-
-
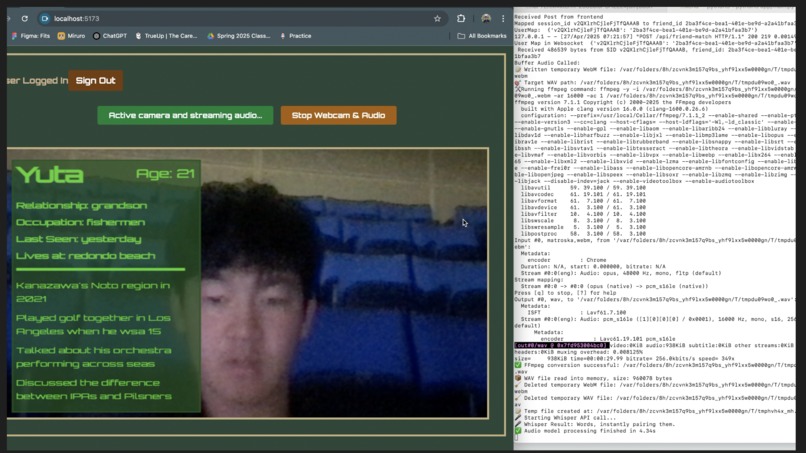
UI
-
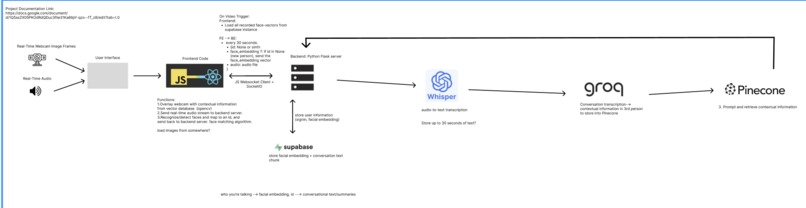
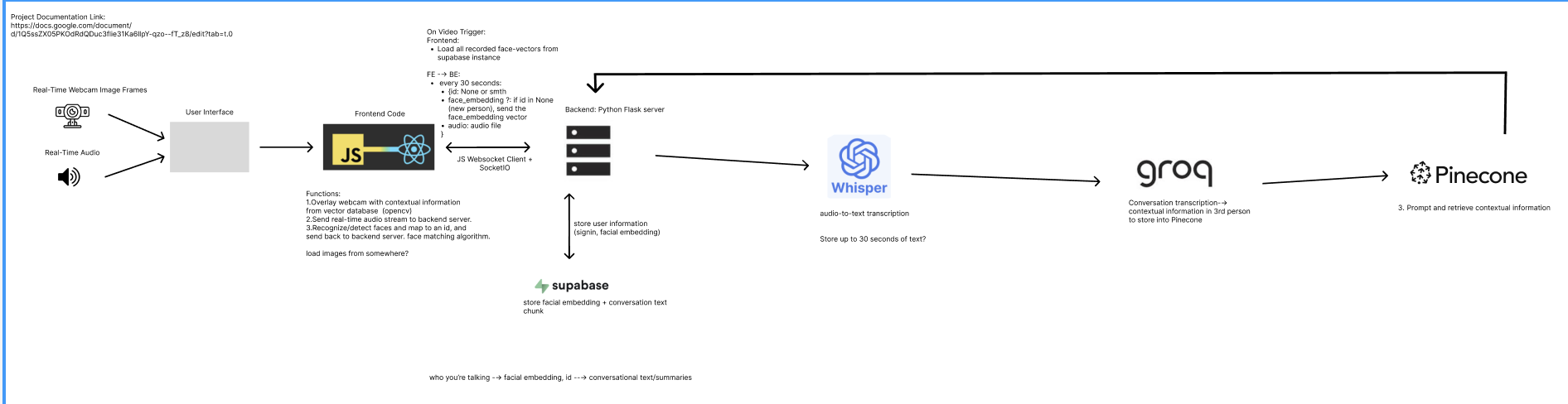
System Design
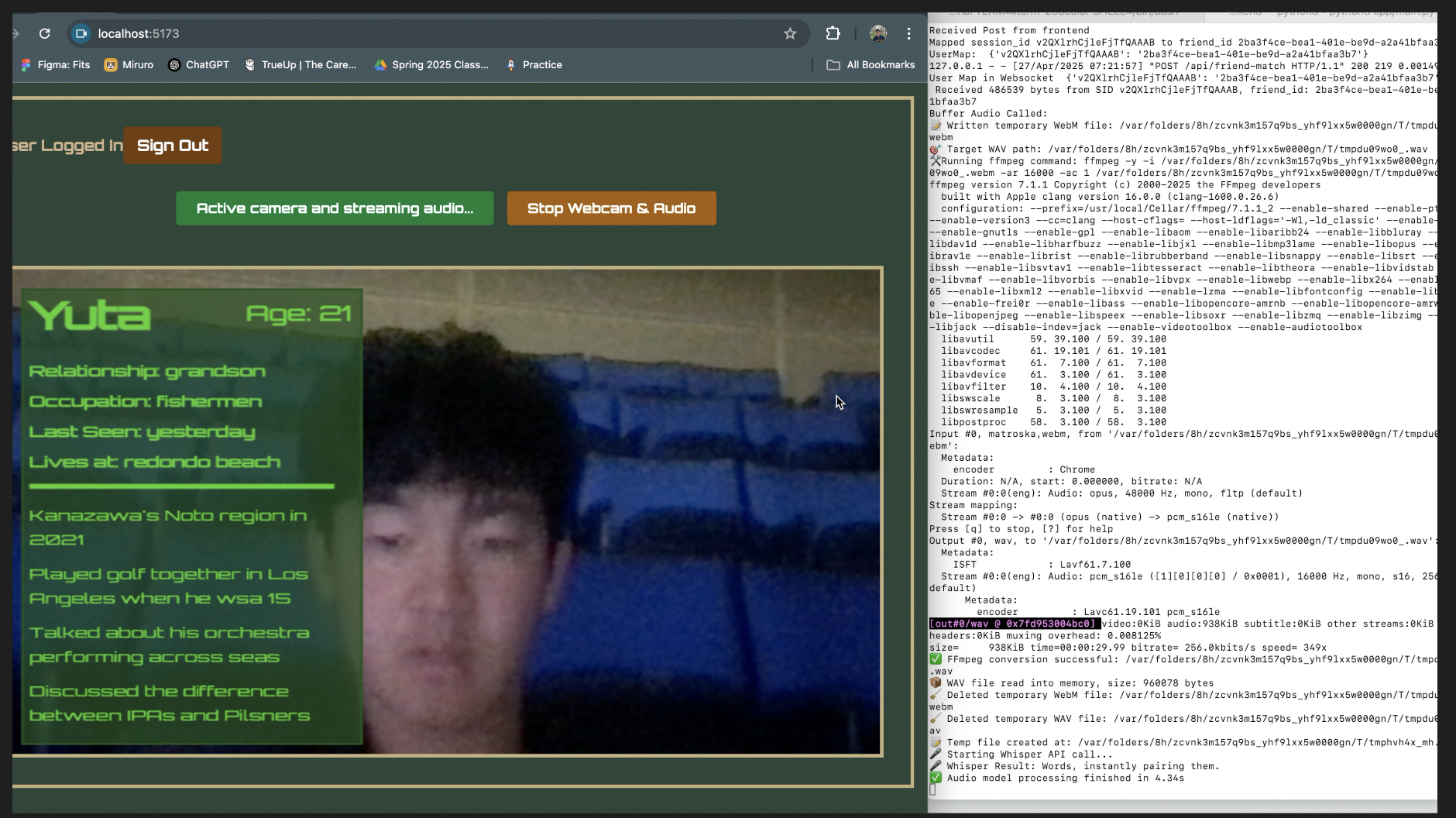
Inspiration
More than 10 million US citizens struggle with Alzheimer's every year. Even more memories and cherished conversations are lost due to this disease. This inspired us to create a tool that uses a vector database to store real-time conversations and contextual memories, allowing users to restore and reconnect with moments they may otherwise forget.
What it does
The software overlays the user’s field of vision with contextual information — including names, relationships, and past conversations — about the person they are currently speaking with. It acts like a "memory assist," helping users recall important details in real-time.
How we built it
We combined several powerful technologies:
- Face identification using face-api.js to detect and recognize faces from a live webcam stream
- Real-time audio transcription using a OpenAI Whisper model
- Conversation summarization and memory extraction through a Groq client (LLaMA model)
- Vector storage and retrieval with Pinecone RAG (Retrieval-Augmented Generation)
- Full-duplex communication between frontend and backend using WebSocket.io
Captured memories are embedded into Pinecone, and when a familiar face is detected again, the system retrieves and displays relevant past conversations.
Challenges we ran into
- Streaming audio data reliably across WebSocket from browser to server
- Chunking and reassembling audio for transcription
- Building an effective RAG pipeline to retrieve the most relevant memories
- Prompt engineering for accurate summarization through the Groq API
- Optimizing real-time face recognition accurately
- Basic React components, useRefs
Accomplishments that we're proud of
We successfully built a working prototype where real memories are captured, stored, and retrieved based on face recognition. Audio, transcription, summarization, and retrieval pipelines all connect in real-time. The overall system feels smooth and intuitive for users!
What we learned
Real-time streaming, processing, and syncing across client-server is much harder than expected. Chaining LLMs (e.g., Whisper → Groq → LLaMA) is very powerful and offers a huge space of creativity. Vector databases like Pinecone are actually work and have great use cases.
Built With
- face-api
- flask
- groq
- javascript
- llama
- pinecone
- python
- react
- supabase
- websocketio
- whisper

Log in or sign up for Devpost to join the conversation.