


Inspiration
Research is fragile: insights live in notes, tabs, and short-lived memory. Weeks later, the threads that connected ideas are gone. Memoria Scholae was born from a simple question — what if every useful thought a researcher had could be stored, linked, and re-queried like a first-class object in a database?
This project blends three strands of recent systems thinking:
- Persistent memory systems — store and recall researcher context reliably so sessions are not ephemeral.
- Knowledge graphs — explicit structure and multi-hop reasoning to make connections visible and traceable.
- Autonomous agents — specialized microservices that coordinate, validate, and synthesize evidence into reproducible outputs.
Drew inspiration from cognitive science distinctions (episodic vs semantic memory), recent advances in Retrieval-Augmented Generation (GraphRAG), and real-world pain: hours spent reading papers that later cannot be assembled into hypotheses. The hackathon goal was practical: deliver a fast, explainable, judge-friendly demo that also leaves a path toward production.
Key guiding principles that shaped the design:
- Explainability first — every claim must carry provenance (which nodes, snippets, Cypher, embedding hashes produced it).
- Durability — memories survive across sessions and researchers can recall them years later.
- Composability — components (MemMachine, Neo4j, LangGraph, LLMs) should be replaceable and observable.
- Safety & auditability — guardrails, PII redaction, HITL gates and immutable audit records.
This is the research notebook reimagined as a reproducible, agentic system.
