-
-
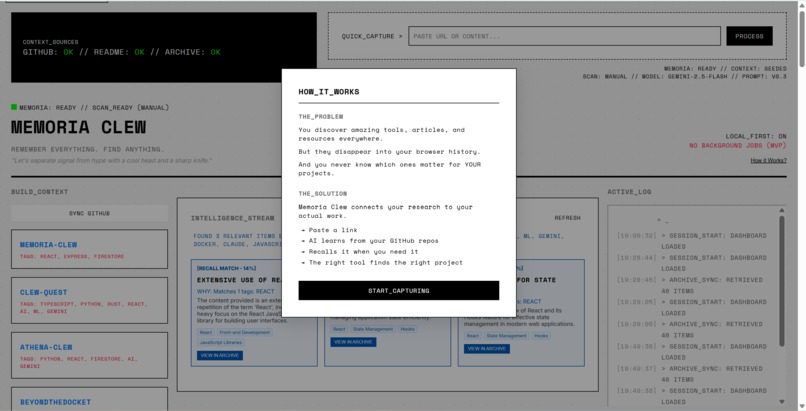
How it works
-
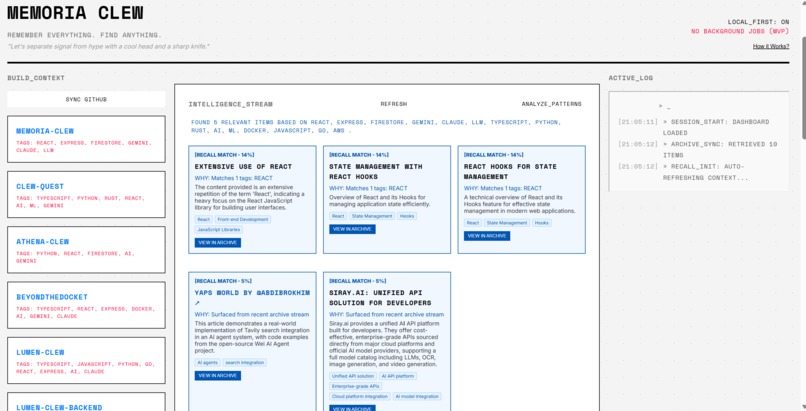
Memoria Clew Homepage
-

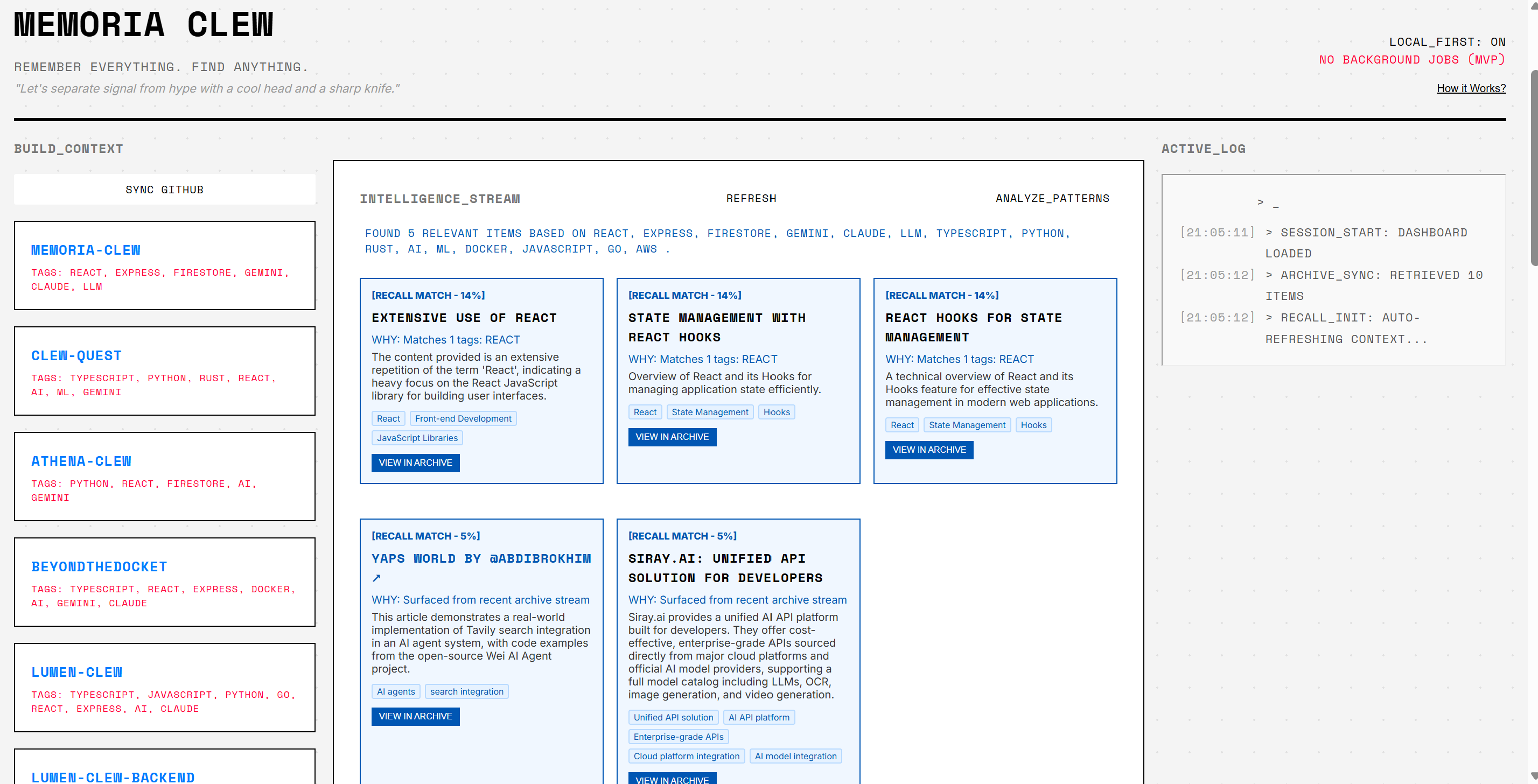
Memoria Clew Deep Pattern Analysiss
-
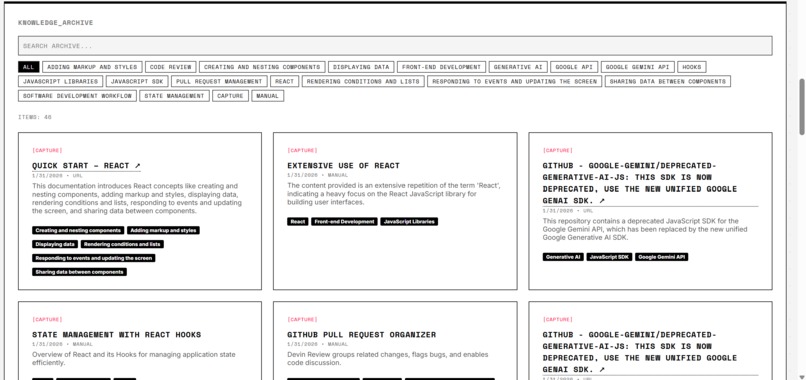
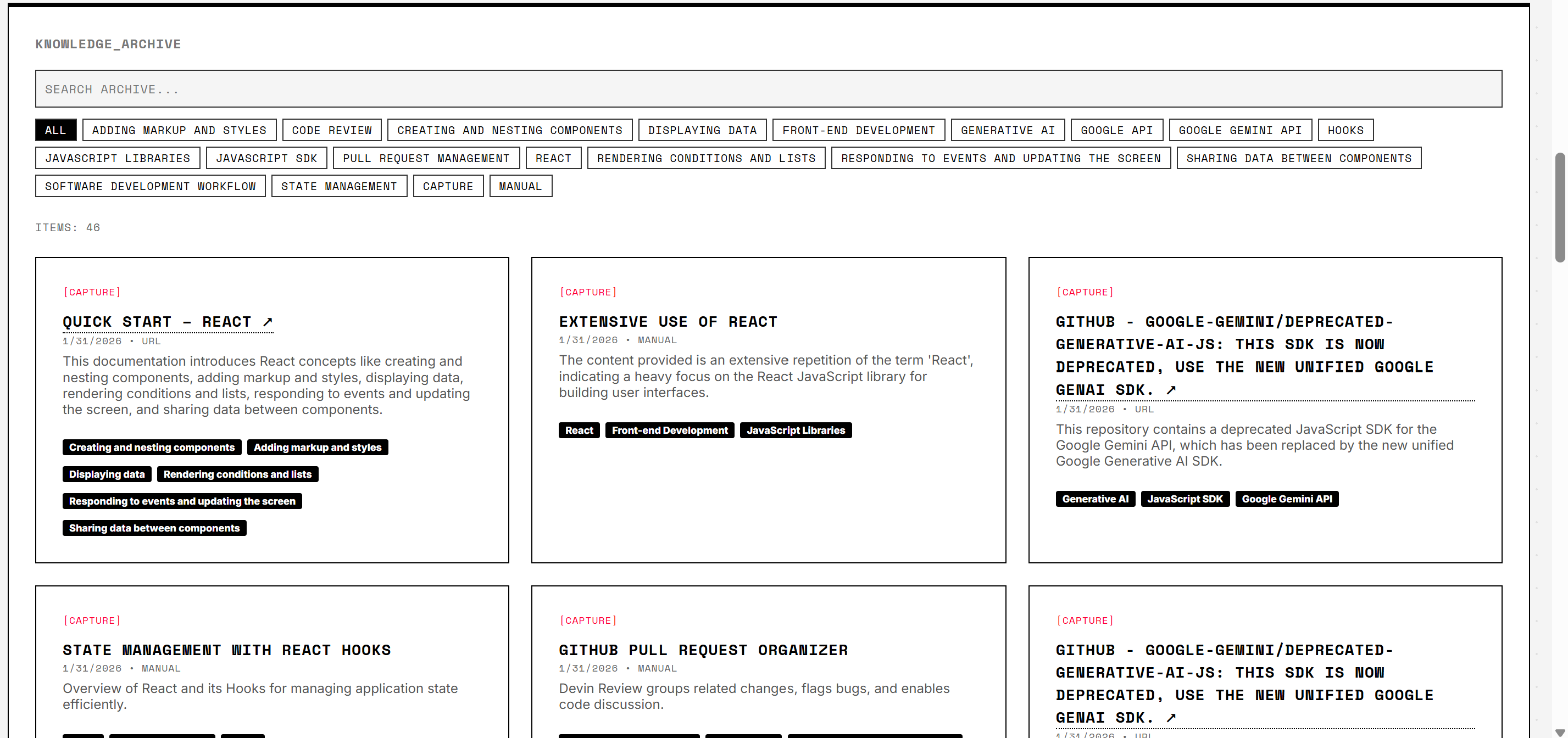
Memoria Clew Knowledge Archive

MEMORIA CLEW
Remember everything. Find anything.
“Let’s separate signal from hype with a cool head and a sharp knife.”
Inspiration
I read constantly to learn and build through repositories, documentation, newsletters, and technical writing, but recalling that knowledge when it matters is harder than collecting it.
I would read something genuinely useful, forget it weeks later, and then rediscover the same idea only after I had already struggled through a solution. Notes apps helped me store information, but they never helped me remember it at the moment it mattered.
Memoria Clew was inspired by that gap: the space between learning something valuable and being able to recall it when your context changes.
What it does
Memoria Clew is a personal knowledge system that captures everything you read — repos, README files, URLs, newsletters, and headlines — and then proactively recalls relevant knowledge based on your current work context.
