-
-
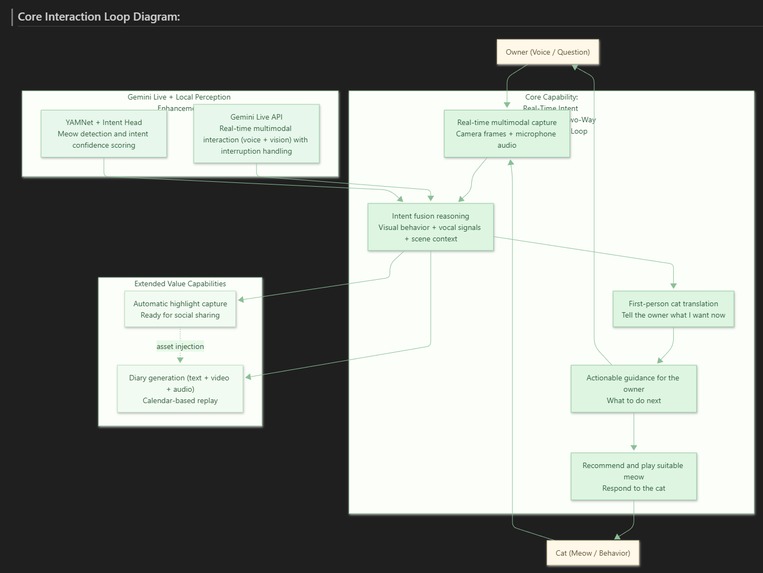
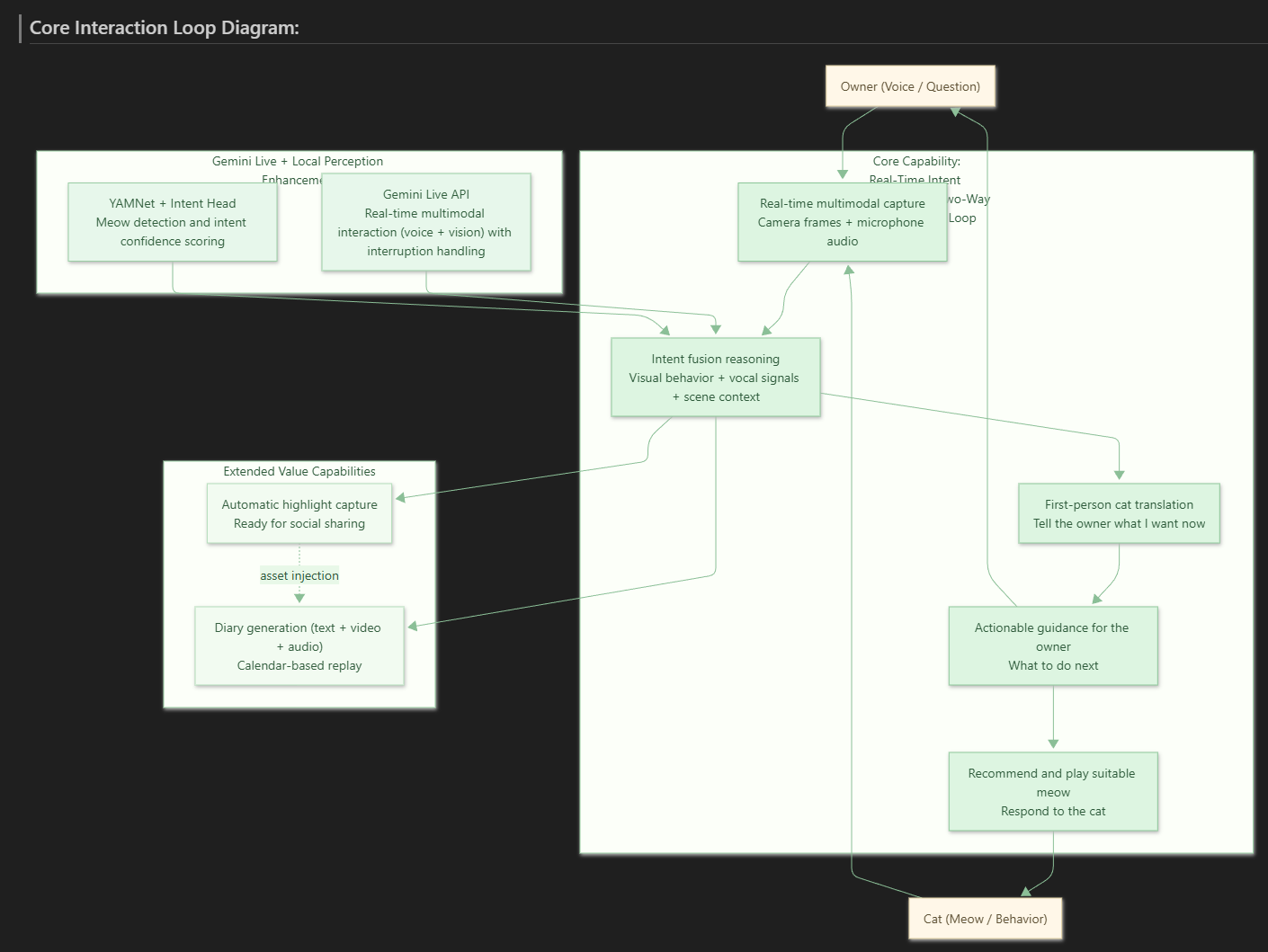
Gemini Live acts as the brain, fusing vision, audio, and context to deliver instant first-person translation, guidance, and meow replies.
-
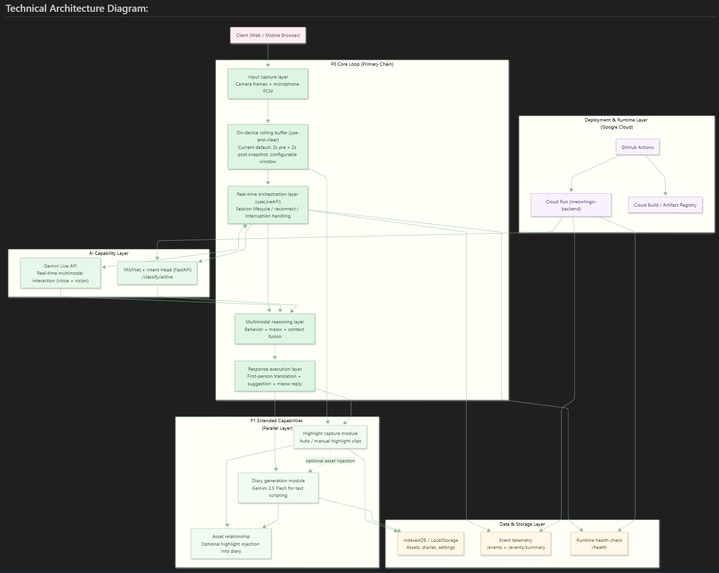
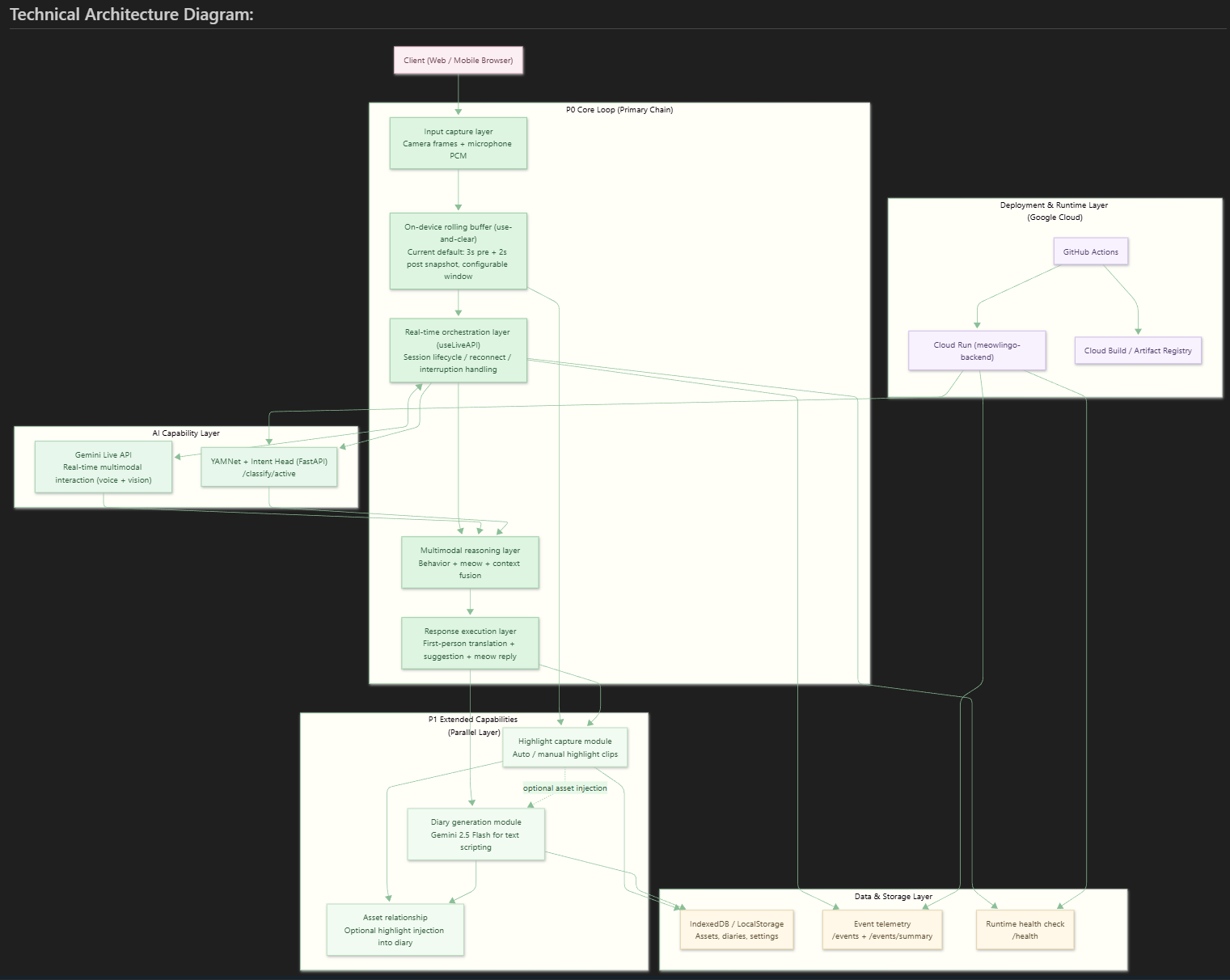
FastAPI + YAMNet adds vocal confidence to Gemini Live. Deployed on Cloud Run; highlights and diaries run parallel to the core loop.
Inspiration
Kitty: "Meow~" Human: "What are you saying? I don't understand." Human: "Come on!" Kitty: "Silly human."
As a cat owner, I’ve lost count of how many times I’ve stared into my cat’s eyes, desperate to understand the meaning behind that specific "Meow" or that subtle tail flick. We love them, but a major barrier remains: we simply can't decipher their intentions across the species gap.
I realized that Multimodal AI (Gemini) possesses the exact two capabilities needed to break this barrier: 1) Inferring intent from visual and audio cues, and 2) Generating high-quality empathetic feedback.
MeowLingo was born from this inspiration—not just to translate, but to serve as an emotional connector. We wanted to build a closed loop of communication that turns a one-way monologue into a two-way dialogue.
What it does
MeowLingo is a real-time multimodal interspecies communication platform. It transforms your device into a translator that works in two directions:
Cat-to-Human Translation (First-Person Perspective): Using the camera and microphone, it continuously captures your cat’s vocalizations and body language. It then "speaks" the cat's thoughts in real-time using one of 4 distinct Personas (e.g., "Sassy Queen", "Clingy Baby").
Human-to-Cat Response (Actionable Loop): It doesn't just translate; it suggests how you should respond. Through the
playCatSoundtool, users can emit specific cat sounds (likegreeting_trillorhappy_purr) to respond to their cat's needs, completing the communication loop.