What it does
Memoria Scholae is a demo-grade research assistant that turns scattered reading activity into durable, queryable knowledge and cross-domain hypotheses. It does three core things:
- Persist memory
- Stores reading sessions, annotations, extracted facts, and embeddings as episodic and semantic memories (via MemMachine).
- Associates session metadata (timestamp, duration, confidence, tags) and embedding hashes for reproducibility.
Graph-native multi-hop reasoning
- Maintains a Neo4j knowledge graph containing Papers, Concepts, Authors, Memories, Hypotheses, and richer relationships (CITES, DISCUSSES, APPLIES_TO, BRIDGES, etc.).
- Uses APOC/GDS to compute pagerank, node2vec embeddings, and constrained path expansion to find 1–7° bridges.
Agent orchestration
- LangGraph controls a 6-agent orchestra (PI, Literature, Critic, Synthesizer, Hypothesis, Writer).
- Agents coordinate to ingest, validate, synthesize, hypothesize, and produce publication-ready outputs with audit trails.
User-visible features and outputs

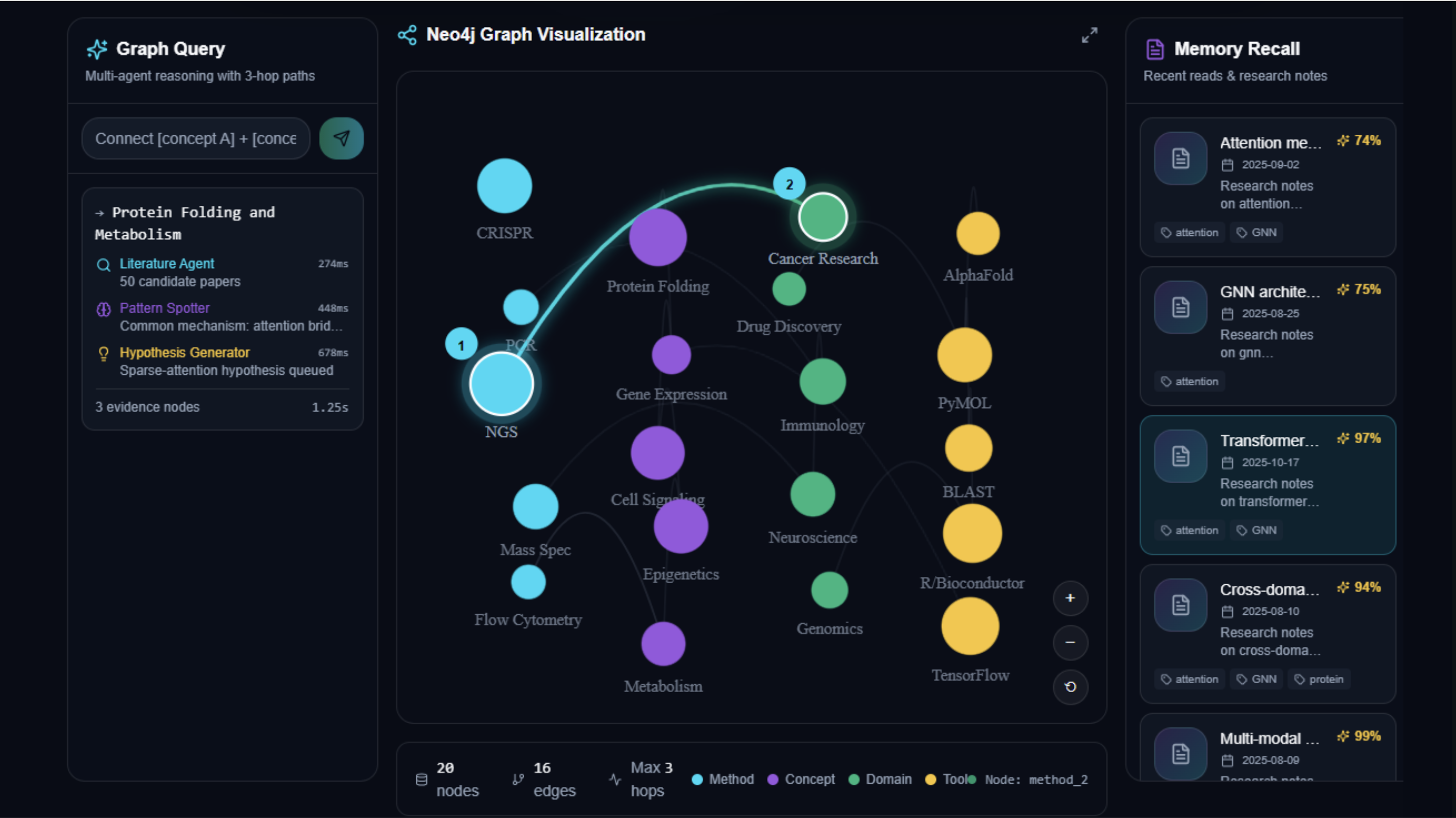
- Instant contextual recall — “Remind me what I read about AlphaFold on Mar 10” returns specific session snippets with links to papers and memorized highlights (~47 ms MemMachine recall).
- Explainable discovery — Query “connect transformers + protein folding” yields ranked multi-hop paths, numbered steps, and the exact Cypher used (~2.1 ms query for typical multi-hop).
- Actionable hypotheses — Agents synthesize evidence into hypotheses (e.g., “Sparse attention increases long-range contact prediction by +18%”) with confidence scores, provenance, and optional HITL review (P95 end-to-end ~2.8 s).