Instead of relying on manual search or asking an AI vague questions, Memoria Clew:
- Captures knowledge once
- Stores it with structured summaries and tags
- Monitors changes in your active context
- Surfaces relevant past items automatically, with explanations
The goal is not to generate new information, but to resurface the right information you already encountered.
Features
✅ Capture + Archive
- Paste URL or text snippet
- LLM summary + tag extraction (Claude or Gemini, with automatic fallback)
- Archive persisted via Firestore (user-scoped collections)
- Inspectable structured records (title, summary, tags, source, timestamps)
✅ Context Seeding (GitHub)
- GitHub context sync endpoint
- Pulls lightweight signals from public repo metadata and READMEs
- Treated as weak signal (biasing recall, not pretending to "understand your whole codebase")
- GitHub repos automatically indexed in archive for discovery
✅ Recall Engine (Deterministic + Explainable)
- Transparent scoring (tag overlap, query match, tool/tech match, recency boost)
- Confidence thresholding to reduce noise
- Explanations like: "Matches tags: REACT, TYPESCRIPT"
- Fallback behavior to avoid empty UX
- Case-insensitive matching with multi-factor scoring
✅ Pattern Analysis (Agent-Powered Intelligence)
- Analyzes your complete research archive via LLM (Claude/Gemini)
- Detects learning themes (what technologies/patterns you focus on)
- Identifies knowledge gaps (what you haven't explored yet)
- Generates recommendations (what to learn next based on your trajectory)
- Exposed via Dashboard UI ("ANALYZE_PATTERNS" button) + MCP tool
- All reasoning is logged and inspectable (no black-box decisions)
✅ Manual "Proactive" Scan (MVP)
- One manual scan of a single source (HN RSS)
- Produces a small set of context-matched items (top 5)
- No background agents, no always-on crawlers
✅ Trust & Safety Guardrails
- Rate limiting service + tests
- Security middleware + tests
- Explicit "suggestive not authoritative" posture
- Per-IP rate limiting to prevent abuse
✅ Docker for Local Dev + Deployment Readiness
docker-compose.ymlincluded (frontend + MCP server)server/Dockerfileincluded (containerizable backend)
- frontend/Dockerfile.dev included (dev container)
LeanMCP Integration & Agent Capabilities
Memoria Clew includes a real MCP server powered by @leanmcp/core.
