-
-

Memoo banner
-
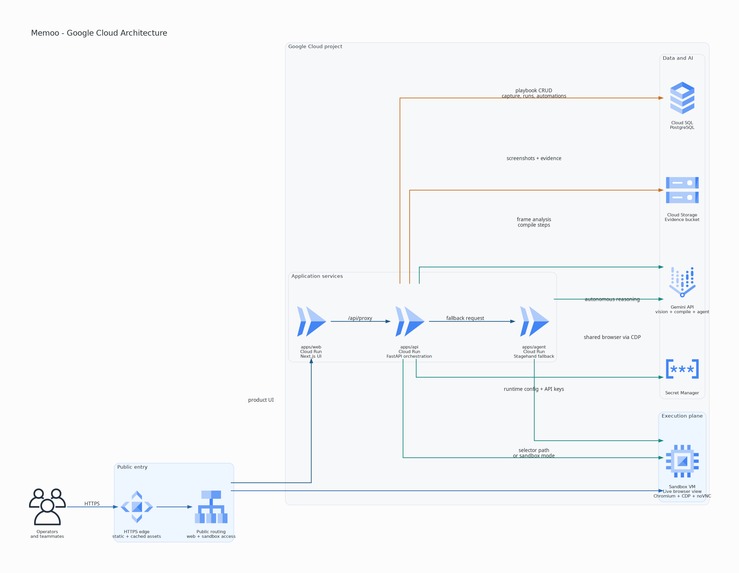
GCP Architecture

Inspiration
Every team has that one person who "knows how to do it." When they're on vacation, the process breaks. We built Memoo because operational knowledge shouldn't live in someone's head. It should be easy to teach, easy to review, and easy to reuse. Instead of asking teams to write scripts