
Mergency — when the internet fails, your AI shouldn't
## Inspiration
Every emergency-response stack I've ever looked at has the same hidden assumption baked into it: the network will be there. Maps live on tiles streamed from a CDN, alerts come through cloud APIs, and the "AI copilot" everyone's racing to ship is a wrapper around a model sitting two thousand miles away in someone's GPU farm.
The first thing that fails in a real disaster is exactly that link.
Paradise, CA — the town the Camp Fire incinerated in 2018 — lost cell service inside of two hours. Hurricane Maria knocked out 95% of Puerto Rico's cell towers and they stayed out for months. After the Tonga eruption the entire country was offline for 38 days. In all of those moments, the people running the response had radios, paper maps, and PDFs they'd downloaded years prior. The AI revolution had nothing to offer them.
I wanted to find out what it would take to put a real, useful language model on an incident commander's laptop — one that knows FEMA NIMS doctrine, can draw evac zones on a map, and never needs to phone home.
That's Mergency.
## What it does
Mergency is a fully offline emergency-response copilot:
- A fine-tuned Gemma 4 E4B (7.52 B params, BF16) runs locally via MLX on Apple Silicon
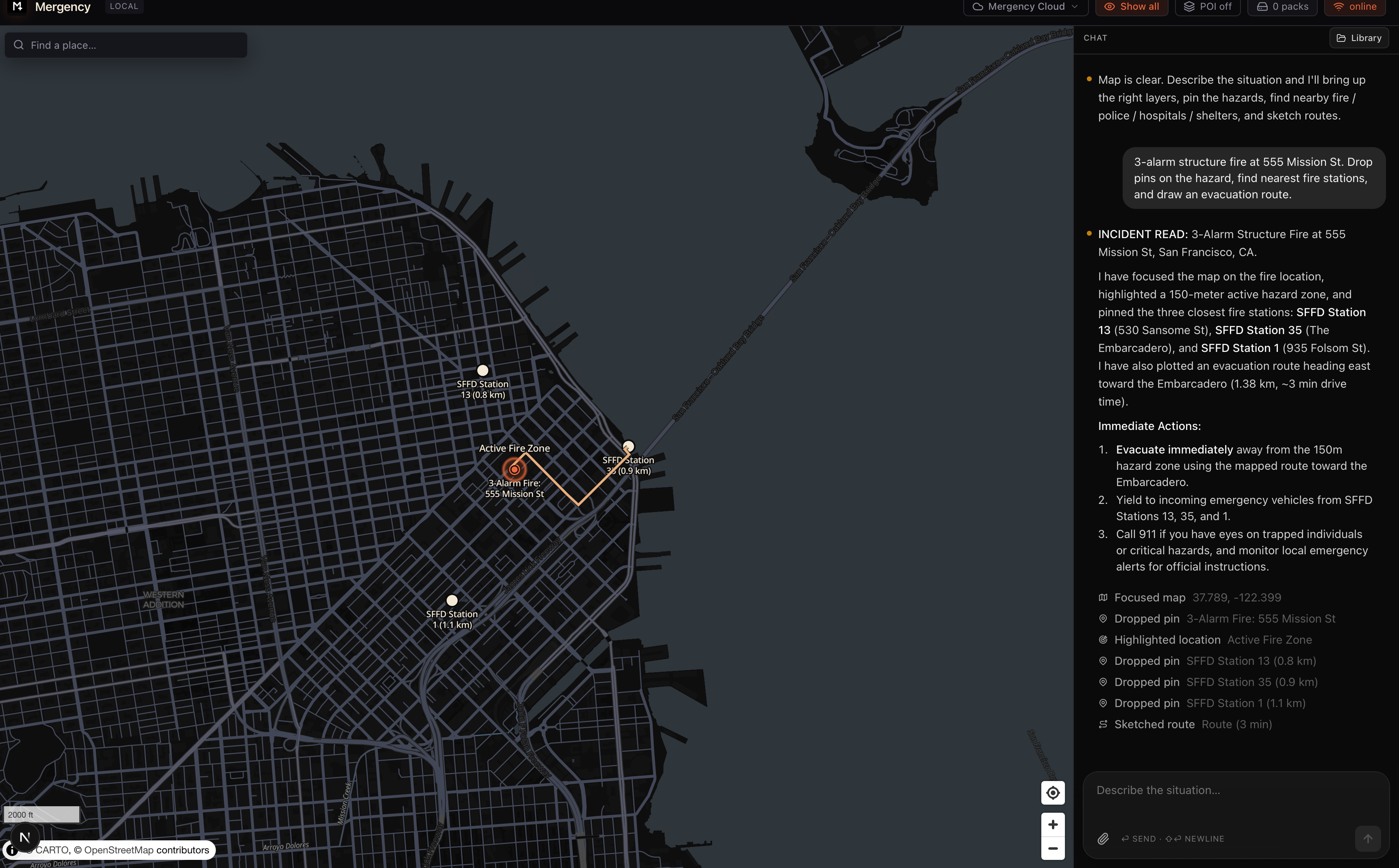
- A chat sidebar takes natural language from a commander — "wildfire approaching Paradise CA", "earthquake risk in the Bay", "flood in Houston"
- The model emits structured tool calls in a custom schema:
draw_zone,drop_pin,draw_route,focus_on,show_layer,clear_annotations - A MapLibre canvas with bundled GeoJSON (US states, counties, USGS faults, recent quakes, NIFC fire perimeters, FEMA flood layers, CalFire hazard zones, HIFLD facilities) renders the model's plan in real time
- Everything — the model, the map data, the routing geometry — is on disk
No tokens leave the laptop.
