-
Homepage
-
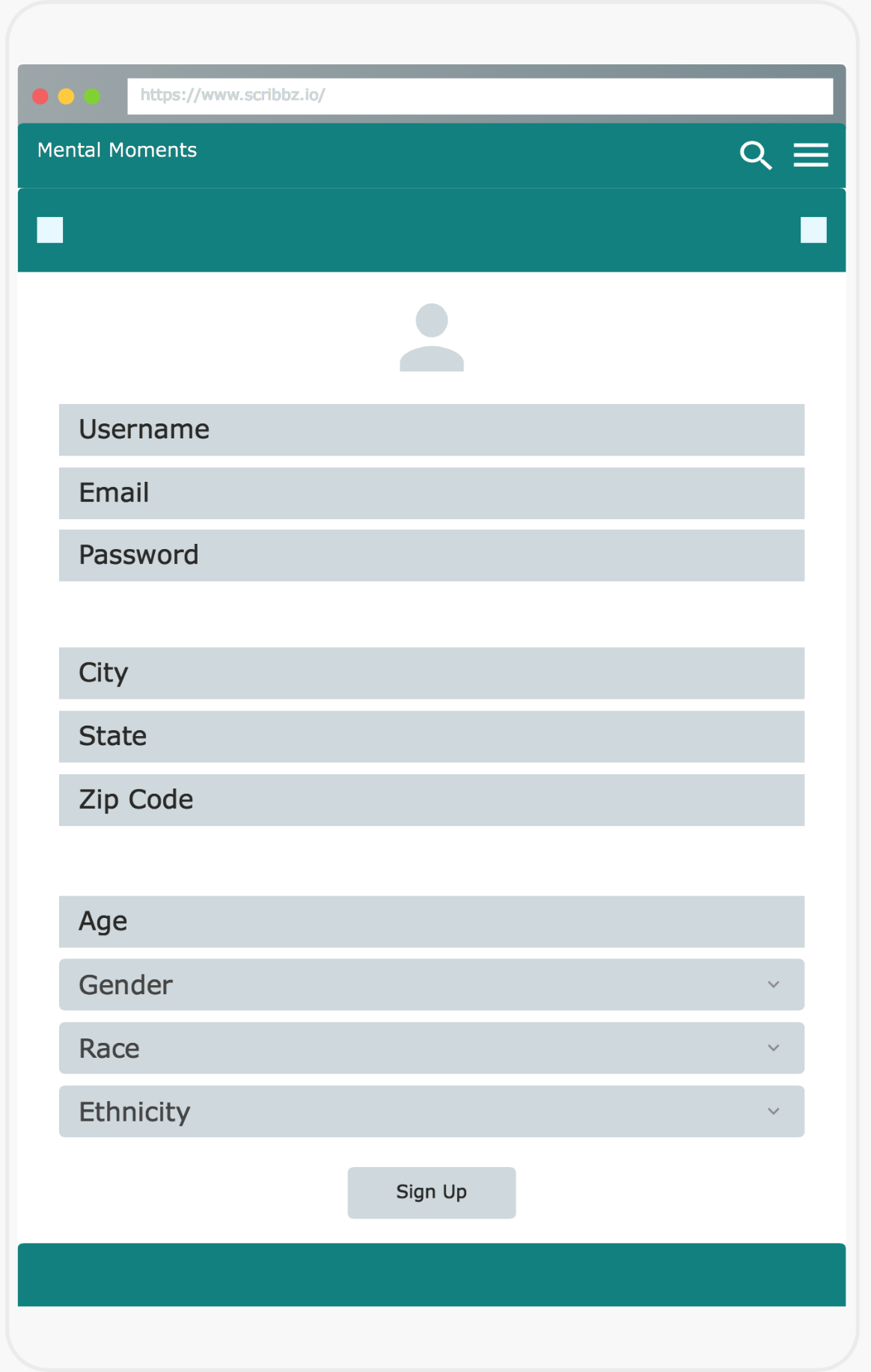
Sign Up Form
-
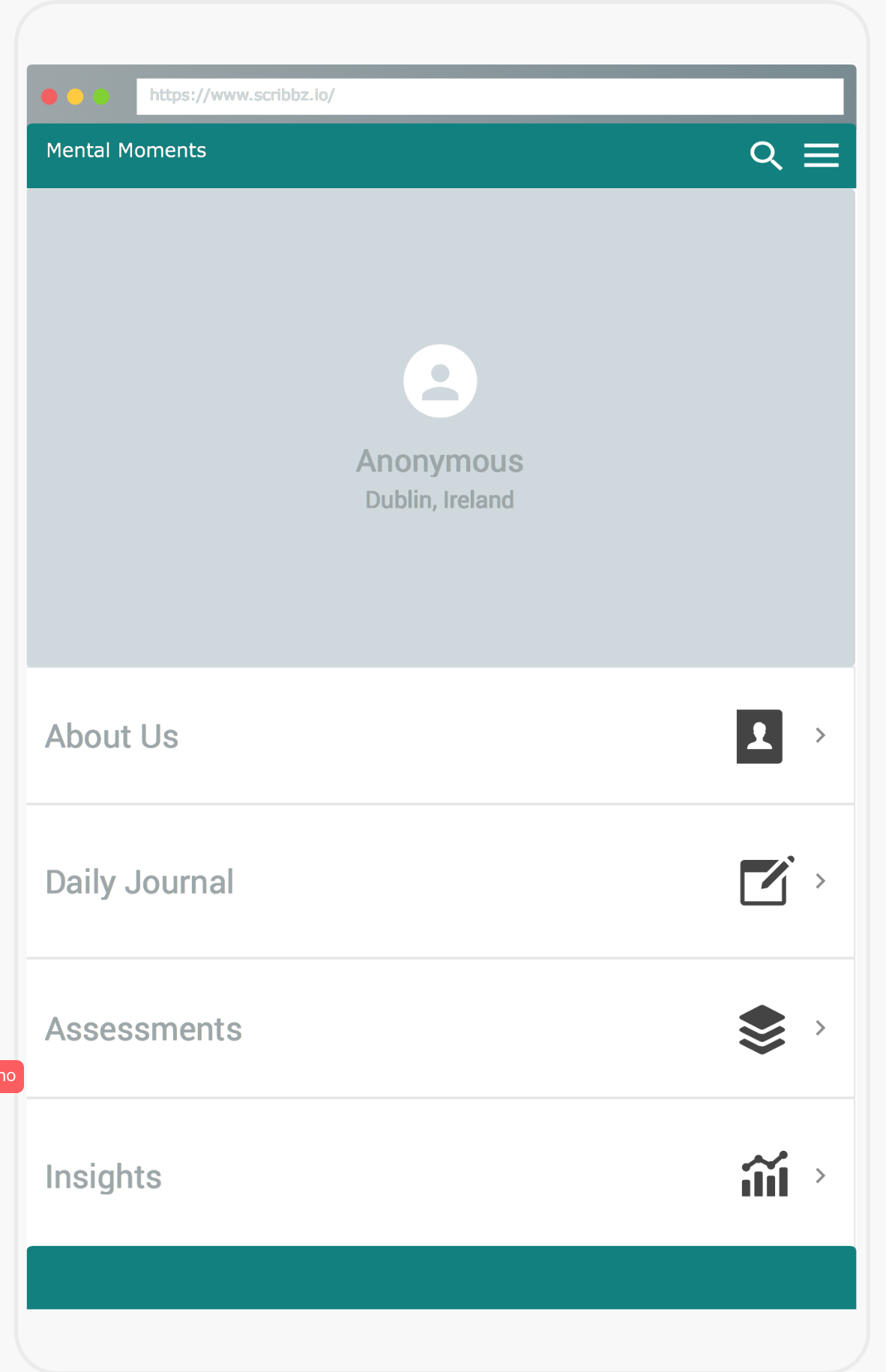
Account View
-
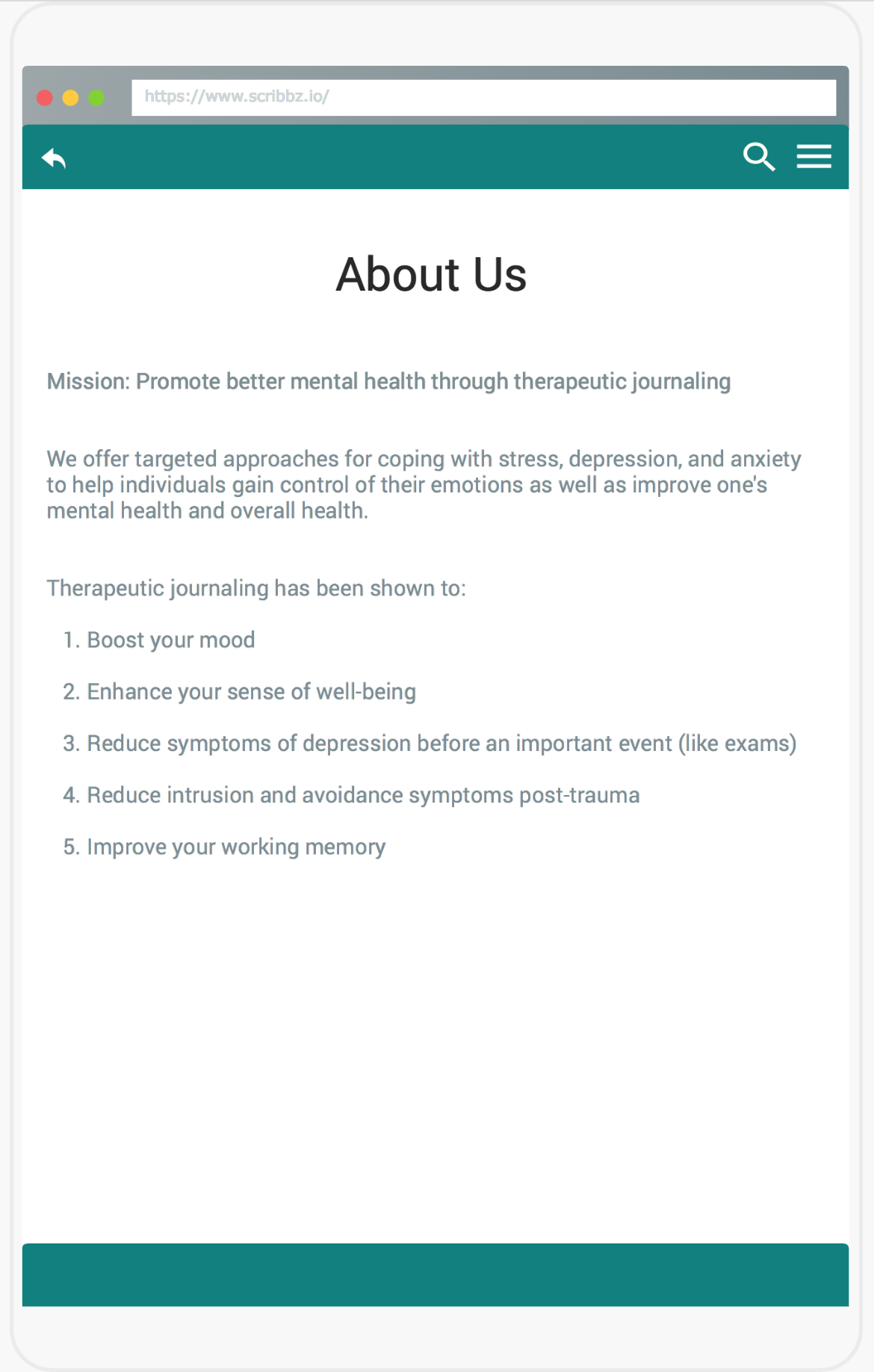
About Us
-
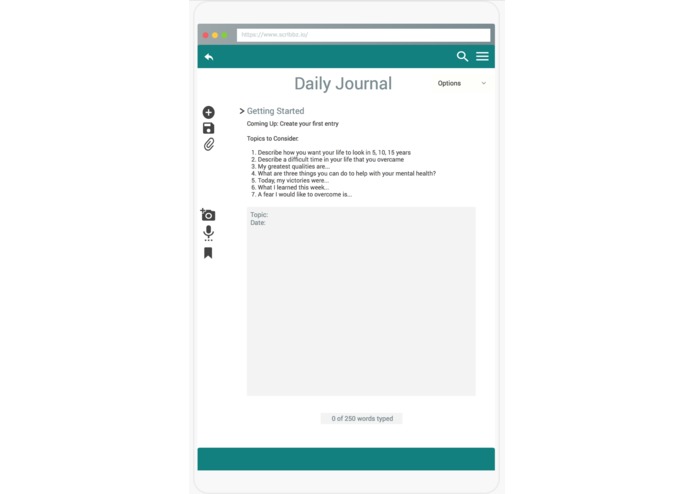
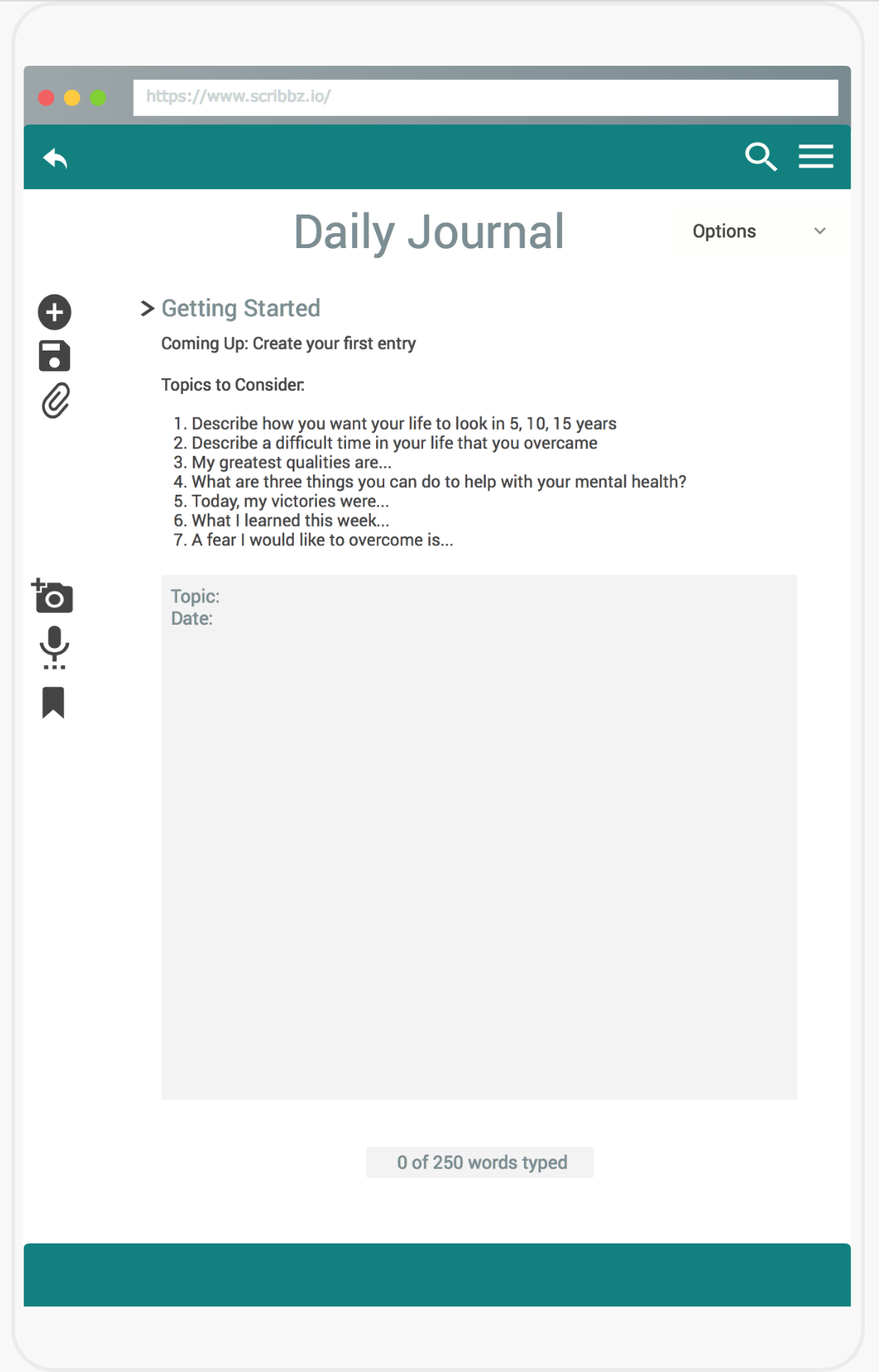
Journal
-
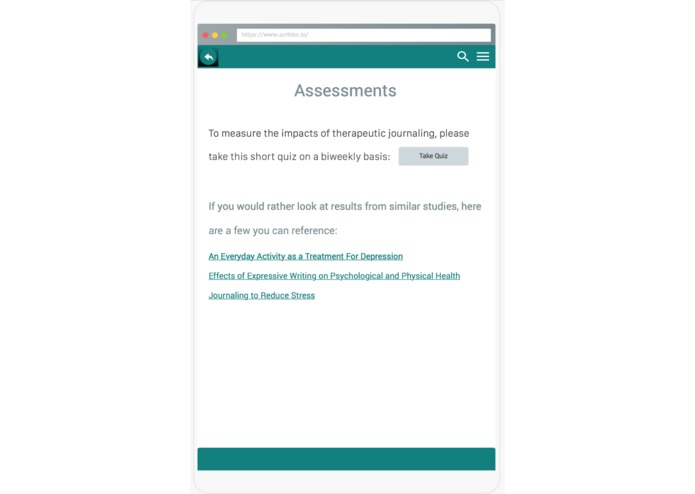
Assessments
-
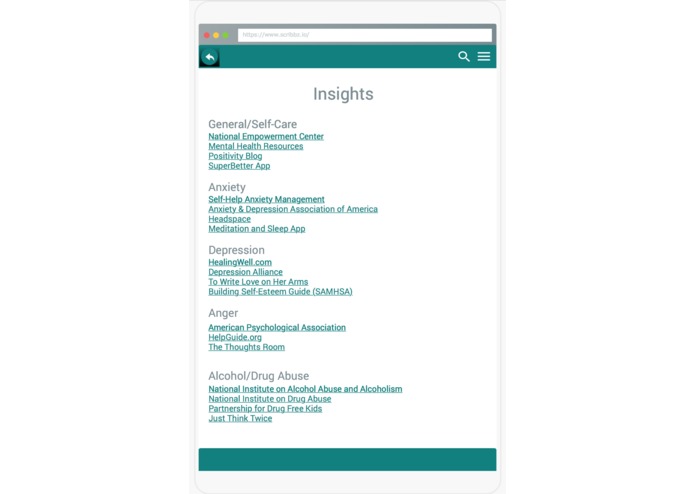
Insights
Inspiration
Based on our personal experiences with mental health, we realized the importance of prioritizing battling the stigma and limited access to mental health guidance. Mental Moments is a journaling app aimed towards providing mental health resources to individuals who normally do not have them (whether it be because of financial burdens, cultural or societal stigma, professional bias, or a number of other barriers) as well as providing mental health data about underrepresented demographics to the greater medical community. To achieve this, we have designed a word-frequency-analysis program to analyse a user's input in a virtual joural and use the data to provide visuals for the user to immediately see whether they may be at risk for abnormal feelings of depression, anger, anxiety, or suicidal ideation; it is planned to also suggest to users mental health resources (or avenues to finding those resources) in response to data collected on their mental state from their written input. Machine learning is also planned to be utilized to create more robust methods of analysing user input by analyzing entries sentence by sentence, rather than just by single words. Users are encouraged to take a proven DSM-V Assessment questionnaire, and we will use the scores from questions to create weekly or biweekly progress reports for users based also on journal entry data. The users can thus see in real time the progress they are making, therefore empowering them to seek further resources if trends indicate a need to do so, or saving them both time and money if they see a drastic improvement by the journaling process.
