

Inspiration
Before you ship, you'd love a product manager, a designer, a QA engineer, a market researcher, a security engineer, and a DevOps lead to go through your product — and then an investor to grill you. Almost nobody can assemble that room, so people ship blind:
- 42% of startups fail because there was no market need (CB Insights),
- a bug caught after launch costs up to 100× more than catching it before (IBM Systems Sciences Institute),
- and the AI you'd ask for a gut-check just flatters you — recent research found models agree with a user's wrong belief ~64% of the time.
We wanted the opposite of a yes-man: a whole product team that assembles in seconds, looks at your real product, and hands you one prioritized verdict — before your users (and investors) do.
What it does
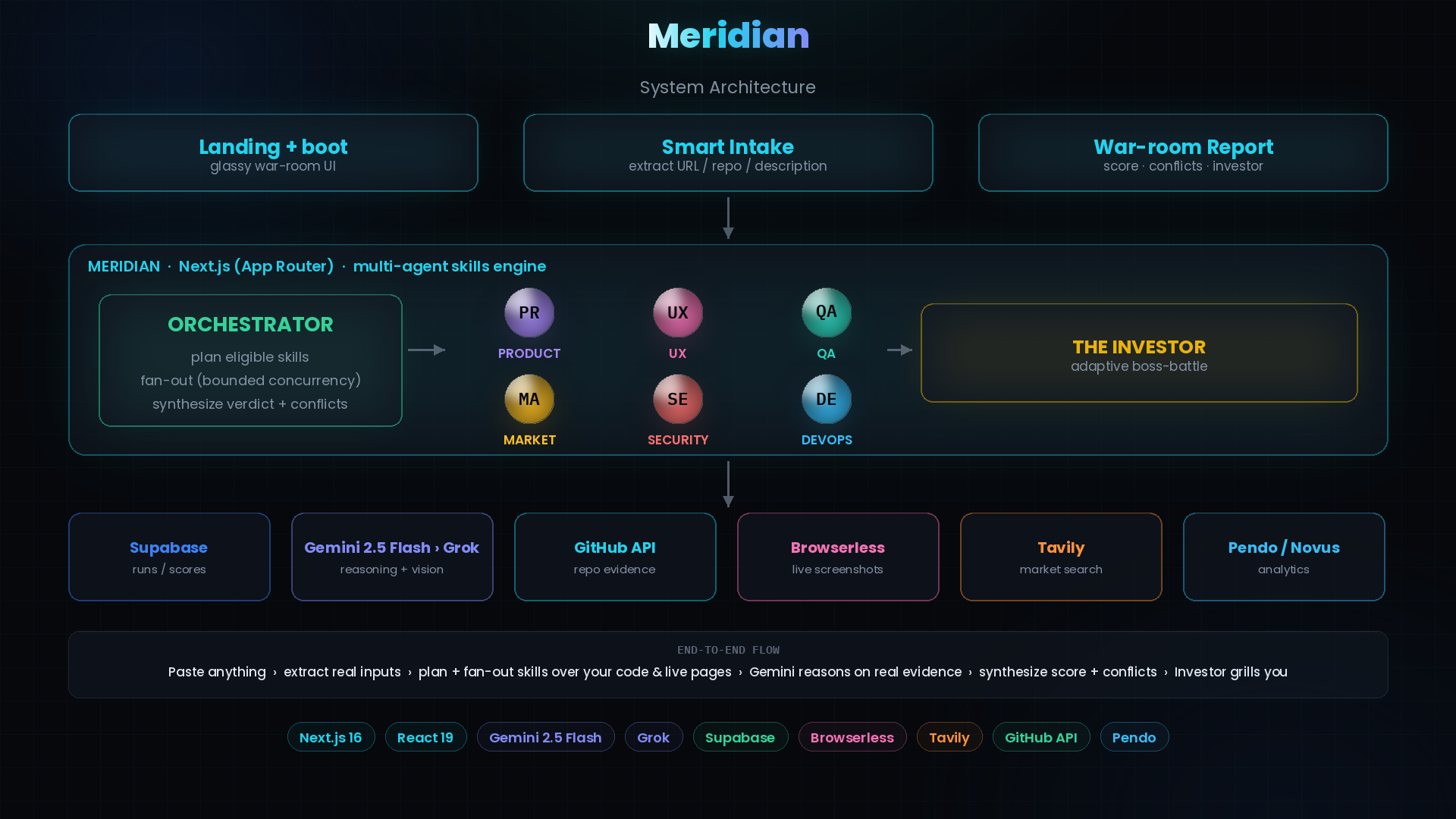
Paste a live URL, a public GitHub repo, a description, or even a whole Devpost submission, and Meridian:
- Smart Intake auto-extracts the live URL, the repo, and the description — even pulling them out of an aggregator page like a Devpost submission — shows you what it found, and lets you pick which specialists to run.
