-
-
MemoryBench
-
Research snapshot
-
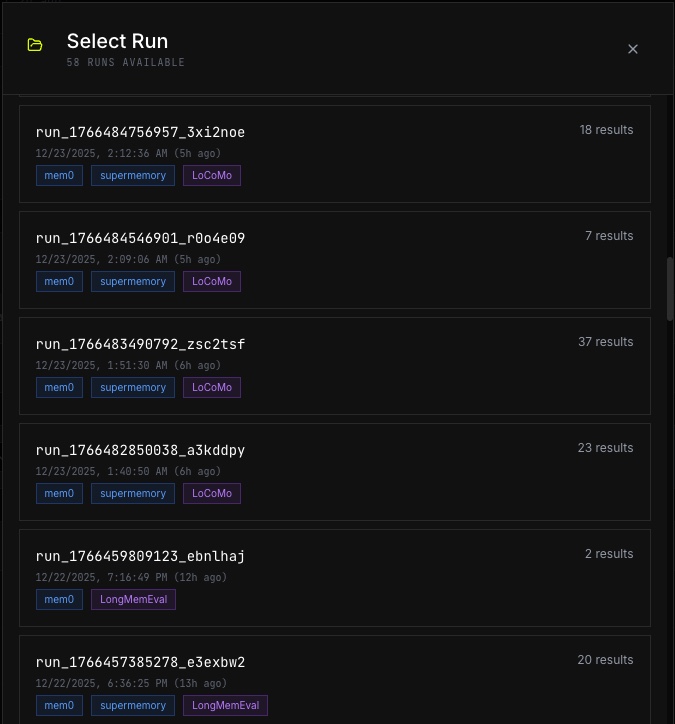
Run Selection
-
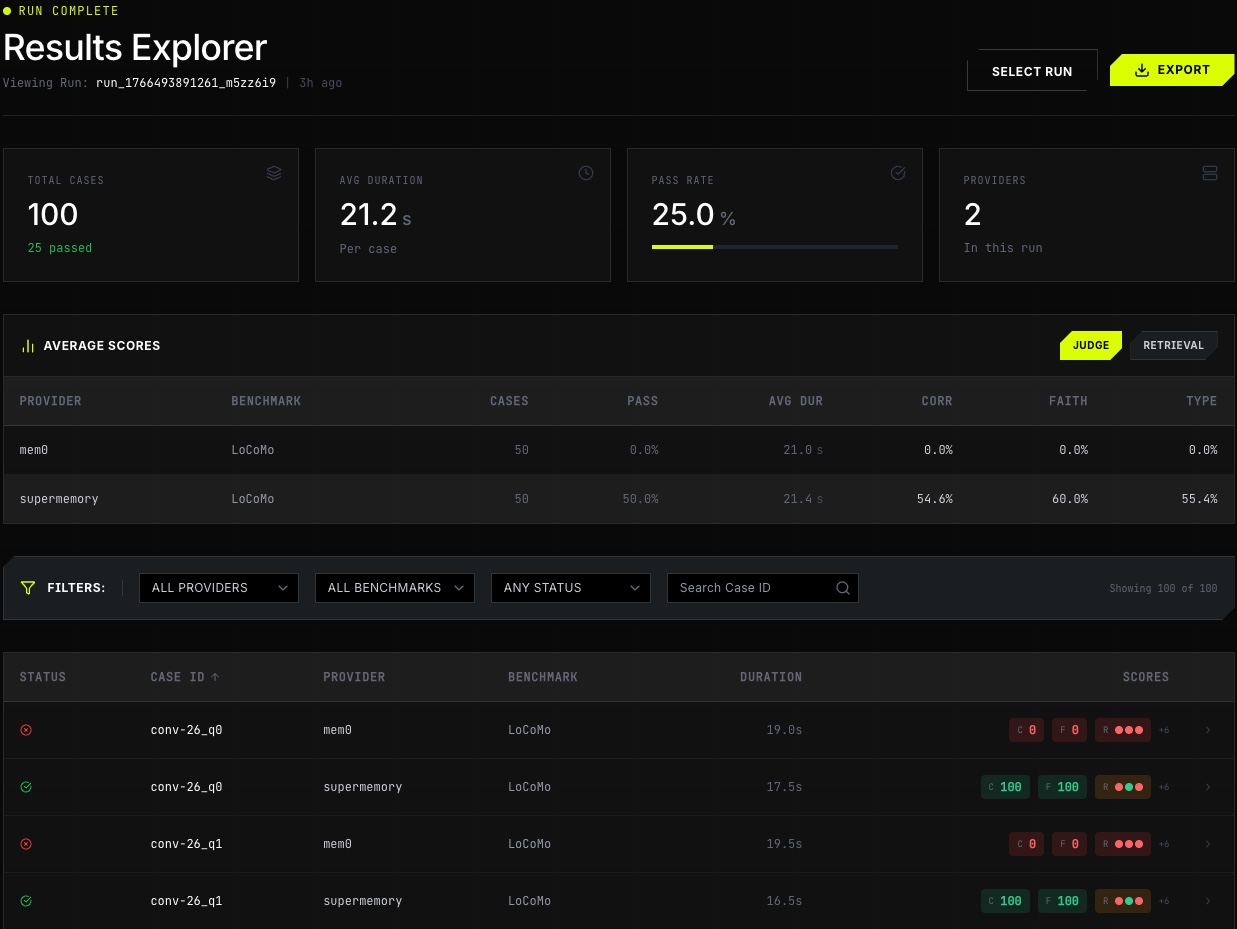
Results Explorer
-
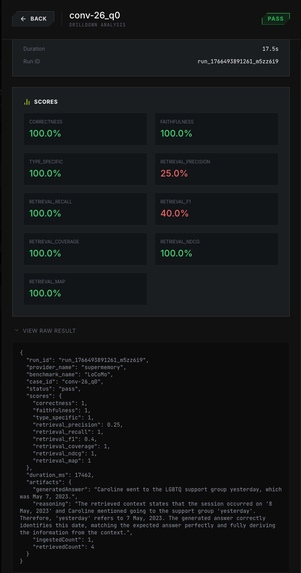
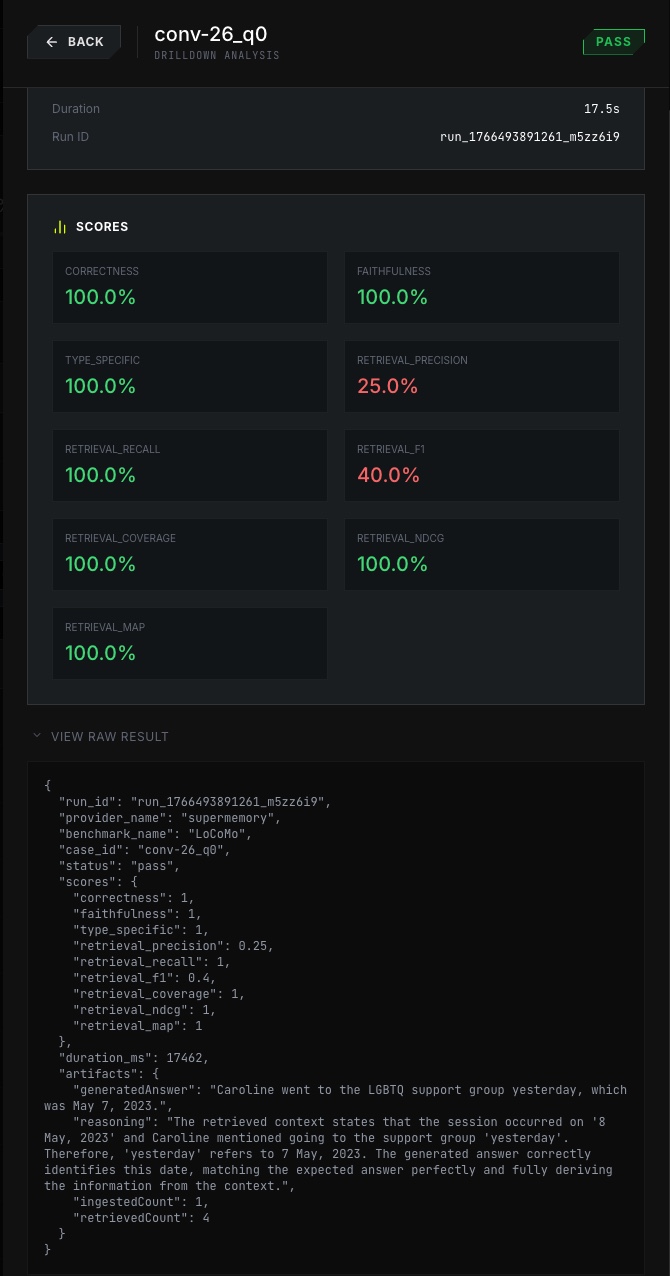
Raw Results
