Meridian
Meridian is an autonomous discovery interviewer for product teams. A PM gives Meridian a research goal and a list of people to interview; Meridian prepares the interview plan, conducts the conversation by voice, synthesizes the transcript, updates a living insight document, generates a sharper next interview plan, and turns the accumulated research into a stakeholder-ready PDF report.
Inspiration
AI transformation is a field both of us have been recently interested in. Businesses have become increasingly insistent on integrating AI into their operations, and we think that every business in the world will follow.
In order for owners to enable AI transformation for their business, they must interview all of their employees to map out the business processes each individual is responsible for. This can be achieved with the use of AI, rather than manually interviewing every employee in the business.
Coming from a product background, we realized that the discovery call problem spans many typical roles, outside of AI transformation: product managers, product marketing managers, middle managers, as well as engineers creating internal tooling. Meridian solves the issue of conducting discovery calls at scale, while also allowing AI to improve the quality of discovery calls through iteration.
What It Does
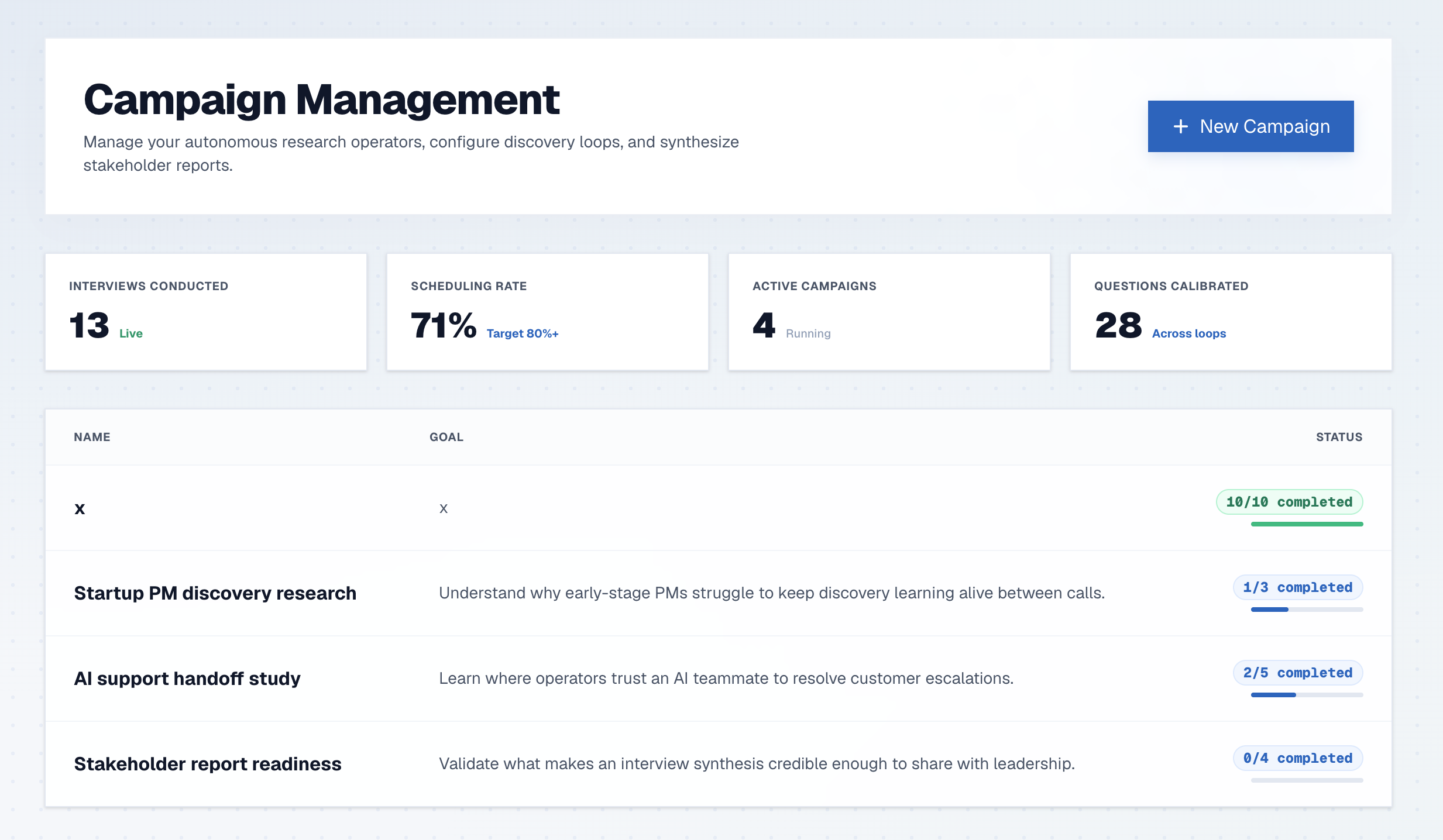
Meridian runs the full discovery loop:
- A PM enters a research goal and contact list.