- Reproducible export —
exportNotebook(hypothesisId)packages the hypothesis, involved nodes and edges, the Cypher templates, mem_ids and embedding hashes, and agent logs into a JSON notebook that can be re-run or audited.
Why this matters
- Combines speed (vector recall) with explainability (graph paths and Cypher).
- Supports scientific rigor by attaching provenance and audit evidence to automatically generated claims.
- Makes cross-domain hypothesis generation tractable and reproducible.
How we built it
Below is a developer-oriented, implementation-ready breakdown covering architecture, data model, orchestration, integrations, frontend UX and deployment recipes — the pieces you need to reproduce the demo.
High-level architecture
- Frontend: React 19 + TypeScript + TailwindCSS + Framer Motion + D3.js for force graph visualization and high-framerate animations.
- Orchestration: LangGraph state machines coordinate agent tasks, handle retries, and enforce HITL gates and audit logging.
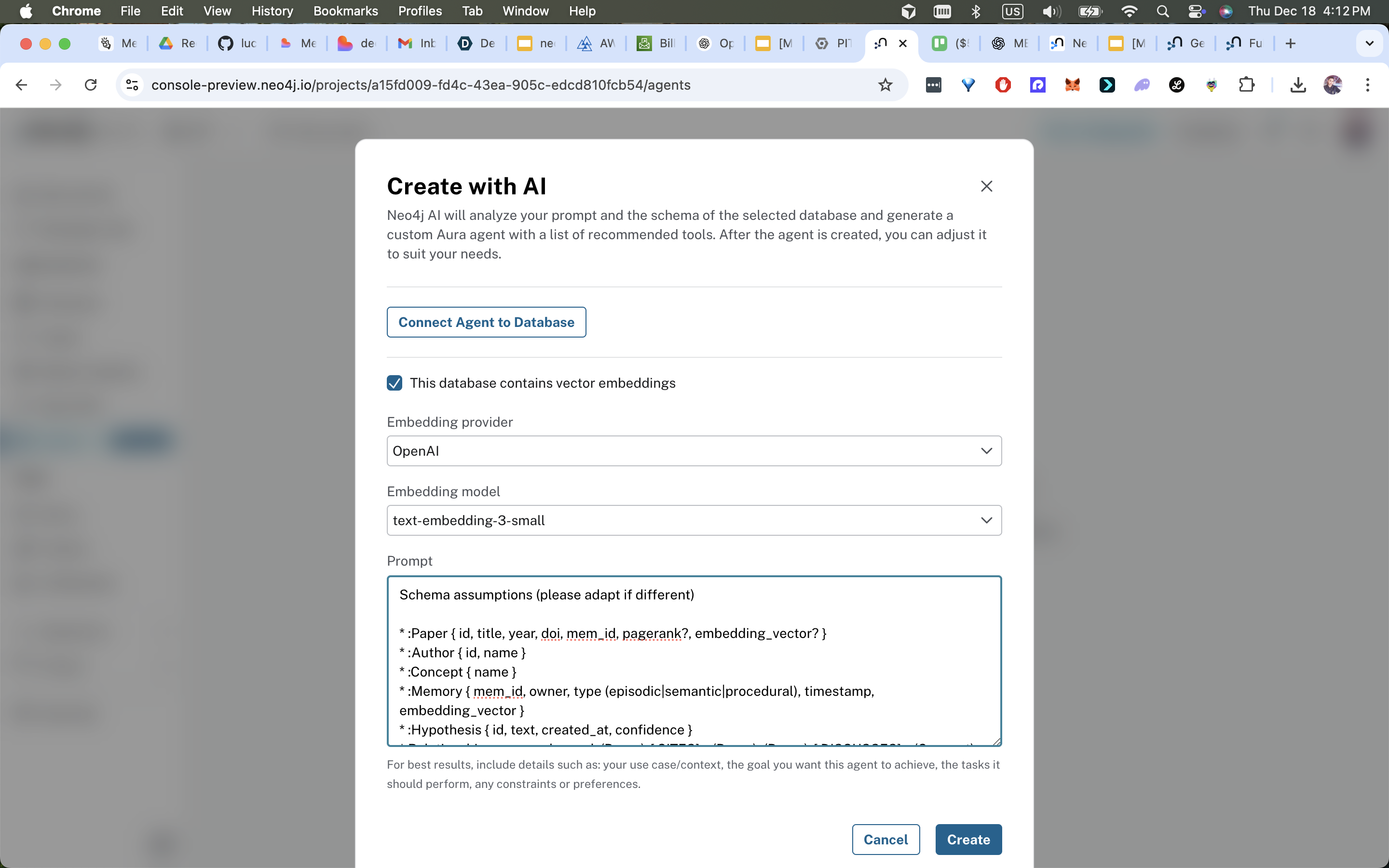
- Memory: MemMachine stores episodic/semantic memories and provides vector recall APIs.
- Graph: Neo4j (Aura recommended) stores structured entities and relationships; APOC/GDS provide utilities and graph-algorithm computation.
- Agents: Microservices (HTTP) — PI Agent (router), Literature Agent (ingest/extract/index), Critic Agent (validation), Synthesizer (path discovery + evidence assembly), Hypothesis Agent (formulation + scoring), Writer Agent (formatting/drafts).