MemoryBench — Universal Memory Provider Benchmarking + Results Explorer
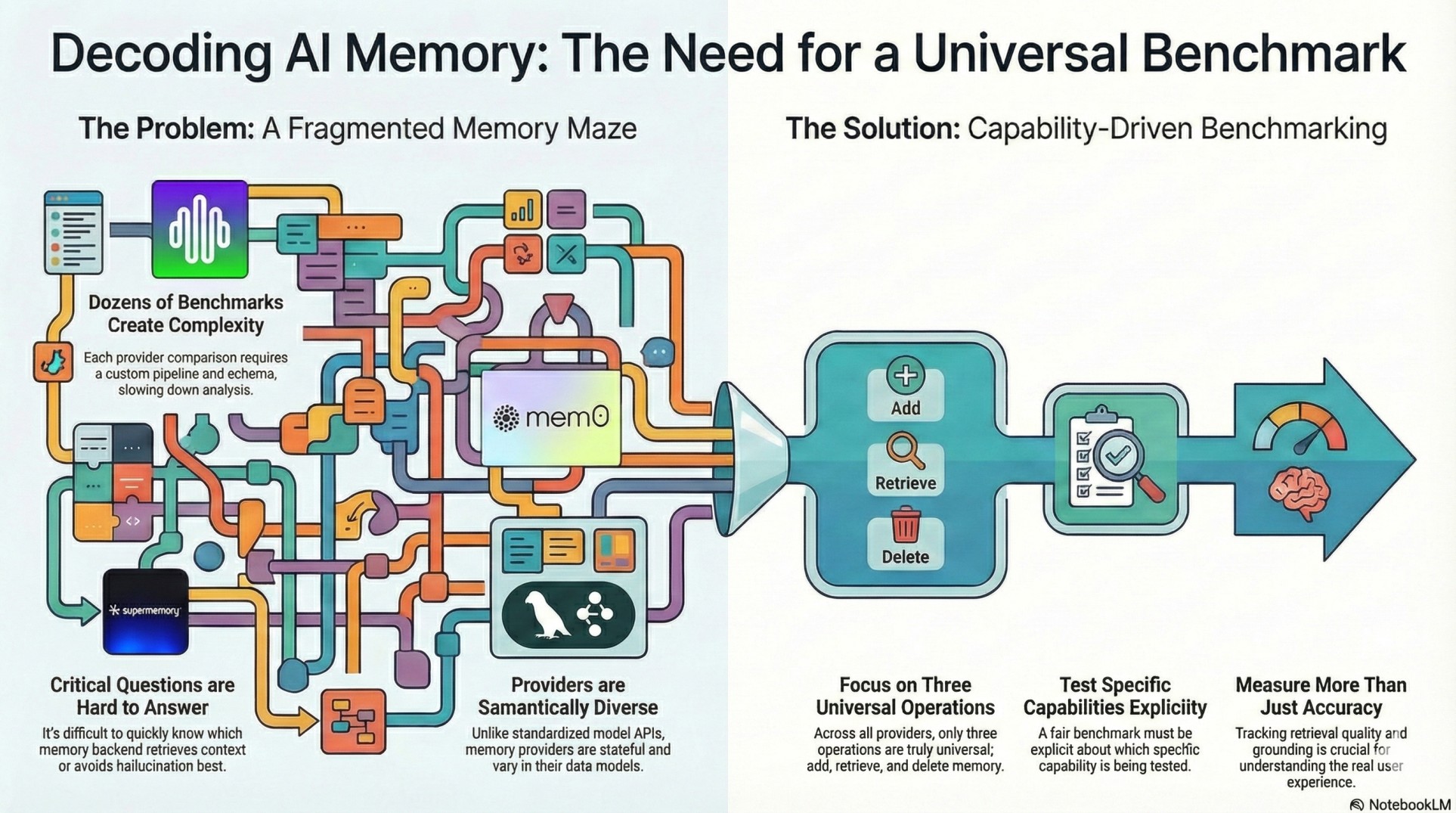
Problem we tackled
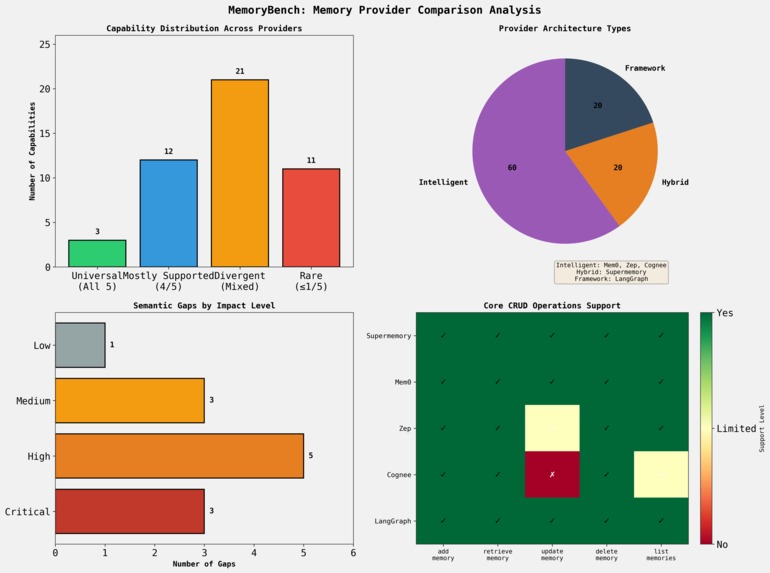
The long-term memory ecosystem is fragmented. Unlike model providers (prompt → completion), memory providers are stateful and vary widely in:
- data model (chunks vs facts vs graph entities),
- update/delete semantics,
- async indexing and visibility delay,
- retrieval/ranking behavior.
Because of this, comparing providers (or adding benchmarks) is slow and usually ends up as one-off scripts plus unreadable JSON. We wanted a general, adaptable system where adding a provider or benchmark is repeatable and comparisons are clear in seconds.
Approach and architecture
We built MemoryBench, a universal evaluation platform for memory providers.