- Six specialists analyze at once — UX, QA, Market, Security, DevOps, and the Product Lead — each running their own skills over your actual code and live pages: reading the repo on GitHub, screenshotting the site for the UX agent to see, checking internal links, searching the market.
- One verdict — a transparent Meridian Score /100 (a documented weighted average that renormalizes when a specialist can't run, so a missing input never counts as zero), a prioritized fix list, and per-specialist report cards where every finding cites real evidence.
- The team can disagree, and the PM resolves it — when one specialist says "block" and another says "ship," Meridian surfaces the conflict and the product lead makes the call.
- The Investor grills you — a final boss-battle that challenges you on what the team actually found and adapts to how well you defend it.
How we built it
- Frontend: Next.js 16 (App Router) + React 19 + Tailwind v4 + Framer Motion — a glassy "mission-control" UI with a boot intro, a war-room report, and a light/dark theme.
- AI: Google Gemini 2.5 Flash (with vision for the screenshot-based UX review), with an automatic fallback to xAI Grok on rate-limits.
- Multi-agent skills engine: a code orchestrator decides which skills are eligible from the inputs +
mode, fans them out per-skill with bounded concurrency, then synthesizes the verdict and runs the
investor debate. Each skill is an authored
SKILL.mdwith its own rubric. - Real evidence tools: GitHub API, a page fetcher + head-signal extractor, Browserless for live screenshots → vision, an internal link checker, and Tavily web search for the market skills.
- Persistence: Supabase (runs, per-skill results, events) over PostgREST, with an in-memory write-through cache.
- Analytics: Novus.ai (by Pendo), installed on Meridian itself — we instrument the whole funnel (product submitted → analysis started → each specialist's score → verdict → investor debate) so we can see exactly how it's used.
- Deploy: Vercel.
Challenges we ran into
- Stopping false positives was the whole game. Early runs invented vulnerabilities (a "SQL injection" on a static query, "SSRF" on a logging call), flagged marketing demo content as a "PII leak," called current dependencies "outdated," and read a still-loading image as a "placeholder." We built a verification loop — cloning the real repo and probing the live site to fact-check the AI's own findings — and re-grounded every skill: never assert something you can't see in the evidence, reserve critical/high only for directly-verified issues, and say "could not verify" instead of guessing.
- Serverless state. A run is driven across many short-lived serverless functions, so a per-instance cache went stale and a run could freeze mid-synthesis. We made Supabase the source of truth on every read, so runs stay consistent across instances and survive reloads.
- Aggregator inputs. Making "paste a Devpost link" actually work meant crawling the submission page for the real repo + deployed URL hiding inside it, and cleaning the README's HTML into readable text.
- Fair scoring. A dead deploy, a login wall, or a timed-out specialist shouldn't tank the whole score — so unanalyzable inputs drop their specialist and the weights renormalize, with a visible note.
What we learned
The interesting engineering in an LLM product is the guardrails, not the prompt. Most of our work went into making the agents trustworthy: never assert what you can't verify, calibrate severity, and show your evidence. A confident wrong answer is worse than an honest "I couldn't check that."
What's next for Meridian
- Judge Mode — paste a hackathon submission and grade it against that hackathon's own rubric.
- Founder Readiness Score by theme, derived from the investor debate.
- Take-it-with-you — PDF export, a shareable report link, an embeddable score badge, and one-click GitHub-issue text for each fix.
- Authenticated + mobile screenshots so the UX and journey reviews go even deeper.
Built With
- browserless
- framer-motion
- gemini-2.5-flash
- github-api
- google-gemini
- next.js
- novus.ai
- pendo
- postgresql
- react
- supabase
- tailwindcss
- tavily
- typescript
- vercel
- xai-grok


Log in or sign up for Devpost to join the conversation.