or trust bots they can't see into, we wanted something simpler: someone does a task on screen, talks through what they're doing, and Gemini turns that into a playbook anyone on the team can run again.
What it does
Memoo watches your screen while you work and listens to your voice to understand why you're doing each step, not just what you clicked. Gemini looks at every frame to spot the actions that matter, then puts them together into a playbook with readable titles, selectors, variables, and checks. Any teammate can run that playbook later inside a visible browser sandbox that takes a screenshot at every step as proof. If a selector breaks because the UI changed, a Gemini-backed agent switches to visual matching to keep the run going. On top of that, teams can schedule runs, plug in new data through variables, and keep credentials locked in a vault.

How we built it
Memoo has four stages, and Gemini sits at the center of each one.
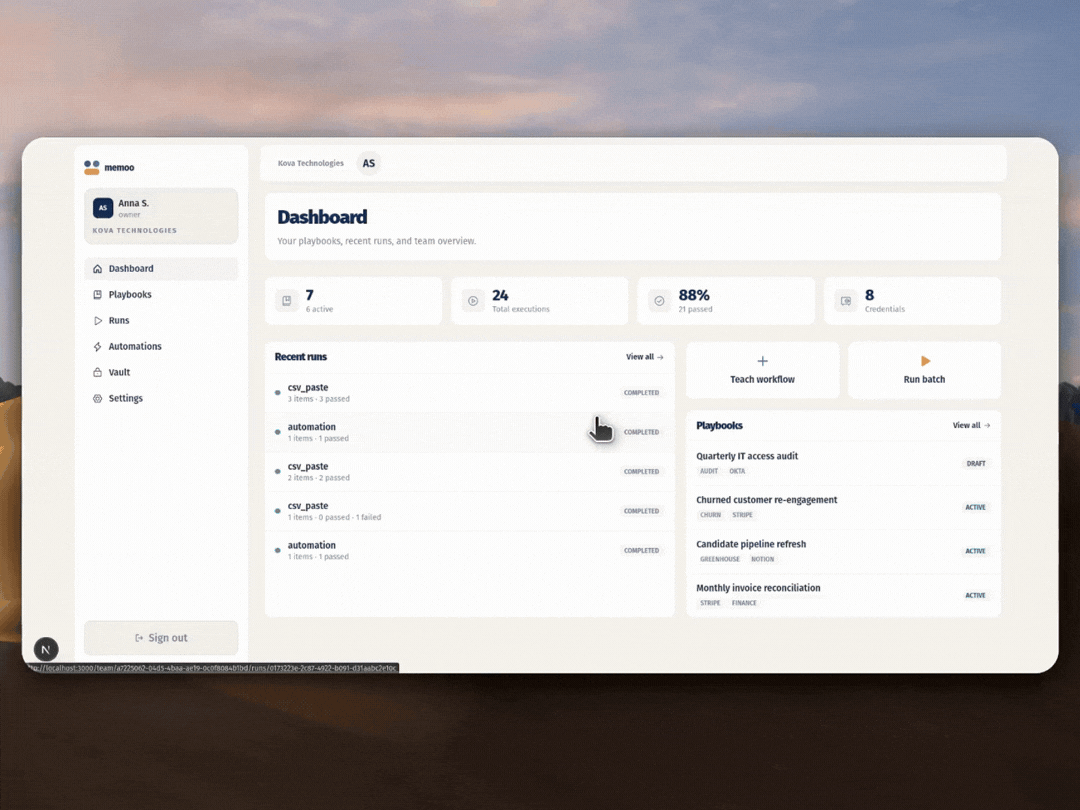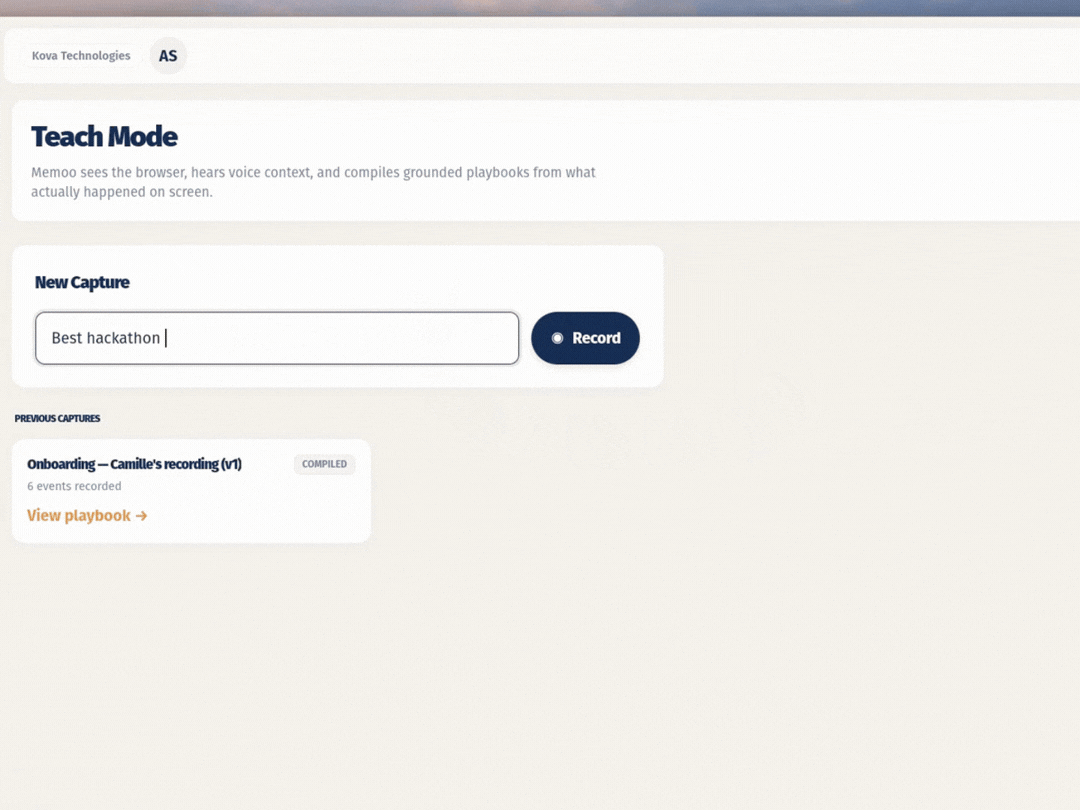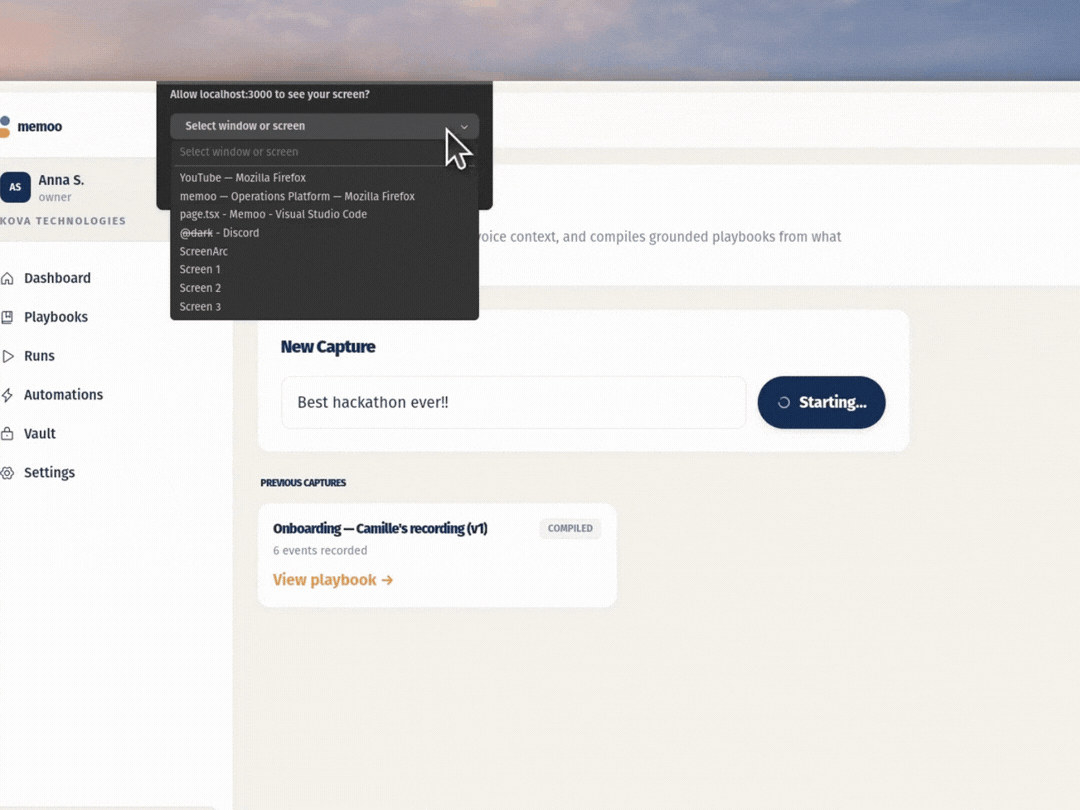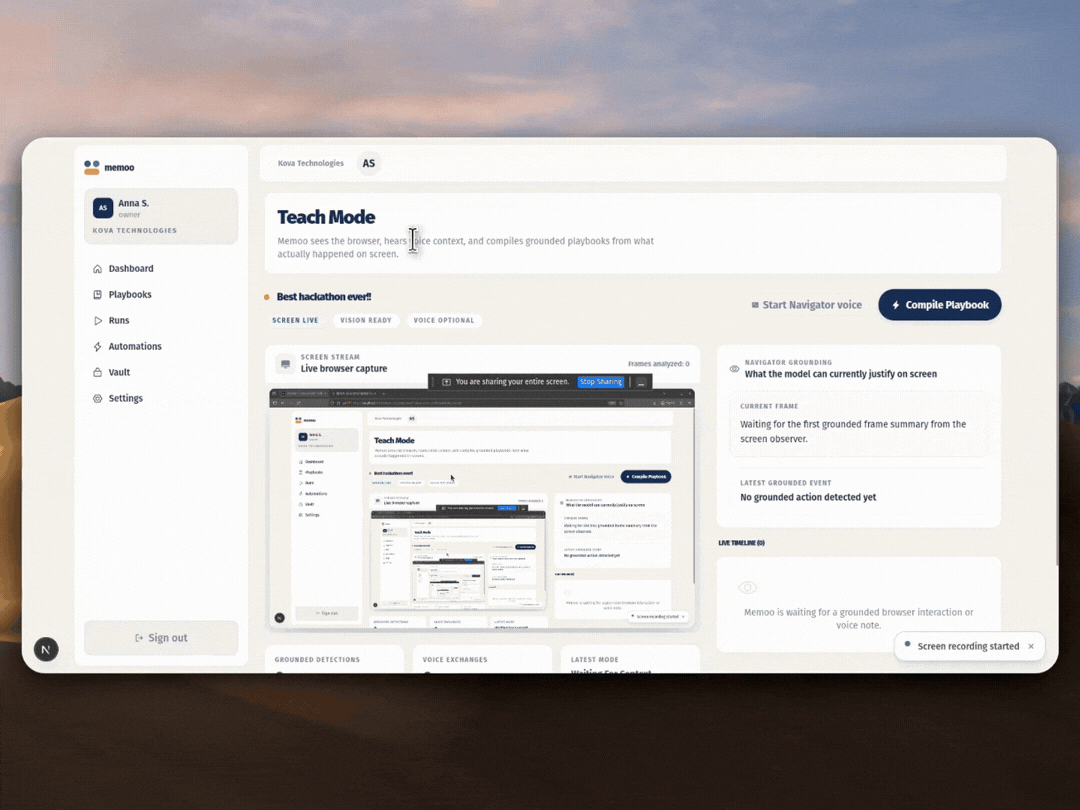