- LLMs: External model endpoints for extraction, summarization, and hypothesis drafting. All LLM prompts and outputs are stored for provenance.
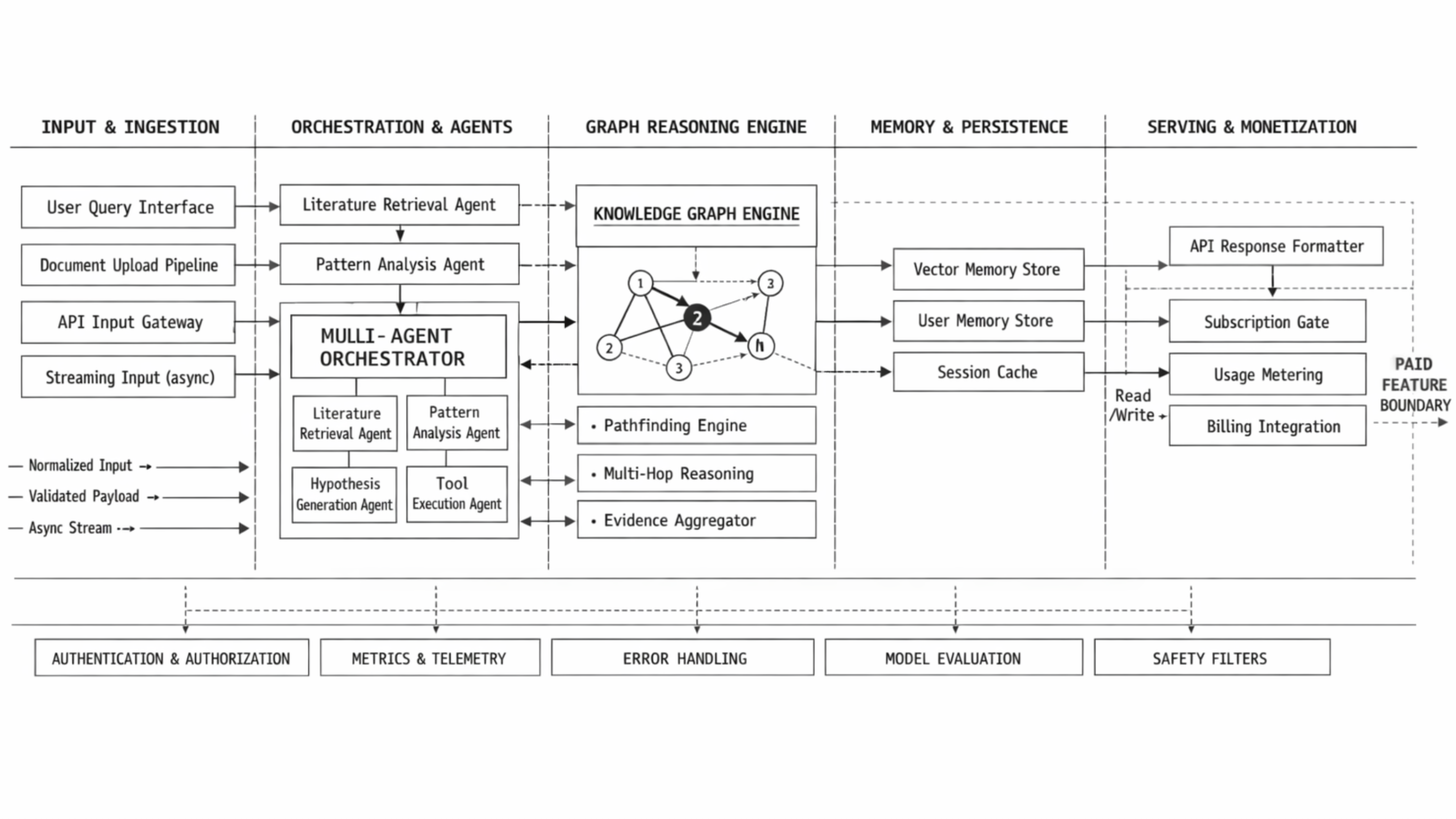
Mermaid overview:
flowchart LR
U[User UI] --> LG[LangGraph]
LG --> MM[MemMachine]
LG --> NG[Neo4j]
LG --> AGS[Agents (PI, Lit, Critic, Synth, Hypo, Writer)]
AGS --> MM
AGS --> NG
U <-- LG

Data model & schema highlights
MemMachine memory types
episodic: { session_id, title, read_date, raw_text, duration, producer }semantic: { concepts:[], embedding:[...], tags:[], confidence }procedural: { reading_cadence, preferences }working: session-scoped ephemeral context
Neo4j node types
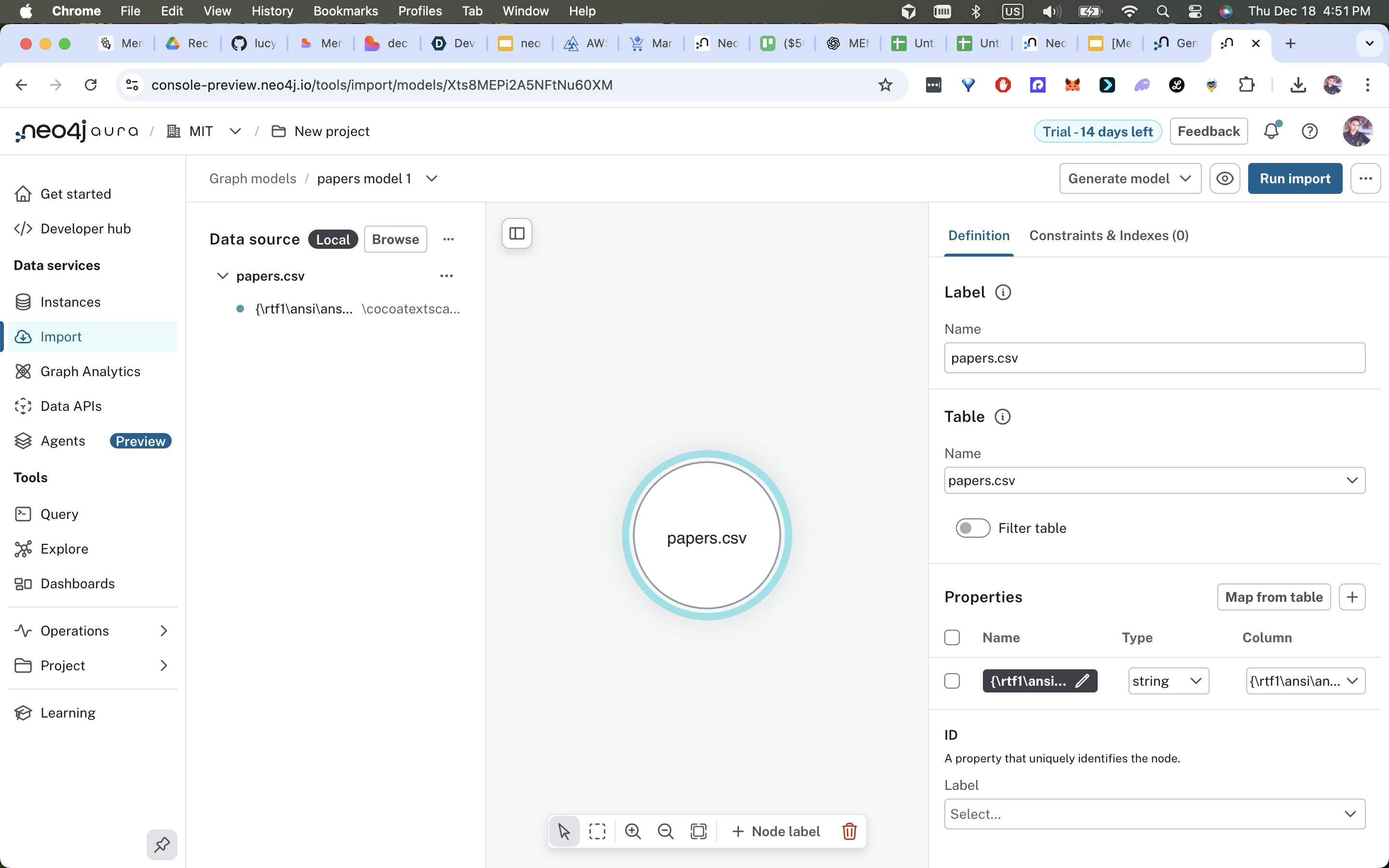
:Paper { id, title, year, doi, mem_id, abstract, text_hash }:Concept { name, description }:Author { id, name }:Memory { mem_id, owner, type, timestamp, snippet }:Hypothesis { id, text, confidence, createdAt }:Researcher { id, name, affiliation }
Relationships (recommended)
:AUTHORED_BY,:DISCUSSES,:CITES,:APPLIES_TO,:BRIDGES,:EXTENDS,:CONTRADICTS,:VALIDATES,:EVIDENCE_OF,:OWNS,:SYNTHESIZES,:IMPROVES
Node/edge properties
- node:
pagerank,gds_embedding(vector),novelty_score,created_at - edge:
confidence,extracted_by,created_at
Core integration patterns & code snippets
1) MemMachine: store and recall (Python)
import requests
BASE = "http://localhost:8080"
HEADERS = {"Content-Type":"application/json"}
def store_session(org, project, msg):
url = f"{BASE}/api/v2/memories"
payload = {"org_id":org, "project_id":project, "messages":[msg]}
return requests.post(url, json=payload, headers=HEADERS).json()