Tools Exposed
memoria_recall- Surface relevant research based on current project context- Input: userId, projectTags, projectDescription, query
- Output: Matched items with relevance scores and explanations
- Use case: Agent helping you build asks "what have I researched about this?"
memoria_patterns- Analyze research patterns and get learning recommendations- Input: userId
- Output: Detected themes, gaps, recommendations
- Use case: Agent asks "what should this developer learn next?"
Why This Approach
- Agent capabilities are explicit, not hidden - you can see exactly what tools agents can invoke
- Reasoning is transparent - every recall and every pattern analysis logs its scoring and reasoning
- Integration is clean - tools use the same service layer as the UI
- Audit trail is complete - all tool invocations are logged
- No background autonomy - agents only act on explicit invocation, never silently
How It's Used
- The backend boots REST endpoints (for the UI) and an MCP server (for tool invocation)
- Agents can invoke tools to:
- Recall relevant research: "What have I learned about Docker?"
- Understand patterns: "What should I learn next?"
- Example agent workflow: "I see you're building with React. You've researched async patterns heavily. You're ready for performance optimization. Here's what you captured about it..." This keeps agent behavior auditable and user-controlled—no background autonomy, only structured tool calls with visible reasoning.
How its built
Frontend
- Built with React and TypeScript
- Fully wired to real backend APIs for capture, archive, recall, and GitHub context sync
- An HTML prototype defines the UI contract and visual system for the dashboard
Backend
- Node.js service architecture
- Endpoints for capture, archive, recall, and context ingestion
- Deterministic logging to make system behavior observable
Recall Engine
- Transparent scoring (tag overlap, query match, tool/tech match, recency boost)
- Confidence thresholding to reduce noise
- Explanations like: "Matches tags: REACT, TYPESCRIPT"
- Fallback behavior to avoid empty UX
- Case-insensitive matching with multi-factor scoring
AI Integration
- Uses function-based LeanMCP API calls to interact with LLMs
- Ensures structured inputs and outputs rather than opaque prompt chains
- Multiple models were used during development to compare behavior and reliability
Infrastructure
docker-compose.ymlincluded (frontend + MCP server)server/Dockerfileincluded (containerizable backend)frontend/Dockerfile.devincluded (dev container)
Challenges I ran into
Cold start problem
Solved by seeding context from high-signal sources like GitHub repos and README files instead of guessing user intent.Avoiding over-automation
We intentionally kept recall suggestive rather than authoritative to avoid false confidence.Testing under time pressure
Unit tests exist, but rapid iteration caused some failures late in development. We prioritized functional correctness and demo stability over perfect coverage.Resisting hype
The hardest challenge was not overclaiming. We focused on what actually works rather than what sounds impressive.
Accomplishments that I'm proud of
- Built a real recall engine, not a mocked demo
- Frontend is fully wired to working APIs
- Recall results are explainable and deterministic
- Failure modes are handled gracefully
- The system never leaves the user with “no results found”
- Dockerized and ready for deployment
- Honest scope control within a hackathon timeline
What I've learned
- Capturing information is easy; recalling it at the right time is hard
- Explainability builds trust faster than clever AI behavior
- Happy-path demos are acceptable if you are transparent about scope
- AI-assisted development works best with clear constraints and guardrails
- Memory systems should respect past effort, not replace it
What's next for Memoria Clew
- Stronger recall signals using embeddings alongside heuristic scoring
- Additional context sources like issue trackers and local notes
- Improved search and filtering across the knowledge archive
- Expanded accessibility coverage and end-to-end testing
- User-controlled tuning of recall sensitivity and thresholds
Memoria Clew is intentionally small today — focused on recall, not hype — and designed to grow without losing trust.
Built With
- antigravity
- chatgpt
- claude
- css
- docker
- express.js
- firebase
- firestore
- gemini
- html5
- javascript
- jest
- leanmcp
- node.js
- react
- typescript
- vite

Log in or sign up for Devpost to join the conversation.