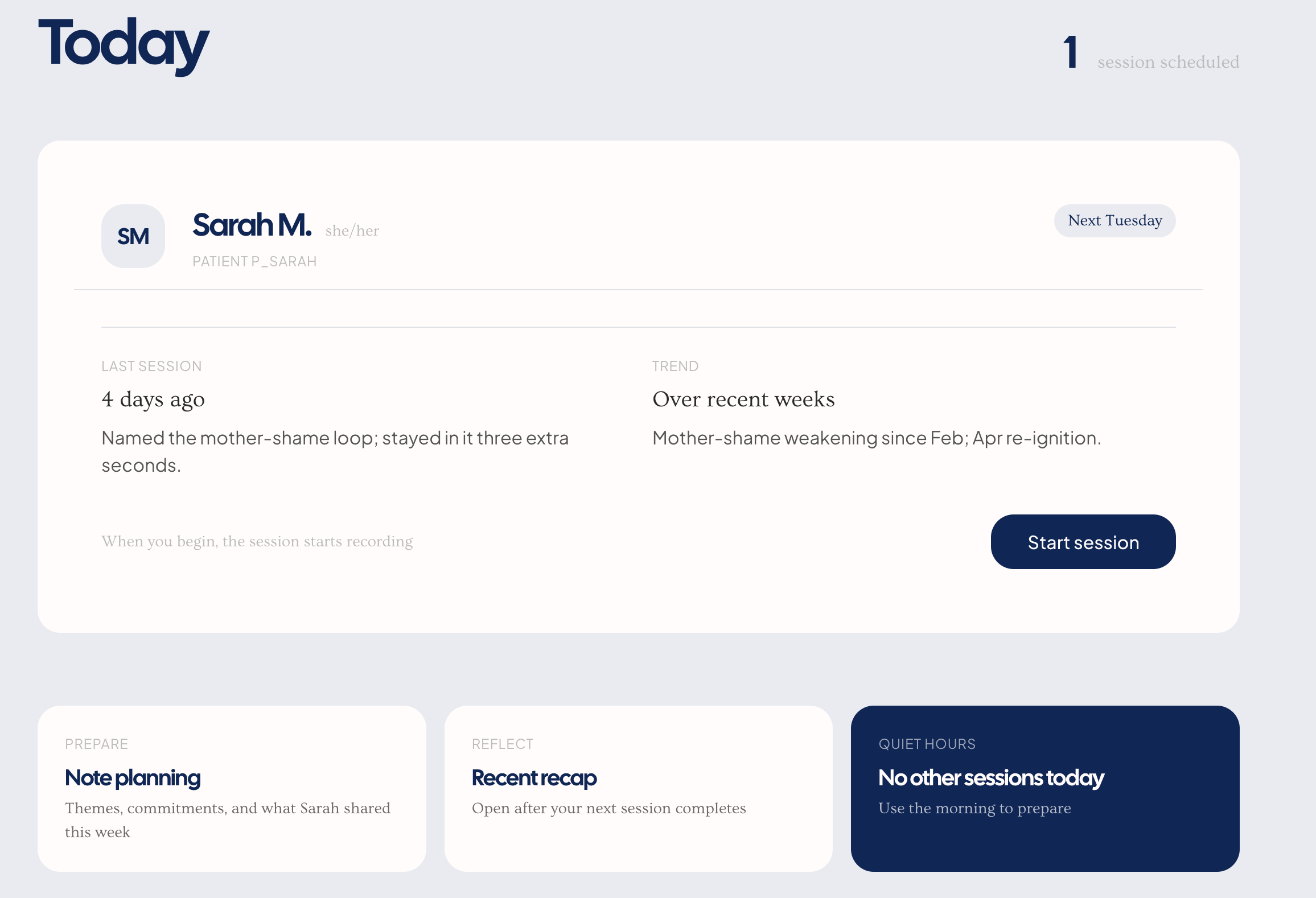
Meridian is a shared clinical record with two authors: the therapist and the patient. Everything is organized around one patient's living arc — sessions, journals, themes, commitments, and emotional patterns — rendered as a graph that grows week over week.