- Meridian creates an initial AI interview plan.
- Meridian conducts the interview by voice.
- The transcript feeds into synthesis.
- A living insight document updates with themes, quotes, contradictions, confidence levels, and open questions.
- The next interview plan is regenerated from what the system learned.
- Meridian produces a final PDF report for stakeholders.
The key demo moment is the side-by-side evolution from Interview 1 to Interview 2: broad questions become grounded, specific questions backed by real evidence from prior interviews.
How We Built It
We built Meridian as a Next.js and Tailwind web app with a FastAPI backend orchestrating the research loop.
Deepgram powers the live voice interview experience, including speech-to-text, text-to-speech, turn-taking, and barge-in. Claude handles the interviewer reasoning, question generation, transcript synthesis, living insight updates, and report generation.
Redis acts as the memory layer for the adaptive loop. It stores the living insight document, question banks, loop results, and session history so each new interview can build on prior context. The transcript is the core seam in the architecture: whether the interview came from live voice or a deterministic fallback, the same transcript-based loop powers synthesis, memory, question regeneration, and PDF reporting.
Challenges We Faced
The hardest product challenge was staying focused. It would have been easy to build a scheduling tool, a note-taking app, or a generic AI interview bot. Meridian only works if the adaptive loop is obvious: the next interview must be visibly better because of the last one.
The hardest technical challenge was managing live voice risk. A live interview is compelling, but demos are fragile. We solved that by making the transcript the boundary between voice and reasoning. Deepgram can provide the live conversation, but the research engine only needs a transcript, which lets the system fall back gracefully without changing the downstream pipeline.
Another challenge was making trust visible. PMs will not trust an AI-generated insight unless they can see the evidence. That pushed us to show supporting quotes, confidence levels, contradictions, and exactly why the next question bank changed.
What We Learned
We learned that the real bottleneck in discovery is not collecting conversations. It is synthesis and adaptation. A team can record ten interviews and still learn very little if every call asks the same broad questions.
We also learned that an AI research agent feels much more credible when it shows its work. The magic is not just "AI asked questions." The magic is: "this question exists because three prior interviewees exposed a pattern, one person contradicted it, and this next call is designed to resolve that uncertainty."
Finally, we learned that simple orchestration can go a long way. A clear state machine, structured contracts, durable memory, and a transcript-first architecture were more useful than adding a heavy agent framework.
What We’re Proud Of
We built an end-to-end research loop: research goal in, interviews conducted, insights accumulated, questions sharpened, report generated.
We also built the product around the part of discovery that usually gets skipped. Meridian is not just a faster way to collect transcripts. It is a way to keep research alive between calls.
What’s Next
Next, we would expand Meridian from a hackathon demo into a real PM workflow: deeper Redis-backed semantic memory, richer evidence tracing, stronger approval controls for PMs, more realistic multi-interview studies, and integrations for recruiting, scheduling, and CRM context.
The long-term vision is an autonomous research operator that helps product teams continuously learn from customers without losing the rigor that makes qualitative research valuable.
Built With
- claude
- deepgram
- fastapi
- next.js
- pydantic
- python
- react
- redis
- render
- reportlab
- tailwind
- tailwind-css
- typescript
- vercel
- websockets

Log in or sign up for Devpost to join the conversation.