## What I learned
The biggest lesson is that continued pretraining and supervised fine-tuning are radically different verbs, and both are useful, but only if you sequence them correctly.
For a knowledge-injection pass (CPT), you want the loss on every token of raw domain text:
$$ \mathcal{L}{\text{CPT}} = -\frac{1}{T}\sum{t=1}^{T} \log p_\theta(x_t \mid x_{<t}) $$
For an SFT pass you only want the loss on the assistant's tokens, masking the prompt:
$$ \mathcal{L}{\text{SFT}} = -\frac{1}{|A|}\sum{t \in A} \log p_\theta(x_t \mid x_{<t}), \qquad A = {t : \text{role}(t) = \text{assistant}} $$
If you do CPT alone on a 7B model, you'll inject knowledge and destroy instruction-following at the same time. Val perplexity barely moves. The model knows more facts and is much worse at acting on them. Pure CPT was a dead end for a user-facing demo.
If you do SFT alone, you teach the model how to use tools but it never learns what a fire weather watch is, or which of FEMA's lifelines are activated by a hazmat incident.
The pipeline that actually worked is a curriculum:
- CPT on 1.5M tokens of raw scraped FEMA / Red Cross / CISA / USGS / state EM corpus — to put knowledge into the DoRA-adjusted weights.
- SFT-1 on 3 367 Opus-distilled tool-use trajectories — to re-activate chat behavior and teach the tool schema.
- SFT-2 on edge cases the first pass fumbled.
- SFT-3 on anti-loop examples after I caught the model drawing the same evac zone eight times in a row.
- SFT-4 on a small final-tightening set — early-stopped at iter 60 when val loss started creeping back up (overfit signal).
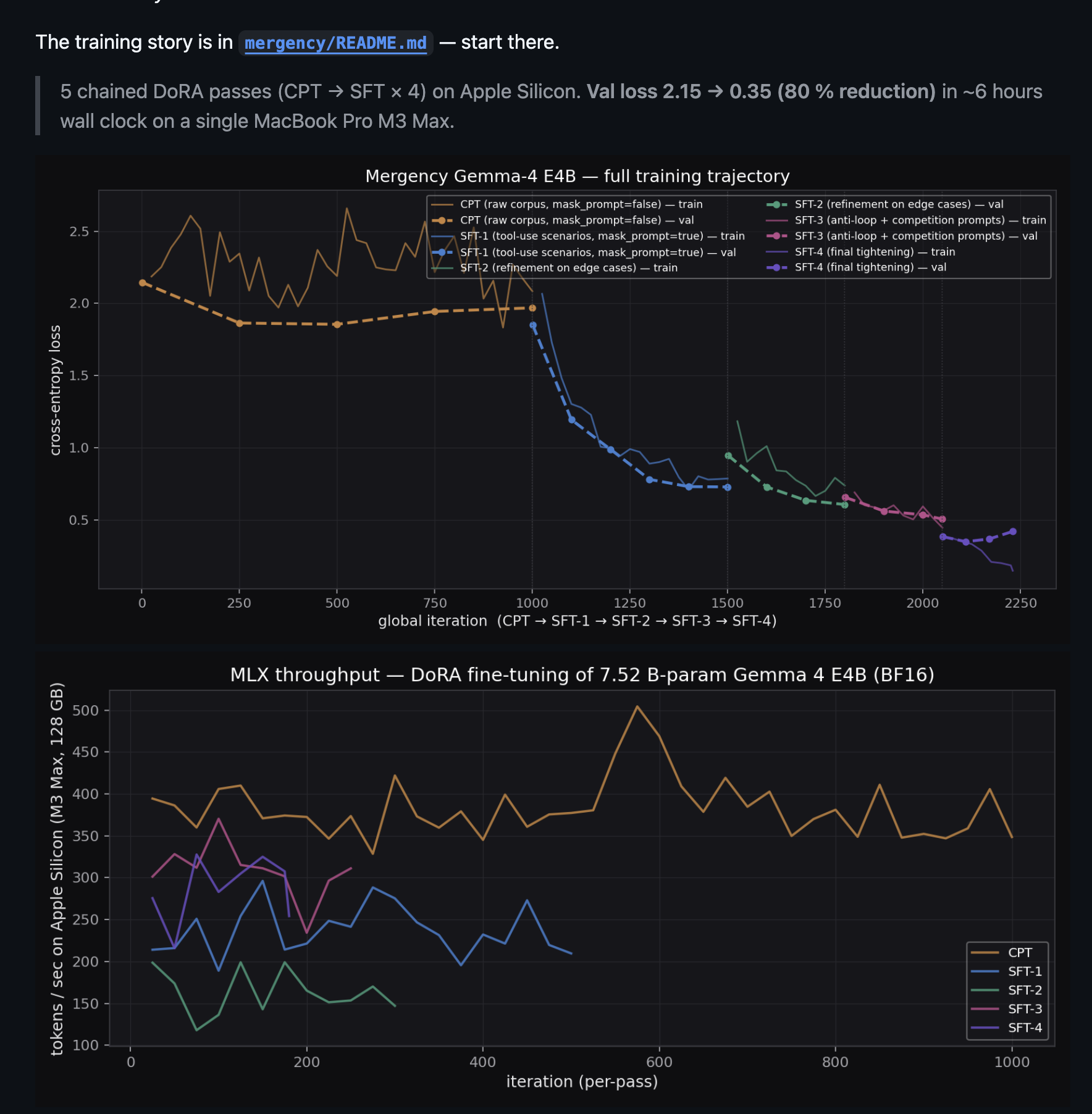
Each pass resumes the DoRA adapter from the previous pass's checkpoint. Val loss across the whole chain:
$$ \text{val loss}: 2.15 \xrightarrow{\text{CPT}} 1.97 \xrightarrow{\text{SFT-1}} 0.73 \xrightarrow{\text{SFT-2}} 0.61 \xrightarrow{\text{SFT-3}} 0.51 \xrightarrow{\text{SFT-4}} \mathbf{0.35} $$
That's an 80% reduction in validation loss in roughly 6 hours of wall-clock training on a single MacBook Pro M3 Max with 128 GB of unified memory. No cluster, no cloud, no rented H100s.