Four surfaces over one record:
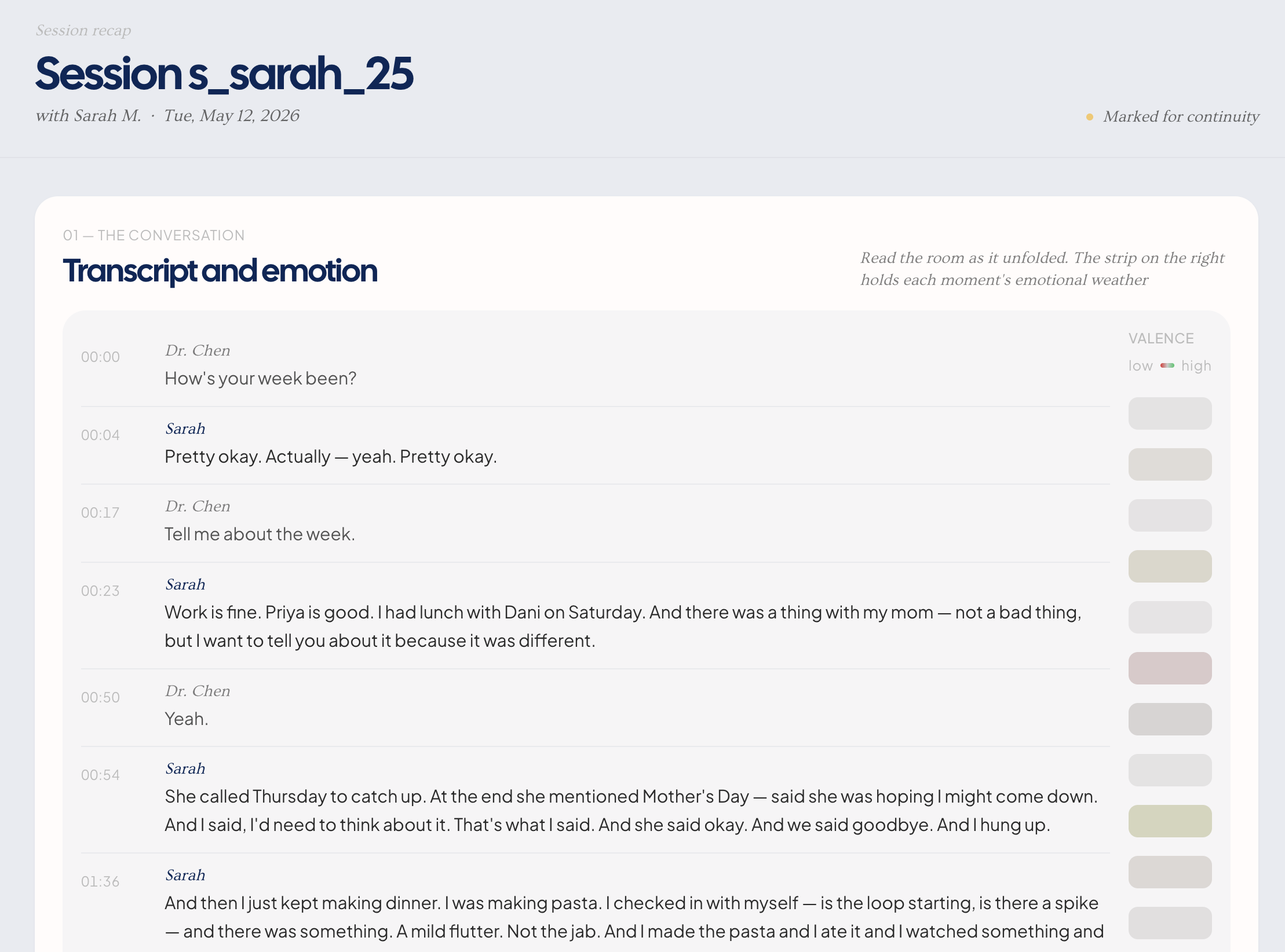
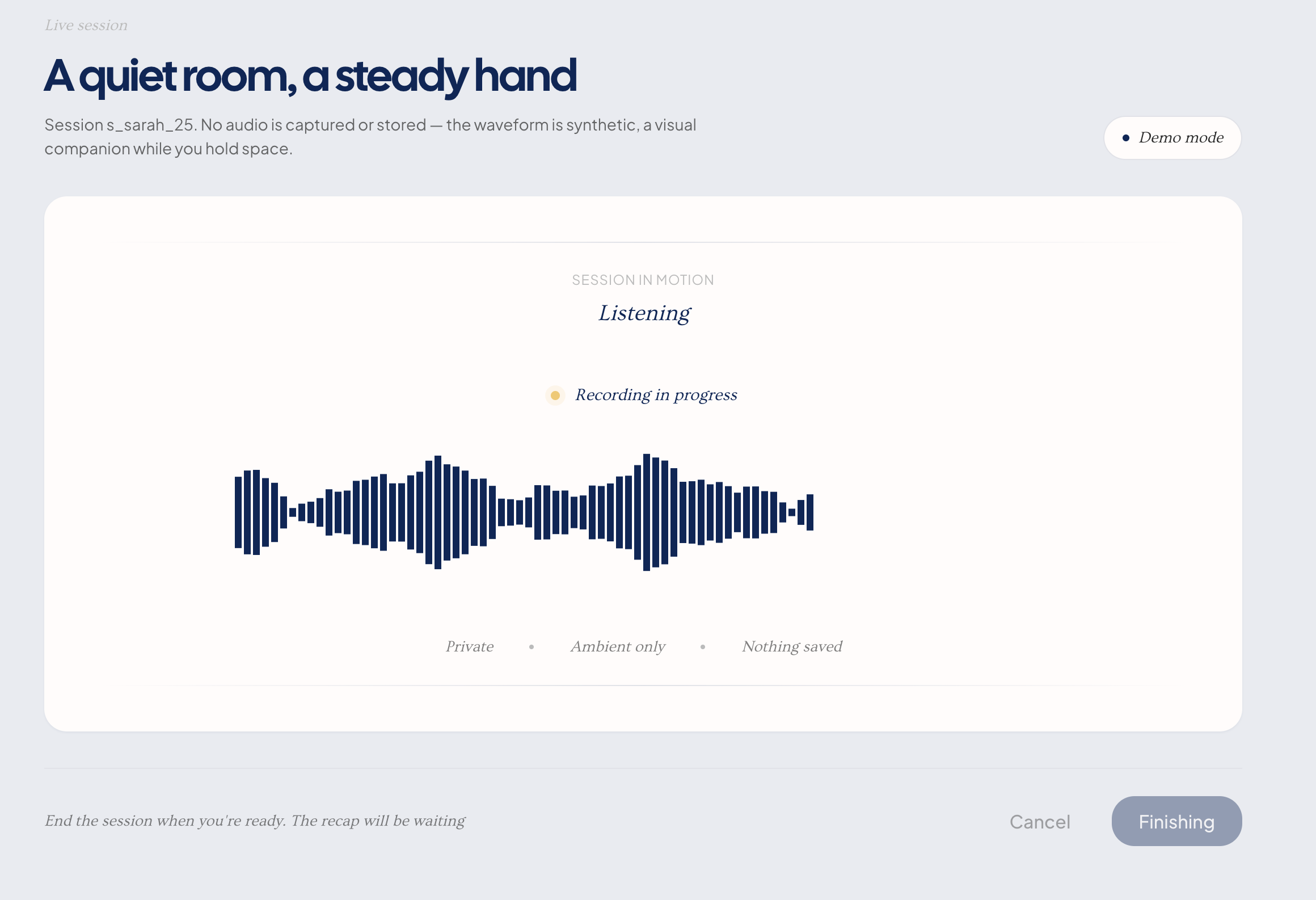
Session capture & recap. The therapist hits record and the session runs normally — no laptop between them, no clipboard. Afterward, Claude Opus reads the full transcript end-to-end and returns structured data: themes, commitments verbatim, emotionally-marked moments, and cross-references to journal entries the patient mentioned. The therapist sees a recap with full transcript, an affect heatmap, extracted themes, and hinge moments — including when the session touches a journal entry the patient wrote between visits.
