-
-
-
-
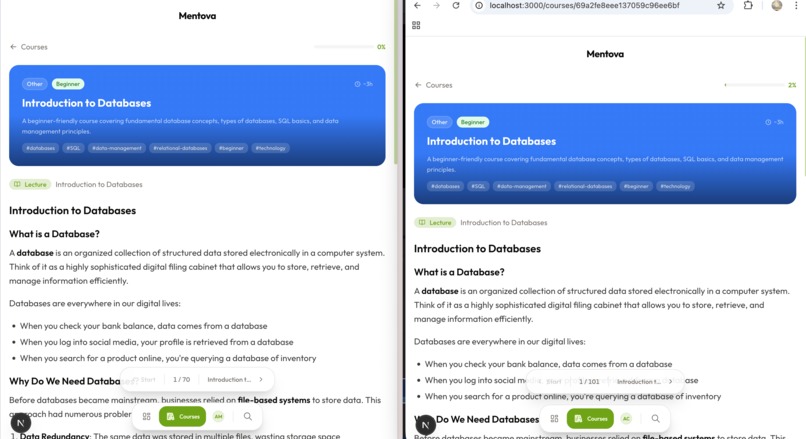
Two users can have different content for the same course!
-
-
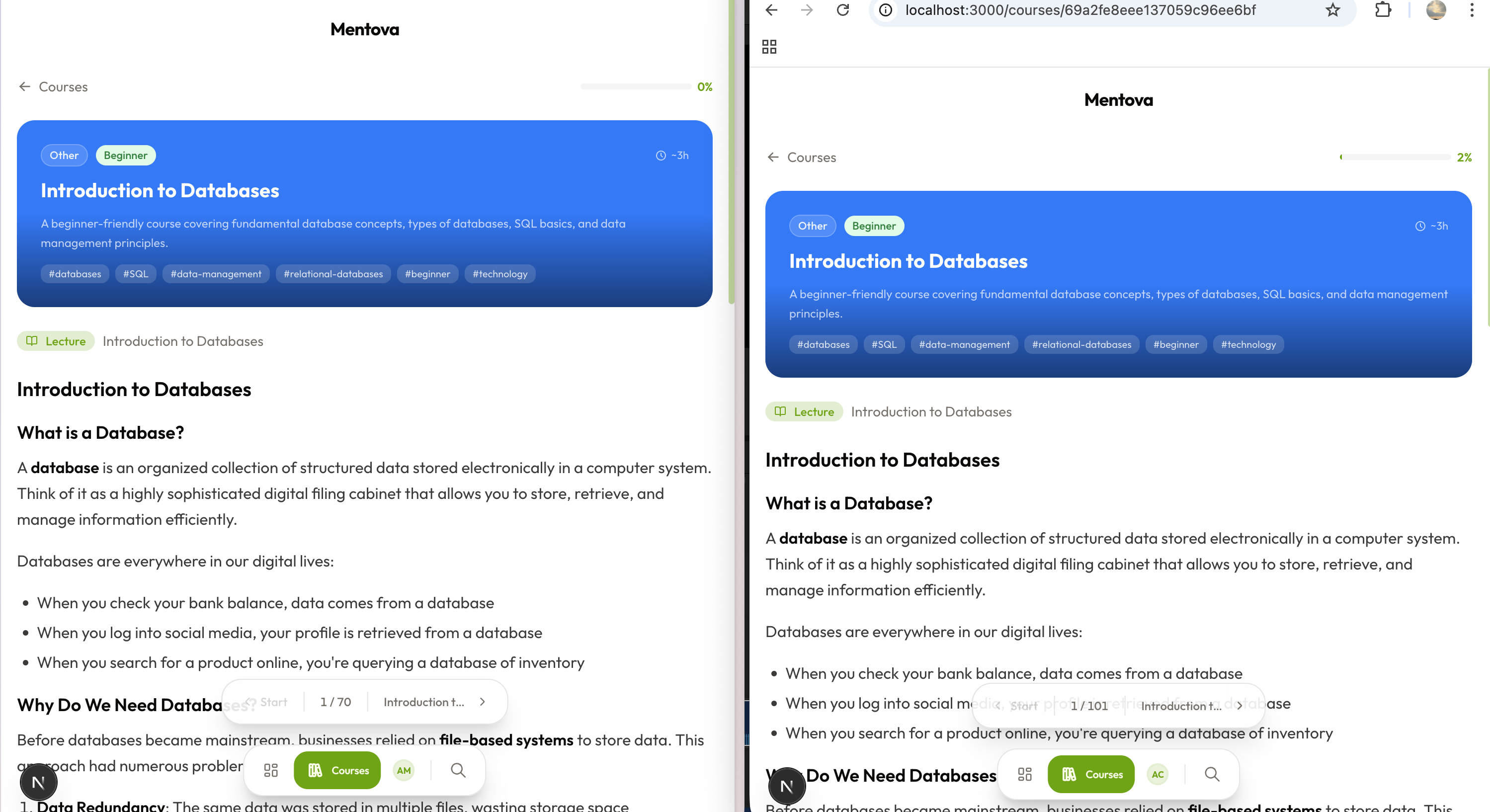
Mentova is a third-generation education platform with features such as context awareness, intelligent agent, and deep integration, where Artificial Intelligence controls the environment, not just chat.
Inspiration
Lecture slides make no sense, and YouTube videos are either too simple or too hard, too boring or too entertaining. There is simply nothing that you can use right away that just works.
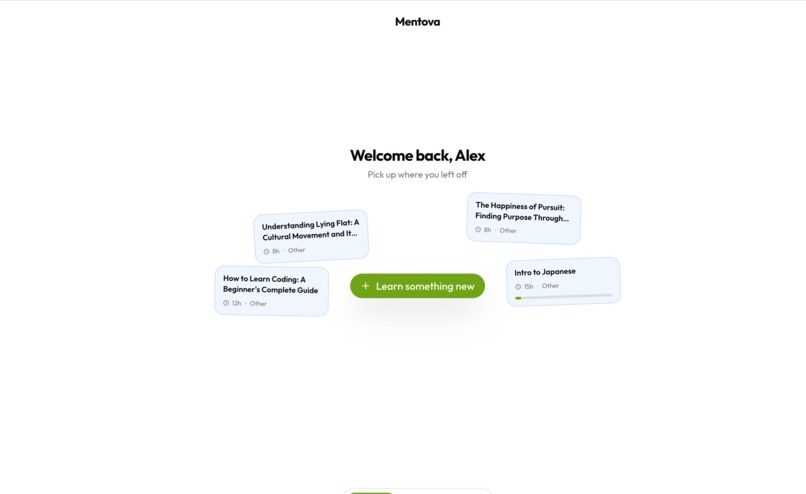
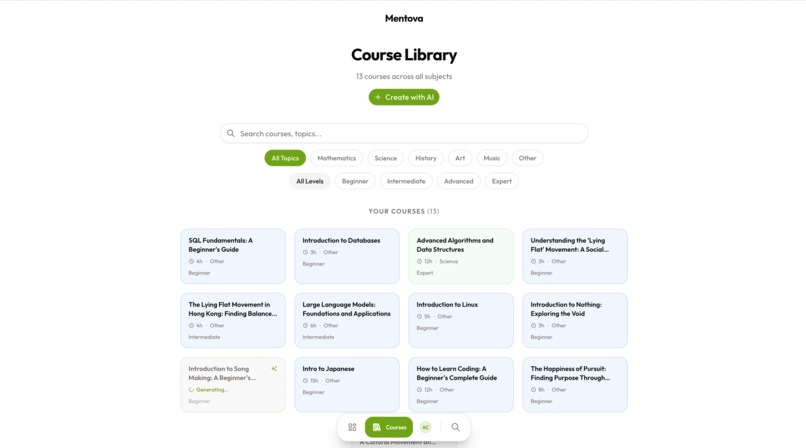
What it does
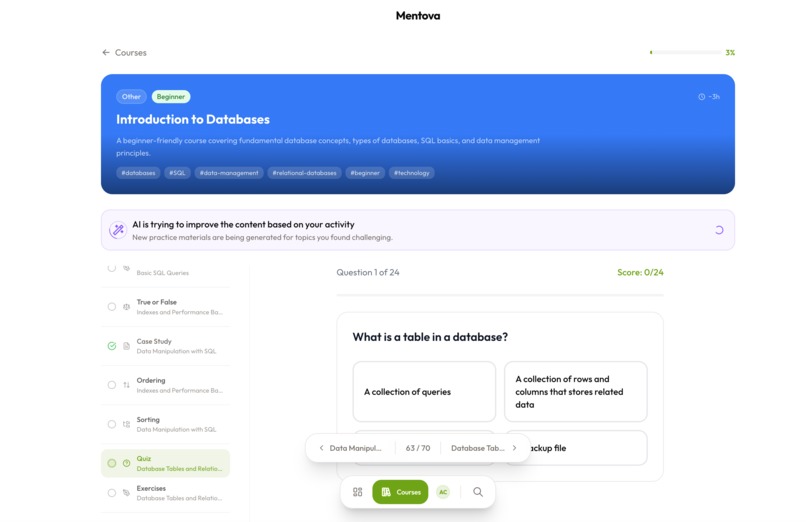
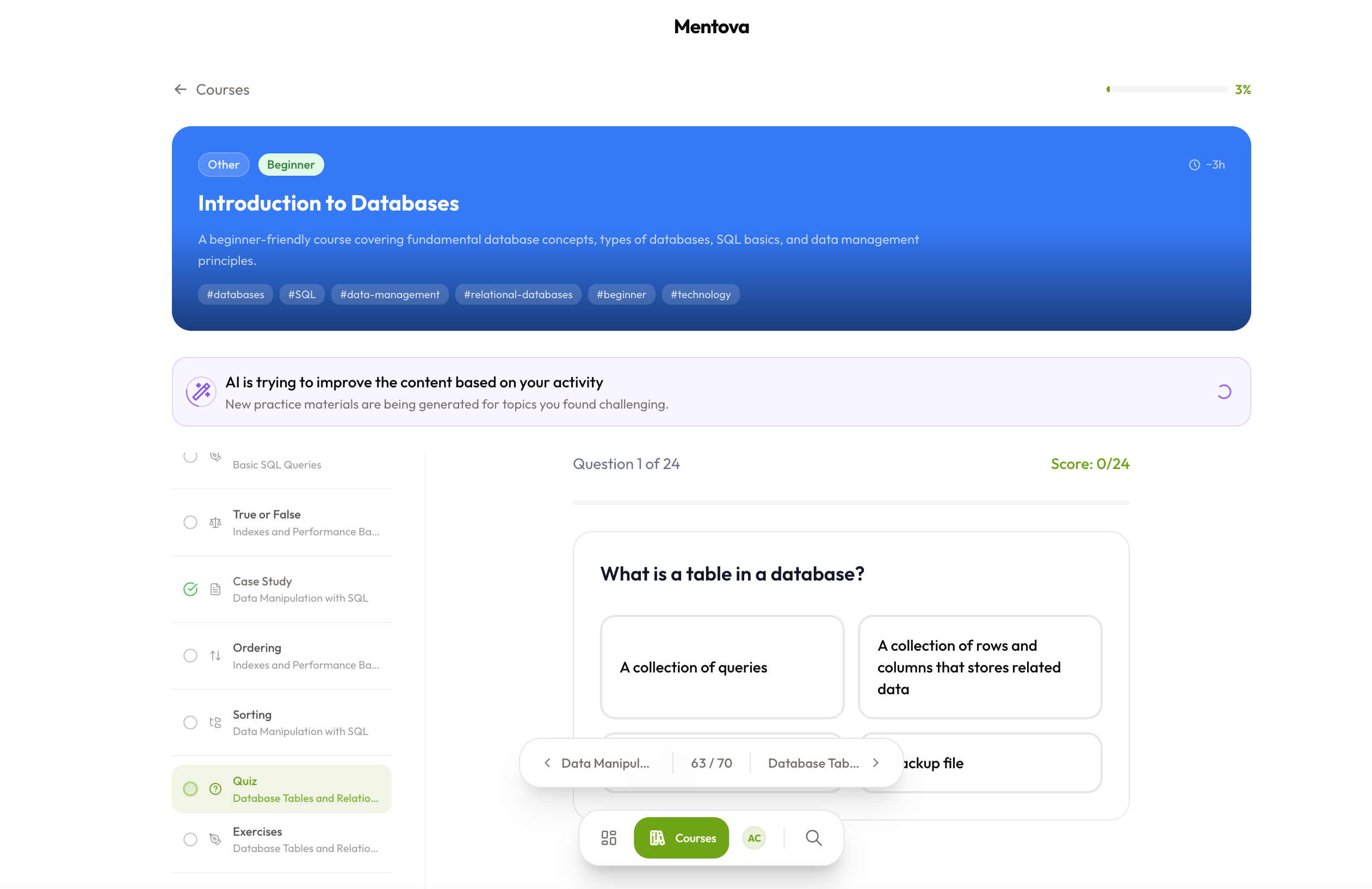
Mentova generates an entire course on whatever you would like to learn, at the difficulty you'd like it to be. With flashcards, MCs, and knowledge checks, we make sure the learning experience is tailored for you.
How we built it