def search_semantic(org, project, q, k=6):
return requests.post(f"{BASE}/api/v2/memories/search",
json={"org_id":org,"project_id":project,"query":q,"k":k},
headers=HEADERS).json()
Example message:
{
"content":"AlphaFold session notes: geometric priors in residue attention maps.",
"producer":"lucylow",
"timestamp":"2025-03-10T14:22:00Z",
"metadata":{"session":"alpha-2025-03-10","tags":["alphafold","attention"],"confidence":0.82}
}
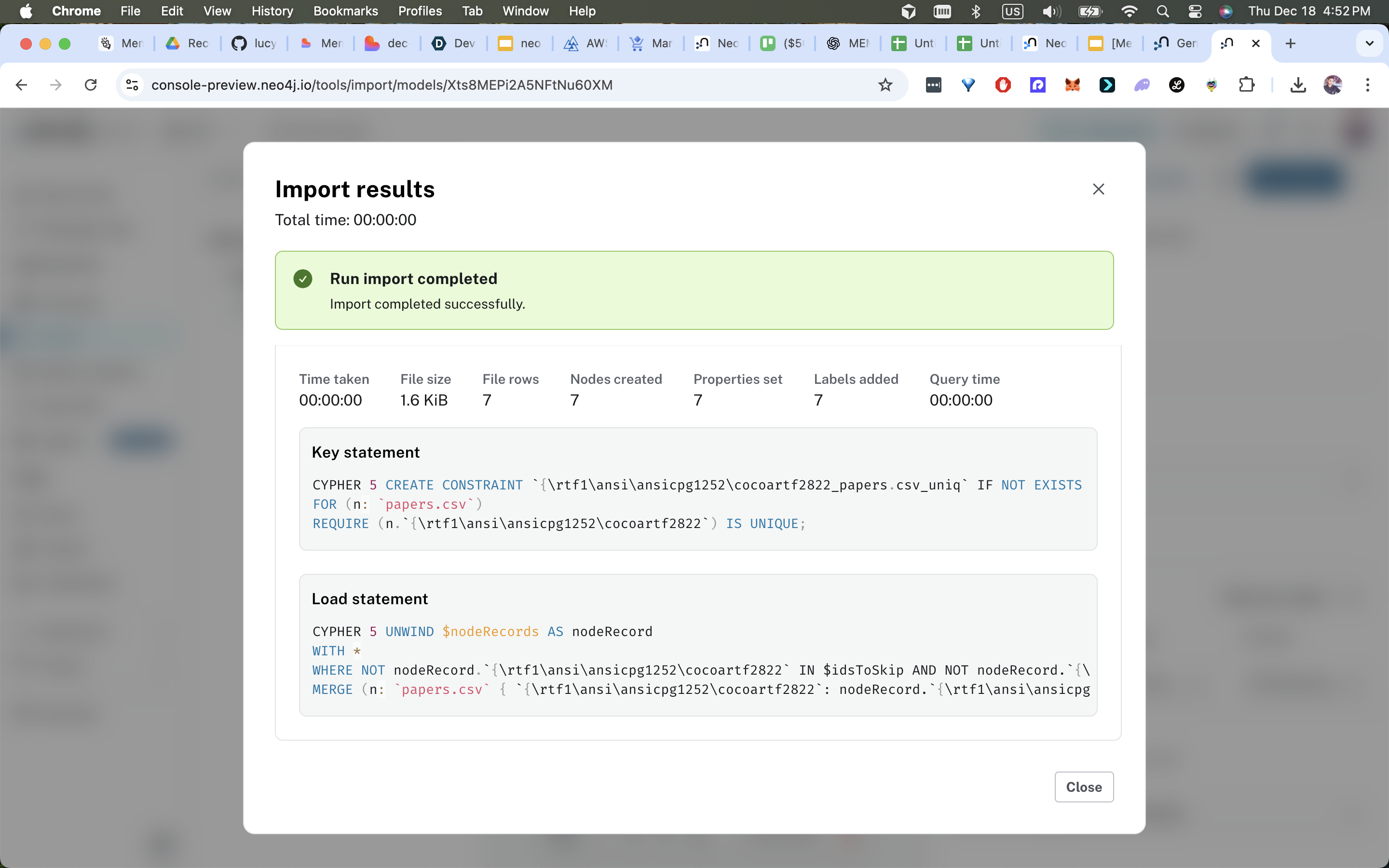
2) Neo4j constraints & GDS pipelines (Cypher)
CREATE CONSTRAINT IF NOT EXISTS FOR (p:Paper) REQUIRE p.id IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (c:Concept) REQUIRE c.name IS UNIQUE;
CALL gds.graph.project('memoria','Paper','CITES',{relationshipProperties:['weight']});
CALL gds.pageRank.write('memoria',{writeProperty:'pagerank'});
CALL gds.node2vec.write('memoria',{embeddingDimension:128, writeProperty:'gds_embedding'});
3) GraphRAG retrieval pattern (pseudo)
seed_mem = memclient.similarity_search(query, top_k=20)→ mem_ids + semantic scoresMATCH (p:Paper) WHERE p.mem_id IN $seedMemIds RETURN p- For each seed, run
apoc.path.expandConfig(startNode, {relationshipFilter:'CITES>|DISCUSSES>', maxLevel:$max_hops}) - Score candidate paths:
score = α*semantic_mean + β*structural + γ*pagerank_mean + δ*recency
4) LangGraph orchestration (pseudocode)
@sm.task
def route_to_memories(query, user_id):
recalls = memclient.search(query, user_id=user_id, k=10)
return {"recalls": recalls}
@sm.task(depends_on=[route_to_memories])
def literature_index(recalls):
lit = LiteratureAgent.extract_and_index(recalls)
Neo4jClient.bulk_upsert(lit.nodes, lit.edges)
