mento.ai - AI-Powered 3D Learning Companion
mento.ai - AI tutor that listens, understands, and teaches in real time.
Shaping the future of education with a human-like 3D avatar that explains, adapts, and guides students through doubts with clarity and presence.
Inspiration
Millions of students worldwide struggle to access timely, personalized learning. Videos, forums, and MOOCs often leave gaps; live tutors are expensive or unavailable. We built mento.ai to bring human-like guidance into every learner’s pocket - an always-on tutor that sees, listens, and explains. mento.ai fills the gap left by text-only AI assistants by creating a private, interactive, and trustworthy space for learning.
What it does
mento.ai is an AI-powered learning companion that:
- Understands questions through voice, text, and context in real time.
- Responds using a lifelike 3D avatar that explains concepts clearly and demonstrates step-by-step solutions.
- Breaks complex topics into intuitive, evidence-backed explanations for better comprehension.
- Guides ongoing conversations with follow-ups to ensure understanding, powered by LLM-driven replies with TTS and realistic lip-sync.
- Prioritizes privacy: processes sensitive data locally when possible and stores session memory only with consent.
- Escalates or suggests human instructor help when a topic requires deeper guidance.
mento.ai brings presence back into learning - not just answers, but a patient tutor that adapts to you.
How we built it
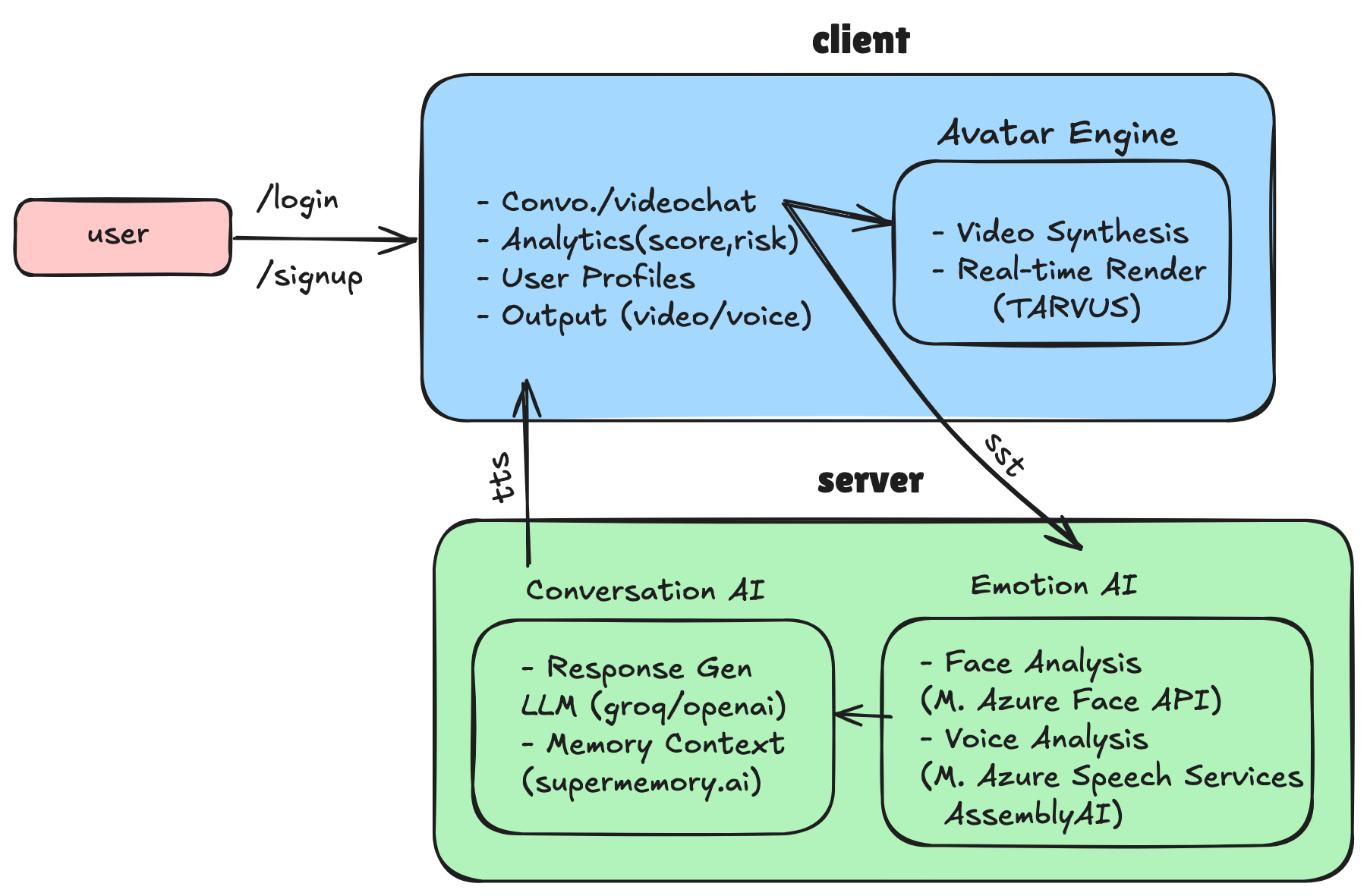
Frontend
- Framework: React 18 + TypeScript (Vite)
- Styling: Tailwind CSS
- Animation: Framer Motion
- Avatar / Video: WebRTC + WebGL / three.js
- Speech: Web Speech API and TTS integrations
Backend & Services
- Runtime / Framework: Node.js + Express.js
- Docs: OpenAPI / Swagger
- Datastore: MongoDB / PostgreSQL (deployment dependent)
- Microservices: Python-based inference services for adaptive explanations
- Security: CORS, env-based configs, express-rate-limit
AI & Integrations
- Question Analysis: LLM-based context understanding
- TTS: Eleven Labs (expressive synthesis)
- Avatar: Three.js/WebGL rendering for lifelike gestures
- Memory / Context: Opt-in session memory for continuity
- On-device inference: TensorFlow Lite / ONNX for privacy-preserving local models
Design & Safety
- Edge-first design minimizes sensitive data transfer.
- Explicit consent flows, pseudonymized analytics, and optional human oversight.
