Inspiration
The need for a standardized way to objectively compare AI memory providers like SuperMemory, Mem0, and Zep, as there was no unified benchmarking platform for evaluating long-term context retention and semantic retrieval.
What it does
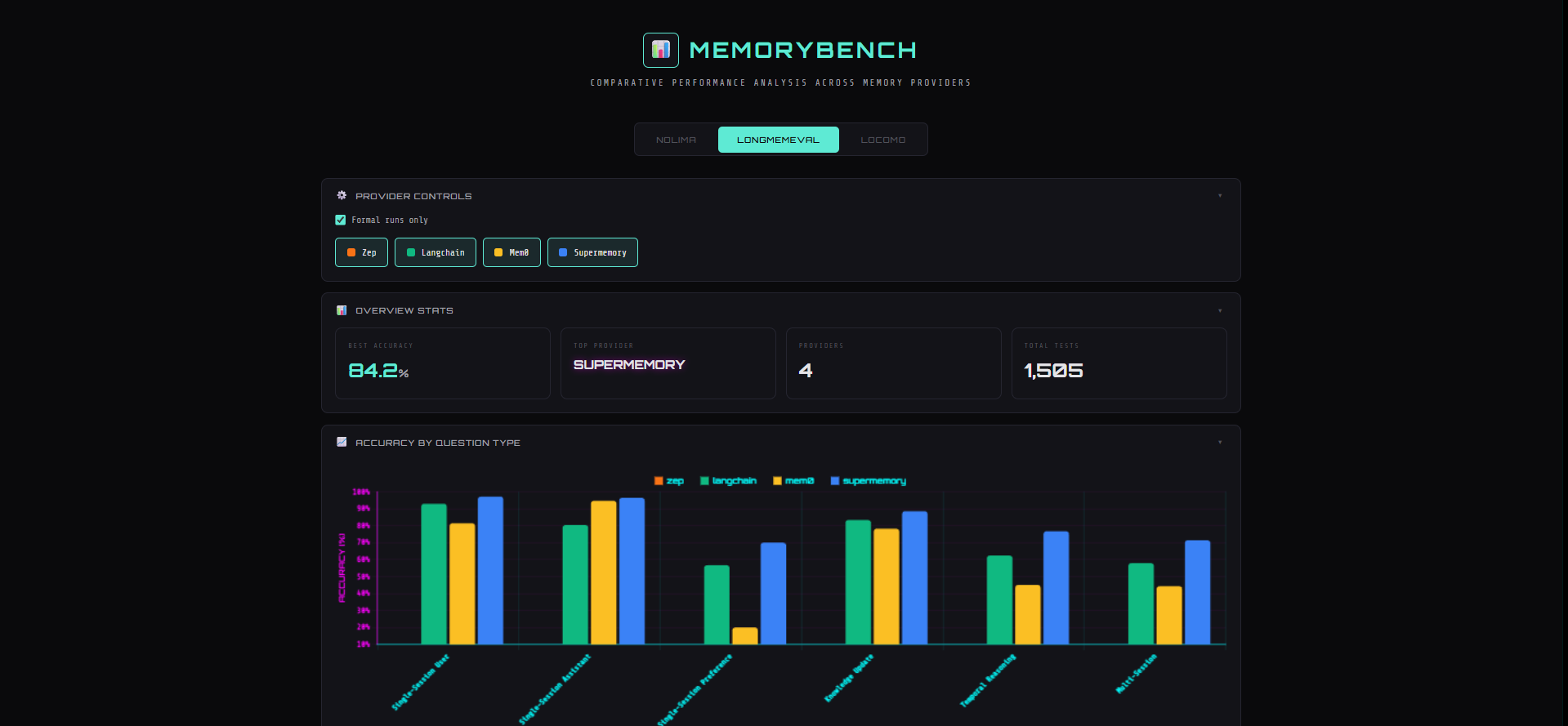
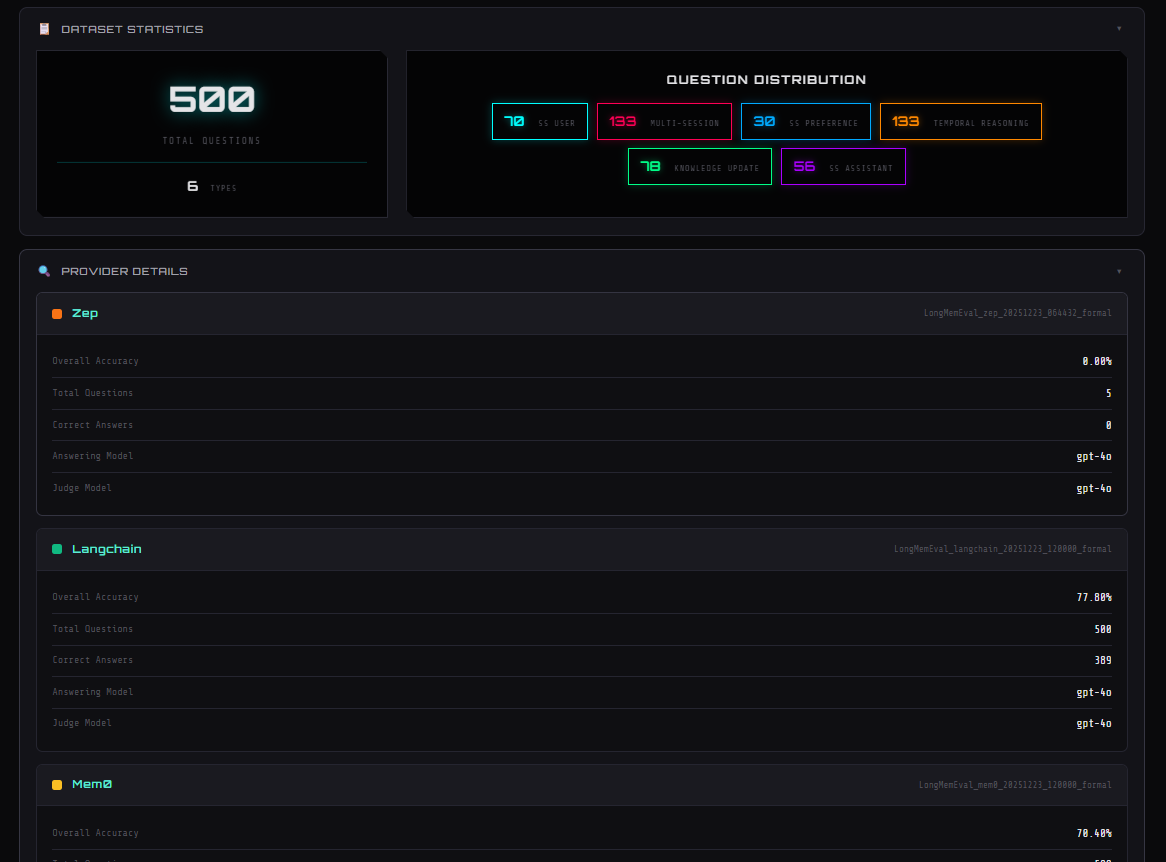
MemoryBench evaluates and compares AI memory providers across three standardized benchmarks (NoLiMa, LongMemEval, LoCoMo) with an interactive dashboard, testing semantic retrieval, long-term memory, and conversational context maintenance. with the option to add more benchmarks or agents easily in the future
How we built it
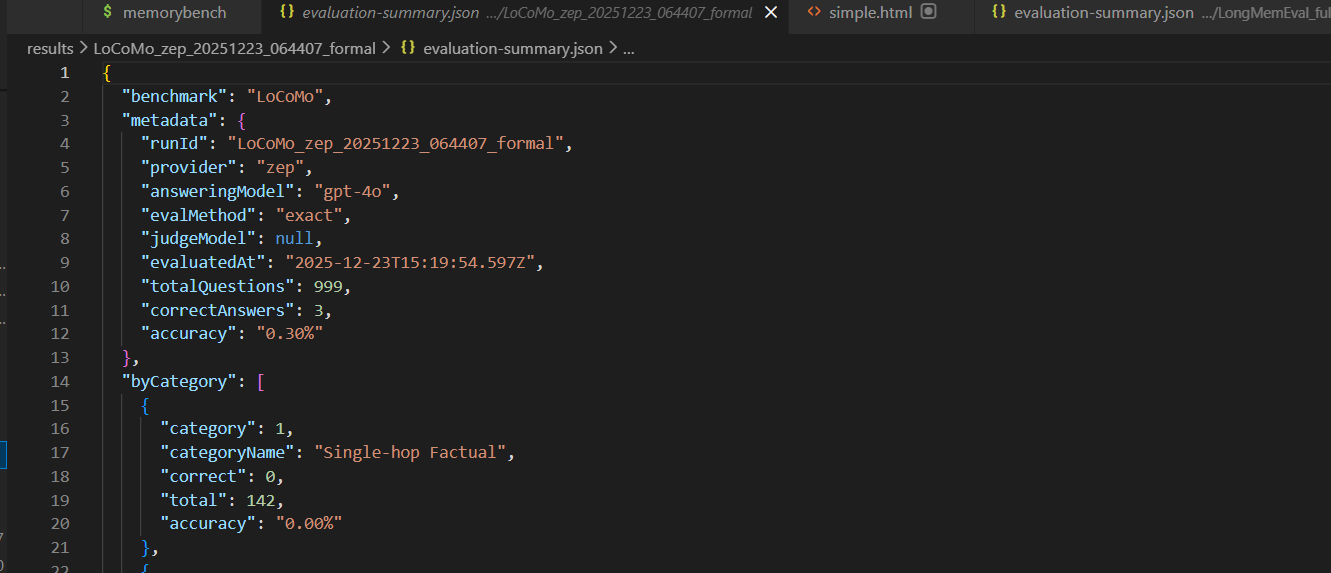
Built with Bun and TypeScript using factory patterns for auto-discovery, template methods for consistent execution, comprehensive checkpointing, multi-model LLM support, and a Chart.js visualization dashboard.
Challenges we ran into
Managing diverse provider APIs, implementing reliable multi-level checkpointing, ensuring consistent LLM-as-judge evaluation, handling API rate limits, and accurately measuring semantic retrieval without exact string matching.
Accomplishments that we're proud of
Created an extensible platform where new providers require just one file, with production-ready checkpointing, three comprehensive benchmarks, interactive visualizations, and full type-safety across the codebase.
What we learned
Factory patterns with auto-discovery enable true extensibility, checkpointing is crucial for long-running benchmarks, and clean abstraction layers allow providers and benchmarks to evolve independently.
What's next for MemoryBench
Expanding to more benchmarks and providers, adding latency and cost metrics, building a public leaderboard, and creating tools for users to design custom domain-specific memory benchmarks.

Log in or sign up for Devpost to join the conversation.