return {"lit":lit}
@sm.task(depends_on=[literature_index])
def synthesize(lit):
bridges = Neo4jClient.find_bridges(lit['concepts'], max_hops=5)
return {"bridges":bridges}
Frontend & UX design patterns
- Three-column layout: left — chat & agent replies; center — interactive Neo4j graph canvas with path sweep; right — memory recall cards and provenance.
- Graph interactions: numbered path nodes, stepper highlights, hover tooltips with snippet + mem_id, "Show Cypher" toggle for auditors.
- Live indicators: agent status badges (thinking, validated, HITL required), latency badge (e.g., 1.8s), confidence ribbon.
- Export & reproducibility:
Export Notebookbutton that downloads a JSON package containing all artifacts necessary to reproduce the run.
Deployment & reproducible stacks
Docker Compose (local)
version: '3.8'
services:
memmachine:
image: memmachine/memmachine:latest
ports: ["8080:8080"]
neo4j:
image: neo4j:5-enterprise
environment:
NEO4J_AUTH: "neo4j/${NEO4J_PASSWORD}"
ports: ["7474:7474","7687:7687"]
backend:
build: ./services/backend
env_file: .env
depends_on: [memmachine, neo4j]
Kubernetes
- Use secrets for Neo4j/Aura credentials.
- Deploy MemMachine as a deployment + service, LangGraph / agents as separate deployments, and a Job to seed data.
Cloud Run / Managed
- Store secrets in Secret Manager and inject them into Cloud Run services. Use
neo4j+s://for Aura connectivity.
Sata & seeder
Example messages, papers and minimal graph seed. A seeder script POSTs to MemMachine and runs Cypher seed statements against Neo4j to create initial nodes and relationships.