- Accessibility: captions, voice-first interactions, large-text UI.
Challenges we ran into
- Clarity vs. natural pacing: balancing explanations with engaging avatar gestures.
- Privacy vs. personalization: ensuring local processing without losing tutoring accuracy.
- Scope & reliability: guaranteeing helpful guidance without overstepping to human teacher roles.
- Adaptive conversation: tuning avatar, text, and voice feedback to respond appropriately to diverse learners.
- Latency & UX: keeping real-time responses smooth across devices.
Accomplishments that we're proud of
- Working prototype with real-time 3D avatar teaching, STT, and LLM-driven explanations.
- Privacy-first pipeline with on-device processing and opt-in memory.
- Cross-functional core team ready for rapid prototyping and user testing.
- Early validation showing improved engagement and understanding compared to static videos.
What we learned
- Trust is earned by design: clear explanations, natural pacing, and expressive gestures improve engagement.
- Local processing builds confidence: learners prefer privacy without losing interactive quality.
- Safe guidance is essential: conservative escalation ensures students are supported appropriately.
- Adaptive explanations improve learning: voice, text, and context cues outperform static answers.
- Pilot programs accelerate insights: working with educators is crucial for ethical and effective validation.
What's next for mento.ai
Short-term (0–3 months)
- Pilot with 50+ students to measure understanding, engagement, and retention.
- Expand avatar personalization (voice, appearance, gestures) and improve lip-sync.
- Optimize on-device inference for privacy and speed.
Mid-term (3–9 months)
- Develop dashboard for teachers/mentors to review student interactions safely.
- Conduct fairness and accessibility audits across diverse learners.
- Enhance personalization via safe opt-in memory and adaptive learning paths.
Long-term (9–18 months)
- Collaborate with schools and universities for larger-scale pilots and feedback.
- Explore energy-efficient architectures for scalable deployment.
Built With
- eleven-labs-tts
- express.js
- framer-motion
- llm-(groq-/-openai)
- mongodb
- node.js
- onnx
- postgresql
- python-microservices
- react
- rest-apis
- supermemory.ai
- tailwind-css
- tensorflow-lite
- three.js
- typescript
- web-speech-api
- webgl
- webrtc
 Bello")

Log in or sign up for Devpost to join the conversation.