What it does
Python: The Python word-frequency-analysis program works by taking in a string input and comparing each word in said string to words in the following four categories of negative emotions: “Anger”, “Depression”, “Anxiety”, and “Suicidal Ideation”. Words for each category were found online through taking synonyms of commonly known words associated with each emotion. The program calculates a “prediction” of what the user may be feeling as follows: if the combined (sum of) ratios of “negative” words to “normal” or non-“negative” words surpasses a threshold of 2.5%, the user is seen as experiencing abnormally negative emotions. If it is predicted that the user is experiencing a “negative” emotional state, the program will output what the most frequent of negative emotions is out of the four categories stated prior. The threshold of 2.5% was calculated by finding the average frequencies of negative words in four different negative vocabulary-containing songs: “A Team” by Ed Sheeran, “1-800-273-8255” by Logic, “Kim” by Eminem”, and “Mad World” by Gary Jules/Tears for Fears. The average combined frequency of negative vocabulary was around 4% for these very negative vocabulary-containing songs, so the threshold was put slightly lower at 2.5%. The program also gives pie charts for the users on their negative versus normal word frequencies, as well as on proportion breakdowns of the four different categories of negative words.
MATLAB**: The executable file uses a deep learning long short-term memory (LSTM) network, a type of neural network to categorize journal entries into either a positive or negative mood. Using word embeddings the classifier can capture semantic details including long-term word dependencies and similar words even if they don't look similar. The MatlabMoodDetectionTraining was used to train a dataset of over 20,000 tweets categorized as either negative or positive. After training with 90% of the dataset we crossvalidated with the remaining 10%, chosen randomly. The accuracy of the resulting binary classifier, TrainedMoodNet.mat, came out to 73.4%.
**The executable file can be found separately in a Google Drive link and the associated files (doc2sequence.m, leftPad.m, TrainedMoodNet.mat, and wordembedding.mat) can be found here in the gitrepo. The associated files must be saved in the same folder as the executable in order to work.
How we built it
We utilized machine learning concepts in Python to develop predictive modeling for thresholds and Matlab to develop deep learning using word embeddings. We also used FluidUI to develop a prototype of what our web application would look like.
Challenges we ran into
Our datasets were large in their file sizes, so the Matlab deep learning code would take half an hour to over an hour to run through training. We also did not have much web application development experience, so we did not know how to use Bootstrap or Firebase, which would have been the most efficient way to build a proof-of-concept.
Accomplishments that we're proud of
We learned how to use MatLab to build a customized machine learning algorithm for our project. We also learned how to use Python to do some predictive modeling for thresholds. Now, we know how we would like our web app to be designed, along with any changes we know would benefit user experience. Some takeaways would be the amount of teamwork and knowledge we had in such a short period of time.
What we learned
We learned how to do data visualizations through Python and MatLab. Additionally, learned how to develop a web application prototype through FluidUI.
What's next for Mental Moments
- Build a web application with Bootstrap and Firebase
- Connect backend of the web application with the Python and Matlab program files
- Build a platform to leverage complete phrases
- Implement more robust algorithms

Log in or sign up for Devpost to join the conversation.