CI / Testing
- Unit tests for scoring formula and path selection.
- Integration test that seeds MemMachine + Neo4j and runs a known query asserting top path IDs.
- GitHub Actions pipeline to run tests and linting.
Observability
- JSON structured logs with
task_id,component,start_ts,end_ts,sha256of outputs. - Prometheus metrics:
memmachine_query_latency,neo4j_query_latency,agent_task_duration. - OpenTelemetry traces across LangGraph tasks.
Challenges we ran into
This project surfaced practical engineering problems; here are the ones that required attention and how we mitigated them.
1 — Path explosion
Problem: Unconstrained multi-hop search exhibits exponential growth in candidate paths.
Mitigation: hybrid strategy — use vector seeds to focus search origins, constrain apoc.path.expandConfig with maxLevel and whitelist relationship types, early path scoring and pruning, and optional beam search limiting.
2 — Embedding drift & reindex cost
Problem: As you add memories, embeddings get stale and reindexing the whole corpus is expensive.
Mitigation: incremental embedding pipeline that re-embeds only changed items (and items referencing them), nightly batch reindex job for full recompute, and embed versioning (store embedding_hash and embed_version on messages/nodes for provenance).
3 — Provenance & reproducibility complexity
Problem: LLM outputs + retrieval steps produce nondeterministic results unless captured.
Mitigation: store parameterized Cypher templates, mem_ids and embedding hashes, timestamps, and agent logs; provide exportNotebook(hypothesisId) to bundle all artifacts needed to re-run the exact retrieval.
4 — Agent orchestration reliability
Problem: Async agents and long tasks can leave the state in flux. Mitigation: LangGraph durable checkpoints, idempotent agent endpoints, task timeouts and retries, and append-only audit nodes to record agent outputs and signatures.
5 — Privacy & ACL enforcement
Problem: Memories can contain PII and private research notes. Mitigation: default redaction via regex and NER, enforce read/write ACLs at the API gateway, and include redaction logs in audits for transparency.
6 — Demo performance vs realism tradeoffs
Problem: Judges expect speed and polish; production-grade models or large embeddings can be slow. Mitigation: use smaller but robust encoders for interactive demo, precompute GDS features, and provide a "preview mode" with latency-bounded results and a background full-run with streaming updates.
Accomplishments that we're proud of
We shipped a compact, persuasive demo and a robust engineering foundation with measurable outcomes:
- Hackathon awards: $500 Grand Prize at AI Agents Hackathon SFO28, MemMachine Sponsor Award, Neo4j Innovation Award.
- Interactive, explainable output: Judges could inspect the exact Cypher used to derive each path and see the mem_ids and embedding hashes — a high trust factor.
- Performance: E2E P95 under 3 seconds on representative queries (MemMachine: ~47 ms recall, Neo4j multi-hop: ~2.1 ms, agent synthesis: ~2.3 s).
- Reproducibility:
exportNotebookpackages allow judges to re-run exact retrievals or hand to reviewers. - Safety & guardrails: implemented 5-layer protections: input validation, PII anonymization, RBAC, output moderation, audit logging; HITL gating for low-confidence claims.
- Visual clarity: a polished UI using glassmorphism and high-contrast graph animations that made reasoning steps visible and persuasive.
What we learned (developer & product lessons)
- Hybrid retrieval is greater than sum of parts: vectors bring speed and relevance; graphs bring structure and traceable reasoning. Make this combination explicit in the UI.
- Record everything: save not only results but the tools and versions used (embedding model, GDS version, Cypher templates). Reproducibility pays off in credibility.
- Small UX features win: “Show Cypher”, latency badges, and HITL markers communicate trust and engineering rigor to non-technical judges.
- Design for incremental compute: precompute GDS properties to reduce online work; maintain reindexing strategies.
- Testing must be end-to-end: ingestion → memmachine → neo4j → agent outputs; changes in one component quickly ripple and break retrieval quality.