## How I built it
### Stage 1 — corpus scrape
scripts/scrape_corpus.py crawls 326 seed URLs in scripts/seeds.txt: FEMA NIMS / ICS / IS courses / lifelines / after-action reports, Red Cross + CDC shelter and mass-care guidance, CISA infrastructure playbooks, USGS / NWS / USFA
technical docs, and every state EM agency I could find. It crawls depth-1, downloads PDFs, extracts text, deduplicates URLs, and drops thin pages (<500 chars). Final yield: 3 841 unique documents → 67 822 chunks → ~1.5 M trained
tokens.
### Stage 2 — CPT pass
DoRA at rank 64, alpha 128, applied to all 7 projection keys across all 42 layers of Gemma 4 E4B. BF16. mask_prompt: false so the loss covers every token. 1 000 iters, lr 5e-5, cosine decay, effective batch size 16 (2 × 8 grad
accumulation), gradient checkpointing on. About 3 hours wall clock.
### Stage 3 — Opus distillation for SFT data
I needed thousands of realistic incident-commander chat trajectories that emit my tool schema, and writing them by hand was a non-starter. So I ran 12 parallel gen_sft_*.py workers that call Claude Opus 4.7 via claude -p, each
slicing a piece of the (scenario × region) grid:
gen_sft_b01..b06: 1 320 examplesgen_sft_c01..c06: 1 020 examplesgen_compete.py: 326 adversarial / competition-style promptsgen_antiloop.py: explicit "don't repeat the same tool call" examples (added after SFT-2 revealed the loop pathology)gen_sft_d01.py: 621 final-tightening examplesgen_rl.py: 73 preference pairs for a future DPO / GRPO pass
Total spend: roughly ~9 M Opus tokens (~5.4 M in, ~3.6 M out) to generate the training set.
### Stage 4 — chained SFT passes
Each SFT pass:
- resumes the adapter from the previous pass (no re-initialization, ever)
- swaps
data/train.jsonlanddata/valid.jsonlto the new batch - runs with
mask_prompt: true— loss only on assistant tokens - gets shorter and lower-lr each iteration (1e-4 → 5e-5 → 3e-5 → 2e-5)
scripts/sft_launch.sh rotates the data files so the same mlx_lm lora invocation can serve all four passes.