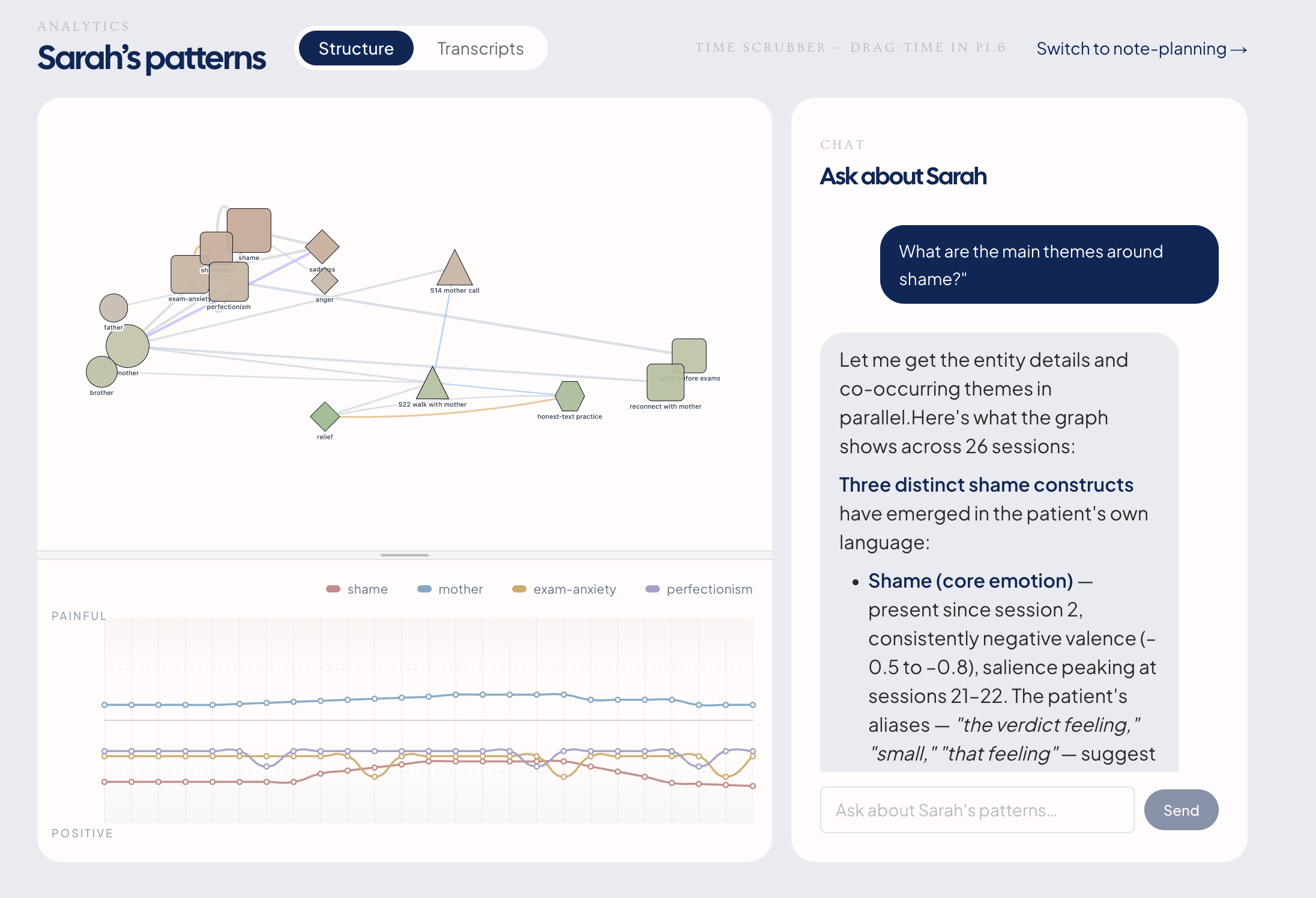
The living graph. Every session and journal merges into a patient-scoped graph. A streamgraph encodes valence-over-time per theme — you can literally see the edge between
motherandshamethinning across six months. That's therapeutic progress made visible. A chat interface lets the therapist query the full corpus ("When did Sarah first use the word 'shame' herself?") with citation-grounded answers linking back to the exact line in the transcript.The patient view. Same record, in the patient's voice. A journal (the intervention, not a feature — journaling alone produces 20–45% symptom reduction in clinical trials). Per-entry visibility controls:
Private,Share with Dr. Chen,Include in next brief. Mood trends. When the patient toggles an entry fromPrivatetoSharedon her laptop, the change propagates to the therapist's screen in ~200ms via Supabase Realtime. The patient is a co-author, not a data source.Next-session prep (the closed loop). Before each session, Claude surfaces the full arc: last session's themes, unmet commitments, shared journal excerpts, patterns from the graph. The therapist walks in holding the whole arc — no first-ten-minutes reorientation. Claude does the remembering. The clinician does the thinking.