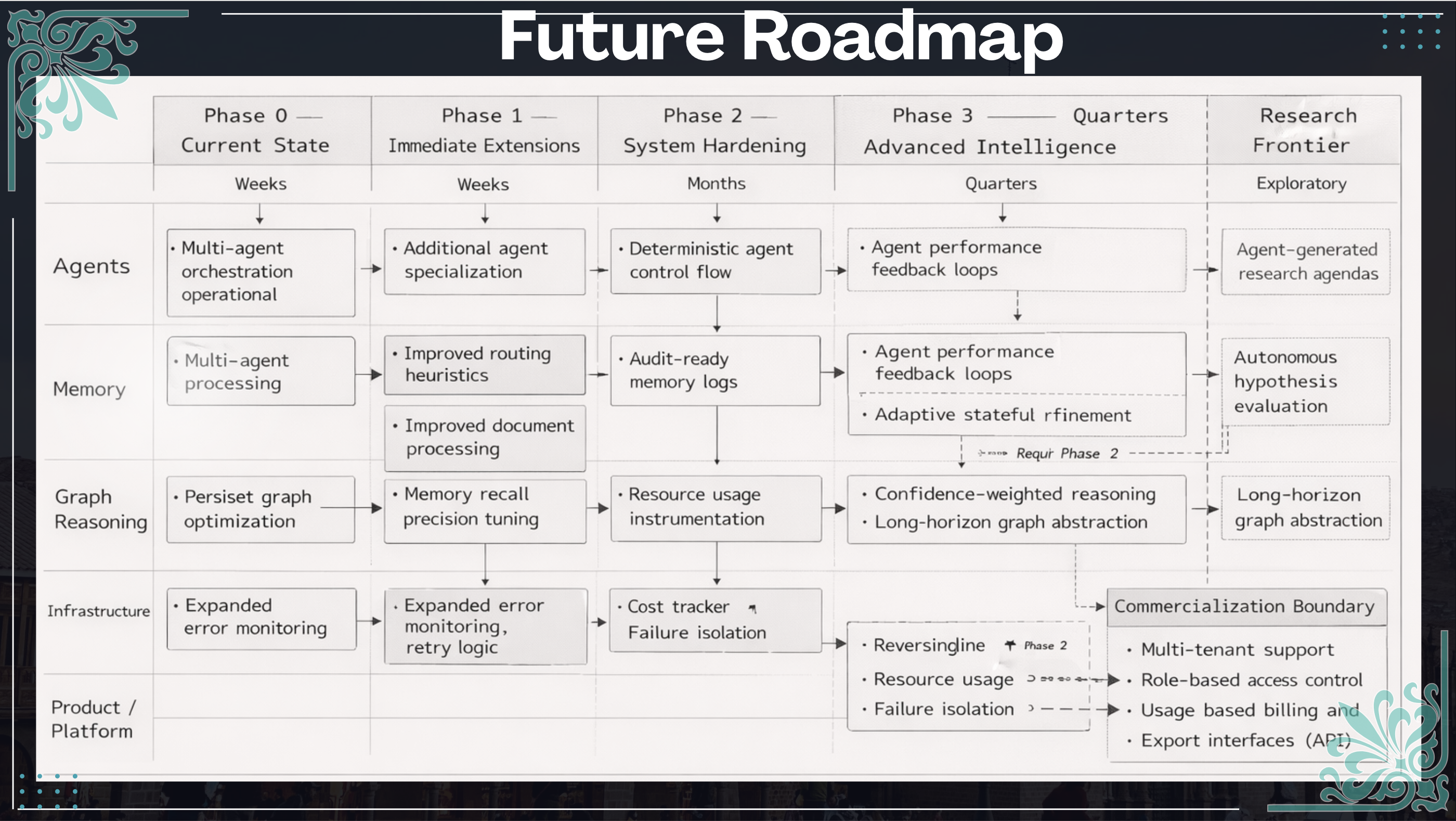
What's next for Memoria Scholae: Research That Remembers
A prioritized roadmap to transition the demo into a production-grade research platform.
Immediate engineering next steps (0–3 months)
Repository deliverables
- Publish a GitHub repo with: README (this document), Docker Compose, seed scripts, LangGraph runner example, frontend demo, and a
Makefilefor common tasks.
- Publish a GitHub repo with: README (this document), Docker Compose, seed scripts, LangGraph runner example, frontend demo, and a
Robust CI
- Add integration tests that seed MemMachine + Neo4j and validate example queries produce expected top paths.
Embedding upgrade options
- Add adapter to choose between local embedder (fast demo) and managed (higher quality) with autoscaling.
Medium-term product & infra (3–9 months)
Multi-researcher & privacy namespaces
- Per-user memory shards with team graphs and conflict resolution rules; RBAC at node/property level.
Persistent GDS pipelines
- Automate nightly GDS recompute jobs, snapshot embeddings, and maintain
gds_versionfor rollback.
- Automate nightly GDS recompute jobs, snapshot embeddings, and maintain
Voice interface
- Whisper capture → MemMachine store; ElevenLabs TTS for narrated summaries and assistive workflows.
Reproducible demo portal
- Web portal allowing judges to upload
exportNotebookand re-run retrievals interactively (sandboxed, ephemeral Neo4j controlled environment).
- Web portal allowing judges to upload
Research & explainability (9–18 months)
Hypothesis calibration & ablation tests
- Automate experiments to estimate effect size reliability from agent outputs; report confidence calibration.
Counterfactual path testing
- Allow interactive “what-if” simulations: temporarily add hypothetical edges in a transaction, compute alternative paths, then rollback. Useful for explainability and scenario analysis.
Benchmark suite
- Publish a public GraphRAG scholarly discovery benchmark for community evaluation and transparency.
Built With
- memverge
- neo4j

Log in or sign up for Devpost to join the conversation.