### Stage 5 — fuse + serve
After SFT-4 I fuse the DoRA adapter back into the base model with fuse_peft.py and write a single 16 GB MLX checkpoint at output/mergency-gemma4-e4b-bf16-v3/. The FastAPI backend (backend/server.py) loads it with mlx_lm.load(...),
streams generated tokens to the frontend, and a tiny parser pulls <|tool_call>call:NAME{json}<tool_call|> blocks out of the stream as the model emits them.
### Stage 6 — the app
The frontend is Next.js 16 + React 19 + Tailwind 4 + MapLibre GL. The map view, chat sidebar, tool registry, offline pack downloader, and PDF library (RAG over user uploads) all live in mergency/frontend/components/mergency/. A SwiftUI
desktop port at mergency/loom-desktop-port/ bundles the backend + frontend into a double-clickable .app for non-technical responders.
## Challenges I ran into
CPT degrades instruction-following — badly. After the CPT pass alone, asking the model to draw a zone produced essays about FEMA's lifelines. I almost abandoned the architecture before I realized this is well-documented behavior; the fix is to immediately follow CPT with an SFT pass that re-binds the chat template.
SFT-2 introduced a loop pathology. The model started emitting the same draw_zone call eight times in a row, presumably because the SFT-2 data over-represented multi-zone scenarios. I had to add gen_antiloop.py and rerun as SFT-3 to
teach the model that one zone is usually enough.
Knowing when to stop. SFT-4 was where the val curve started to creep back up — classic overfit signal. I checkpoint every 60 iters and the best checkpoint was the first one, at iter 60 with val 0.351. The temptation to "let it cook" was real; the discipline to early-stop was hard-won.
MLX's gemma4_text path raised on shared-KV layers. Loading the base model failed with extra k_norm weights at the cross-attention layers. Patched mlx_lm/utils.py:415 to pass strict=False so unused weights get dropped instead of
crashing — those weights aren't read by the model anyway.
Memory headroom. DoRA on a 7.5 B BF16 model with batch 2 × seq 4 096 + grad checkpointing parks at ~50–60 GB unified memory. The 128 GB ceiling was the difference between this working on a laptop and not.
<video> tags get stripped from GitHub READMEs. The first version of the README embedded the demo .movs with HTML <video> tags — GitHub's markdown sanitizer silently removed them. Re-encoded to optimized GIFs with ffmpeg + a
generated palette so they inline-play.
The internet I needed to scrape from kept 404'ing me. A meaningful chunk of state EM docs are on aging IIS servers that 404 routinely; the scraper falls back to Web Archive when the original URL fails.
## What's next
- DPO / GRPO pass using the 73 preference pairs already in
data/sft_rl.jsonl - Bigger CPT corpus — 20–50 M tokens is the sweet spot per the literature; I had time for 1.5 M
- Nationwide FEMA NFHL flood layer — currently only CA / TX / FL are bundled
- iOS port — the SwiftUI desktop app already proves the bundling story; iOS is the obvious next surface for first responders
## A note on the math that matters
The reason any of this works in 6 hours on a laptop is that DoRA only updates a tiny fraction of the model's parameters. The full base model has
$$ N_{\text{base}} = 7.52 \times 10^9 \text{ params} $$
A DoRA adapter at rank $r = 64$ across all $L = 42$ layers and $K = 7$ projection matrices, with hidden size $d \approx 3072$, has
$$ N_{\text{adapter}} \;\approx\; 2 \cdot L \cdot K \cdot r \cdot d \;\approx\; 2 \cdot 42 \cdot 7 \cdot 64 \cdot 3072 \;\approx\; 1.16 \times 10^8 \text{ params} $$
That's roughly 1.5% of the base model being trained — which is why a single laptop can finish 5 chained passes in an afternoon, and why the final adapter file is only ~540 MB.
When the internet fails, your AI shouldn't.
Built With
- bash
- chatgpt
- claude
- css
- dora
- fastapi
- flexsearch
- framer-motion
- gemma
- html
- httpx
- huggingface
- idb-keyval
- lottie
- lucide/tabler
- macos-sandbox+entitlements
- maplibre
- mlx
- next.js
- pdfjs-dist
- pydantic
- python
- python-dotenv
- pytorch
- react
- react-markdown+remark-gfm
- shadcn/ui+radix
- swift
- swift-package
- swiftui+appkit
- tailwind
- typescript
- uvicorn
- xyflow/react+dagre
- yaml


Log in or sign up for Devpost to join the conversation.