Core idea
Define the smallest universal contract that works across providers:
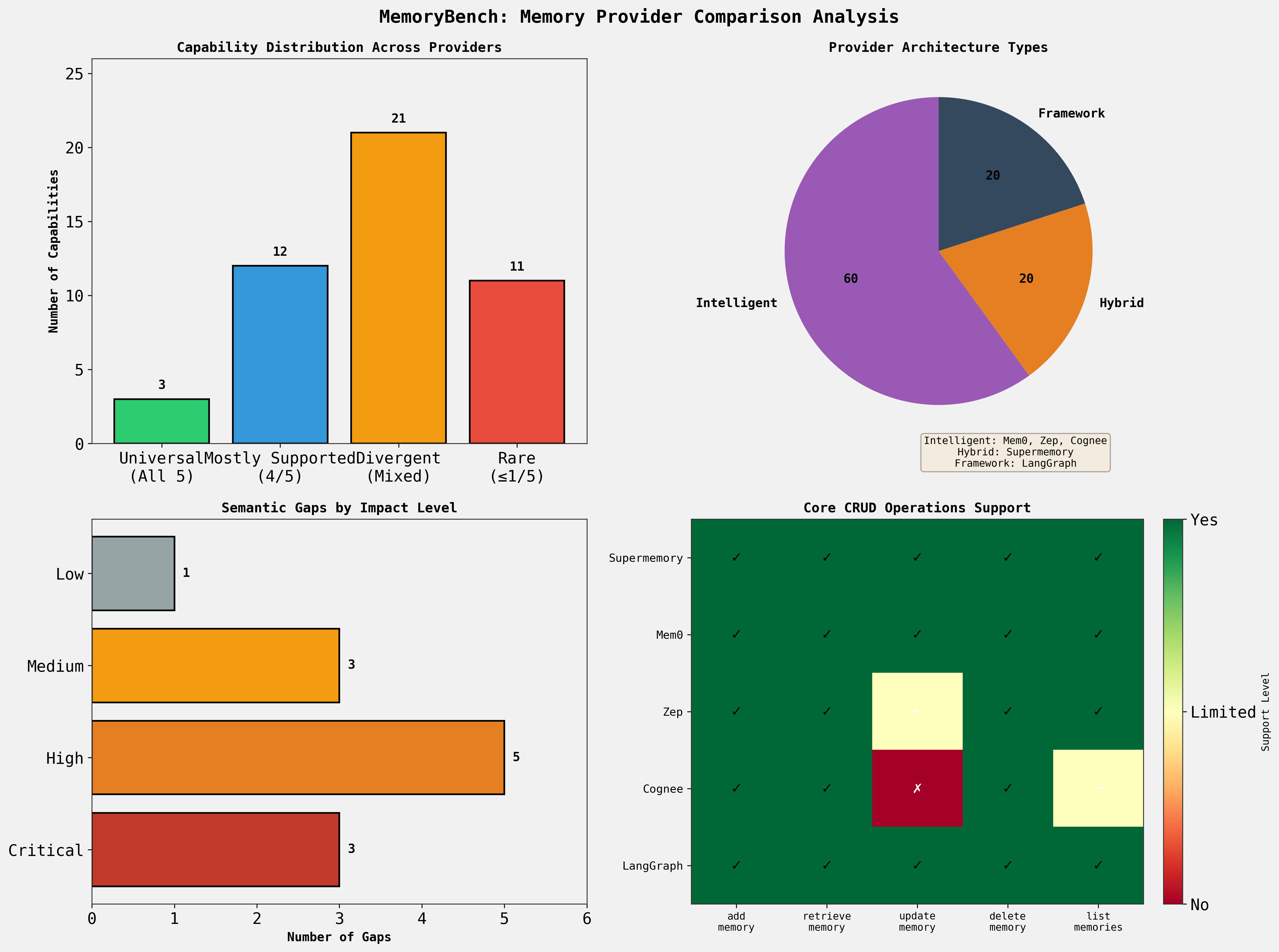
add_memoryretrieve_memorydelete_memory(With optionalupdate/listwhere supported.)