Mentova runs on a Python 3.13 + FastAPI backend, a Next.js 16 frontend, MongoDB for storage, and Redis — all containerised with Docker Compose. The AI layer uses MiniMax M2.5 via an OpenAI-compatible client, with Exa providing real-time web search to ground generated content in up-to-date sources.
Course generation happens in two phases. Phase 1 runs synchronously: we fetch relevant web context via Exa, inject it into the prompt, and have the LLM produce a course outline and the first lecture in one shot — fast enough to show the user something immediately. Phase 2 runs in the background: ten material types (flashcards, quizzes, fill-in-the-blank, matching, ordering, case studies, and more) are generated in parallel across every subtopic using asyncio.gather, throttled by a semaphore and retried with exponential back-off. The frontend polls a Server-Sent Events endpoint until generation is complete.
Every LLM call uses forced tool-calling with a hand-crafted JSON schema per material type, which gives us reliable structured output even under parallel load. On the backend, we replaced exception-based error handling with typed union returns (T | ServiceError) so errors flow as plain values through the stack without try/except chains.
Challenges we ran into
Getting consistent structured output from the LLM at scale was the first real wall we hit. Asking the model to "return JSON" works most of the time — until it doesn't, and a single malformed response breaks a whole subtopic. Switching every call to forced tool-calling with explicit schemas fixed this almost entirely.
Parallelising generation across ten material types and multiple subtopics introduced race conditions around which tasks were already running. We had to be deliberate about using an in-memory set as a lock to prevent the same subtopic from being regenerated concurrently when multiple adaptive triggers fired close together.
The SSE endpoint for real-time generation status was also trickier than expected — browsers can't set custom headers on EventSource connections, so we had to add a ?token= query parameter fallback specifically for that route.
Accomplishments that we're proud of
We're proud that the full generation pipeline — outline, lecture, and all ten material types — completes in under a minute for a fresh course, and that the experience feels genuinely responsive because Phase 1 returns fast enough for the user to start reading while the rest builds in the background.
The journey system is something we think is underrated: rather than dumping all materials at once, content is surfaced in a spaced, interleaved order — lecture and flashcards first, with heavier review types appearing after a subtopic offset — so the structure itself reinforces learning without the user having to think about it.
We're also proud of shipping a parent dashboard with supervised child accounts and per-child progress breakdowns within the hackathon window.
What's next
We have made attempts to track user behaviour, including on-screen time and performance on lessons, and, together with user feedback, update course content accordingly.

Log in or sign up for Devpost to join the conversation.