How we built it
Where Claude is core, not bolted on:
- Extraction pipeline. Transcript → Claude Opus → strict JSON schema (themes, commitments with timestamps, affect markers, cross-references). No hand-crafted rules, no bespoke ontology. Claude is the pipeline.
- 1M-context reasoning. Six months of care — 25 transcripts, 38 journal entries, 24 SOAP notes, ~108k tokens — fits in a single Claude window. No lossy chunking, no retrieval guesswork. The whole patient is reasoned over as one unit. This is why "when did Sarah first use 'shame' herself?" works at all — it requires scanning every utterance she ever made across 21 sessions.
- Citation-grounded chat. Every answer returns a source link back to the exact line. Prompt-engineered refusal when evidence isn't in-corpus.
- Context surfacing for prep. Graph-derived context populates the left pane of the prep page. The right pane is a blank text area. Claude does not draft clinical notes.
- Entity resolution. pgvector candidate retrieval + a single-turn Claude Sonnet judgment for graph merge decisions — semantic recall paired with model reasoning for precision.
Stack:
- Claude Opus 4.x (1M context) — extraction, chat, context surfacing
- Claude Sonnet — entity resolution judgments
- Next.js 16 (App Router) on Vercel with Fluid Compute
- Supabase — Postgres + Realtime + Row-Level Security
- pgvector — semantic candidate retrieval
- OpenAI Whisper API — speech-to-text
- Zod — schema validation at every API boundary
- react-flow — graph render; SVG/D3 — streamgraph + affect ribbon
- Tailwind + shadcn/ui
Two laptops, one database: Presenter A drives the therapist view from the main laptop; Presenter B operates the patient view from her own. Both connect to the same Supabase project. When B toggles a journal entry's visibility, the main screen updates in ~200ms. The "two authors, one record" thesis is literal, not metaphorical.
Challenges we ran into
Zero-hallucination chat. In clinical contexts, a fabricated memory is a clinical error. Getting Claude to refuse rather than confabulate required aggressive citation-or-refusal prompting, and rigorous testing across ~10 phrasings of our hardest anchor questions. We kept finding edge cases where the model wanted to summarize across sessions without sourcing. The fix was structural: every answer must cite a line with a session ID and timestamp, or the model is instructed to say "I don't see that in Sarah's record."
Entity resolution at graph-merge time. When a new session says "my mother," is that the same
mothernode from S9, or a new one? Pure vector similarity got us 80% of the way; the 20% wrong answers were the costly ones. We moved to a two-stage design: pgvector retrieves candidates, Claude Sonnet makes the final call in a single judgment turn with full context. That jumped precision substantially without blowing latency.Demo-day risk vs. honesty. The full ingestion pipeline takes 30+ seconds on a real session — too long for a 3-minute pitch. Our rule: anything shown on stage must survive a judge poking it. So the main flow plays pre-computed Claude outputs (on the real seed data — nothing fabricated) for reliability, while a "Run pipeline live" button runs the actual STT + extraction + graph merge on fresh audio for the Q&A. Pre-computation as a timing choice, not a credibility one.
Real-time sync on unpredictable venue WiFi. The two-laptop demo is the emotional peak. Supabase Realtime is solid, but conference WiFi is not. We built three fallback tiers: venue network → phone hotspot → full-offline localhost mode. All three tested identical flows.
Context window budget. 108k tokens is comfortable in Claude's 1M window but tight in 200k. We had to measure token usage on the full corpus every time we touched a prompt, because any drift would push us over on a bad-luck session.
Affect-marking pipeline pivot. We'd planned on Hume's Expression Measurement API, then discovered mid-build it sunsets 2026-06-14. We pivoted to a Claude-native affect-marking approach that stays strictly inside the "descriptive moment-marking, not diagnosis" ethical boundary.
Accomplishments that we're proud of
The 167-hour hinge actually works. The promise of Meridian — that a patient's Thursday-night journal entry and Tuesday's session become part of one record — is demonstrated end-to-end in the demo. When the recap page highlights "Referenced journal entry j040 — Thursday," that's Claude having read the full transcript and made the connection. The week between sessions is no longer lost.