Pipeline
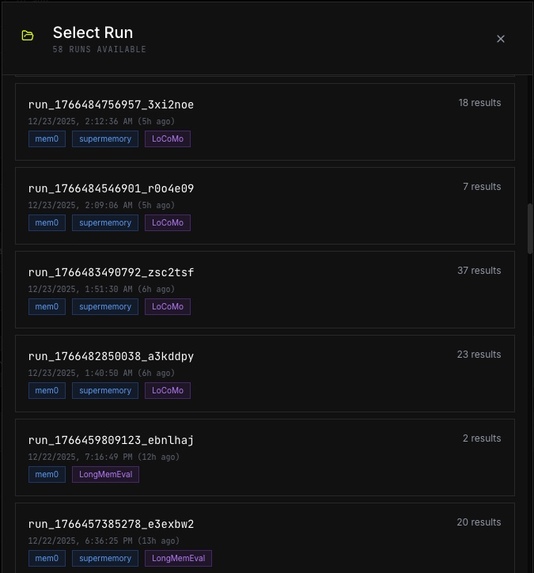
Runner (CLI) executes a benchmark on one or more providers.
Each run emits a reproducible artifact bundle:
run_manifest(what ran, configs, versions, timing)results.jsonl(per-case outputs + retrieved items)metrics_summary(aggregates like pass rate + retrieval metrics)
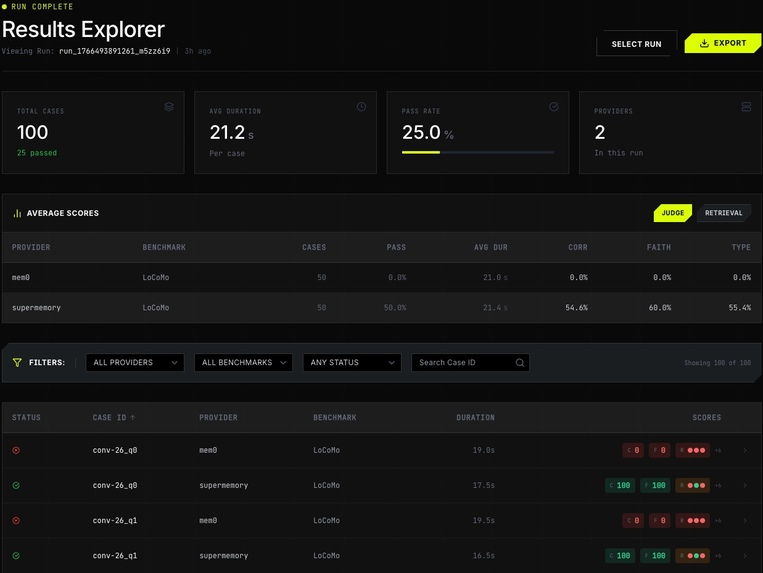
- Explorer UI loads those artifacts and renders:
- run summary (total cases, pass rate, avg duration, providers)
- provider-by-benchmark comparison table
- filters (provider, benchmark, status) + case search
- per-case drilldown with score breakdown + raw result payload
- export for sharing
Benchmark scope for demo
LongMemEval and LoCoMo can be large, so for the hackathon demo we ran small samples (a few LongMemEval cases + a small LoCoMo subset) to keep iteration fast while still demonstrating real benchmark behavior and provider differences.
Tech stack
- TypeScript + Bun for the CLI runner
- React for the Results Explorer UI
- File-based run artifacts (manifest + JSONL results + metric summaries) to support reproducibility and easy sharing
Impact and next steps
Impact
- Makes provider comparisons judge-friendly and developer-debuggable: not just “a score,” but clear retrieval metrics and raw artifacts behind each case.
- Speeds up benchmarking loops: run → inspect → filter failures → drill down → iterate.
- Creates a foundation for a “plug-and-play” benchmarking ecosystem where providers and benchmarks can be added with consistent outputs.
Next steps
- Expand LongMemEval / LoCoMo coverage beyond demo sampling.
- Finish CRUD semantics and convergence handling end-to-end (updates, deletes, visibility delay).
- Add more providers through a config-driven onboarding manifest.
- Add additional benchmark families (e.g., forgetting/leakage tests, needle-in-haystack robustness) as plug-ins.
Built With
- bun
- jsonl
- react
- typescript


Log in or sign up for Devpost to join the conversation.