Beyond the conversation:
- Multimedia Diary: It automatically generates a daily diary from the cat's perspective, combining text, video highlights, and audio.
- Highlight Capture: It intelligently detects and saves fleeting interactions that owners usually miss, ready for social sharing.
How we built it
We architected MeowLingo as a Real-time Core Loop with parallel extension paths, deployed on Google Cloud.
1. The Real-time Core (Gemini Live API)
The frontend (React + Vite) establishes a persistent WebSocket connection to Gemini Live. We stream continuous audio (audio/pcm;rate=16000) and low-latency video frames. The model acts as a "reasoning engine" that fuses these inputs to output audio and text.
The core fusion logic can be conceptualized as: $$ O_{response} = f_{Gemini}(V_{frames}, A_{pcm}, C_{persona}, H_{history}) $$
2. Evidence Injection (FastAPI + YAMNet)
To enhance accuracy for audio-only scenarios, we run a sidecar FastAPI service hosting a YAMNet model. It classifies audio events (e.g., Meow, Purr, Hiss) locally and injects these high-confidence signals into the Live session context as "System Observations," grounding the LLM's hallucinations.
3. Smart Highlight Scoring
For the Diary feature, we implemented an algorithm to automatically select the most relevant video clips. We score each clip ($S_{total}$) based on temporal proximity to interaction events ($\Delta t$) and semantic relevance ($S_{text}$):
$$ S_{total} = 3 \cdot S_{time}(\Delta t) + 2 \cdot \min(S_{text}, 3) $$
Where $S_{time}$ decays as the time gap increases (4 points for $\le 15s$, down to 0 for $> 5min$).
Challenges we ran into
1. The "Context vs. Latency" Trade-off:
Maintaining a continuous persona requires carrying conversation history, but long contexts increase latency. We solved this by implementing a Sliding Window Compression strategy in the session configuration and using sessionResumption handles to recover context after network drops (Error 1006).
2. The "Non-Cooperative User" (The Cat): Cats don't pose for cameras. We found that pure visual recognition often failed when the cat turned away. By integrating the YAMNet audio classification as a secondary modality, we ensured the system could still "hear" the cat even when it couldn't "see" it clearly.
3. Browser Autoplay Policies:
Modern browsers block audio autoplay. We had to carefully design the "Start" interaction flow to unlock the AudioContext and ensure the playCatSound tool could trigger audio responses without user intervention.
Accomplishments that we're proud of
North Star Metric Achievement: We defined our success not just by "connection," but by "Valid Turns per Session" ($V_{turns}$): $$ V_{turns} = \frac{\sum_{i=1}^{N} T_{valid_response}}{N_{sessions}} $$ In our testing, the "Persona" feature significantly increased this metric, as users stayed longer to hear their cat's "personality."
Robust Fallback Mechanisms: We built a 3-level degradation strategy (Level 1: Full Live; Level 2: Audio-only; Level 3: Text fallback), ensuring the app remains usable even on unstable mobile networks.
Emotional Impact: Seeing a user laugh when their "Grumpy Boss" cat finally "spoke" to them was our biggest validation.
What we learned
- AI is a Connector, Not a Replacement: We learned that users don't want AI to simulate a pet; they want AI to help them understand their real pet. The value lies in the bridge, not the bot.
- Latency is the Enemy of Humor: For the "translation" to feel funny and real, it must be instant. Optimizing the WebSocket stream was crucial for preserving the comedic timing of the cat's reaction.
What's next for MeowLingo
- **Optimize models, algorithms, and prompts for more precise recognition and generation.
- v2.0 Mobile Native: Porting the experience to iOS/Android for better background keep-alive support.
- Social Sharing: Generating one-click shareable videos with the translated "subtitles" burned in.
- Multi-Pet Support: Updating the prompt engineering to distinguish between multiple cats (e.g., "Simba" vs. "Nala") in the same frame.
Built With
- artifact
- cloud-build
- fastapi
- gemini-live-api-(@google/genai)
- google-cloud-run
- react
- sqlite-(better-sqlite3)
- tailwind-css
- tensorflow-hub-(yamnet)
- typescript
- uvicorn
- vite



Log in or sign up for Devpost to join the conversation.