Citation-grounded chat with zero hallucinations in testing. Across 30+ anchor and adversarial questions, we did not get a single unsourced or fabricated answer. The model refuses cleanly when evidence isn't present.
Two laptops, one record, live. The Supabase Realtime pipeline syncs per-entry visibility changes between the patient's laptop and the therapist's main screen in ~200ms. The audience literally watches the patient become a co-author.
A streamgraph that makes therapy visible. The edge-weight-over-time render of
mother→shameweakening across six months is genuinely moving to look at. It's the first time we've seen therapeutic progress depicted without a stock "line goes up" chart.We cut features we could have shipped. Auto-drafting clinical notes, crisis detection from journals, AI-initiated patient check-ins, affect-based diagnosis. Each was technically feasible. Each was wrong. "What we chose not to build" is a slide in the pitch, not a footnote.
What we learned
Long context changes the product, not just the engineering. Building on a 1M-context model meant we could skip the retrieval layer entirely and reason over a whole patient as one unit. That collapsed a whole class of "what if we miss a relevant chunk" bugs and let us promise citation accuracy we couldn't have otherwise.
Restraint is a product feature in healthcare. Every feature we cut made the pitch stronger, not weaker. Clinicians don't want AI that replaces their judgment; they want AI that gives them back the hours they lose to documentation. The model of "Claude remembers, the clinician thinks" is not a compromise — it's the right shape.
"Two authors" has to be literal to be believable. Early drafts had the patient view as a second tab on a single laptop. It played as a slogan. The moment we put Sarah's view on a second physical laptop, with realtime sync, the thesis became self-evident. Sometimes the demo architecture is the argument.
The ethics beat writes itself when the architecture is right. We didn't have to invent a separate "responsibility" story. The product's boundaries (patient-scoped RLS, per-entry visibility defaults to private, text area instead of generated draft, no crisis flagging) are the ethics story.
Honesty about pre-computation is more credible than faking real-time. Saying "the main flow uses cached outputs for timing, here's a button that runs the real pipeline live" is more trustworthy than a flaky live demo. No one can accuse you of a fake if a button press produces new graph nodes from fresh audio.
What's next for Meridian
Near-term (next 3 months):
- HIPAA-compliant deployment. Move to Supabase/Vercel enterprise tiers with signed BAAs; encrypt at rest and in transit end-to-end; formalize the audit trail we already write for every graph merge and visibility change.
- Pilot with 3–5 solo-practitioner therapists. Outpatient mental health is the right wedge: highest documentation burden, weakest EMR tooling, least vendor lock-in. We want real clinicians probing real patient arcs.
- Clinician note templates. Right pane stays a text area, but with therapist-authored templates the clinician can pull in — still no AI-drafted clinical language.
- Replace the Hume affect dependency with a fully Claude-native affect-marking pipeline before the June 2026 sunset.
Medium-term:
- Measurement-based care integration. PHQ-9, GAD-7, and custom scales co-located with the graph. The streamgraph already speaks the right visual language for tracking symptom trajectories.
- Inter-session patient nudges — clinician-authored only. A therapist can ask "remind Sarah about the Wednesday journal experiment" and Meridian delivers it as a message clearly from the therapist. Never AI-initiated.
- Multi-therapist practices. Group practices with supervision workflows — supervisor view, case consult, referral handoff — all preserving patient-scoped access.
- Formal clinical evaluation. Partner with a research group to measure alliance scores, dropout rates, and documentation hours with vs. without Meridian.
Long-term:
- A queryable memory of a whole practice. Beyond one patient — "across my caseload, which interventions have I seen the strongest response to for grief-and-shutdown presentations?" Pattern-level insight for clinicians, never patient-identifying across records.
- Expand to adjacent modalities carefully. Couples therapy (two-patient shared records with consent boundaries), group therapy, psychiatric medication management. Each needs its own ethical review, not a copy-paste.
What we won't do, ever:
- Draft clinical notes.
- Auto-flag crisis from patient journals.
- Diagnose from vocal affect.
- Send AI-initiated messages to patients.
The restraint is the product.
Built With
- anthropic
- claude
- deepgram
- hume
- openai
- pgvector
- supabase
- vercel
- whisper


Log in or sign up for Devpost to join the conversation.