1. Multimodal capture. In Teach Mode, the browser streams frames to Gemini, which picks out the actions that actually matter based on what's visible on screen. At the same time, Gemini Live listens to your voice and can even ask you follow-up questions mid-session so the intent behind each step doesn't get lost.
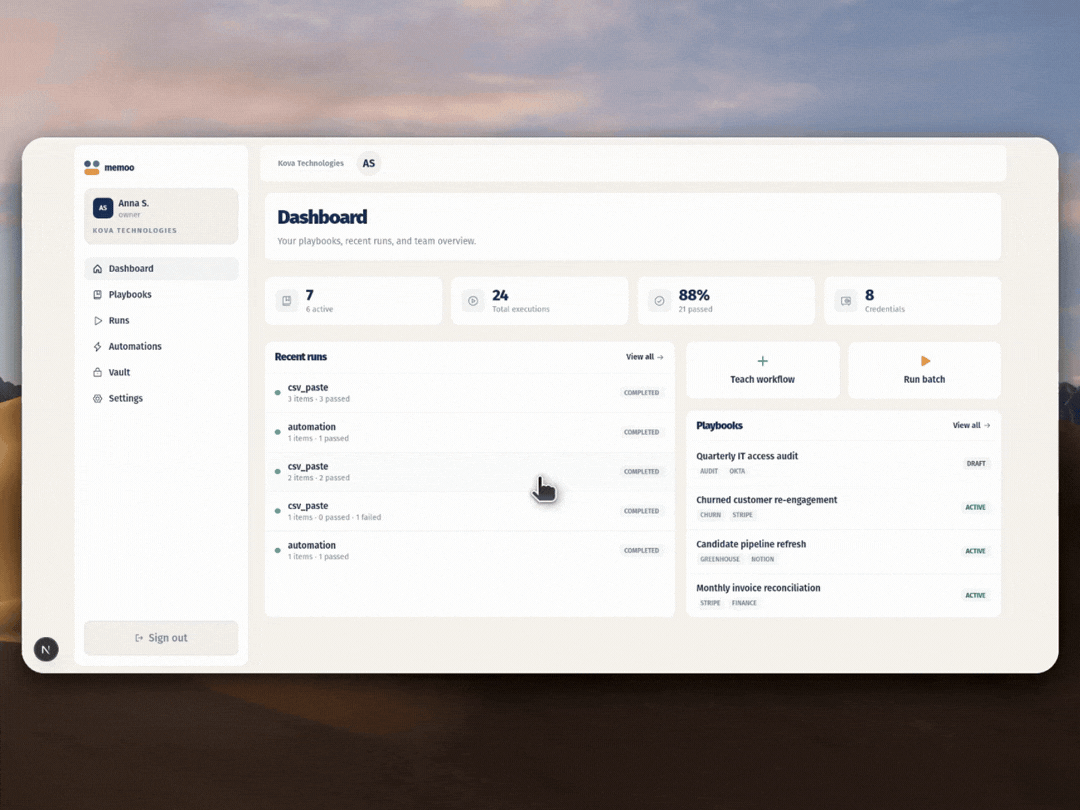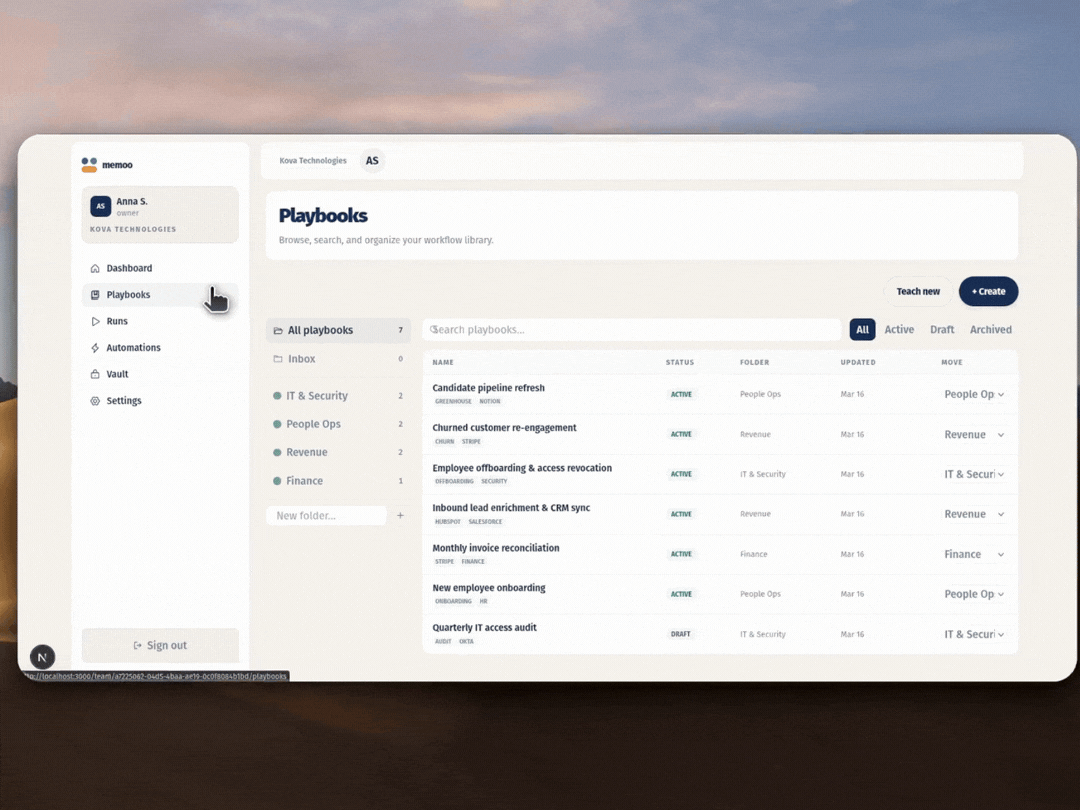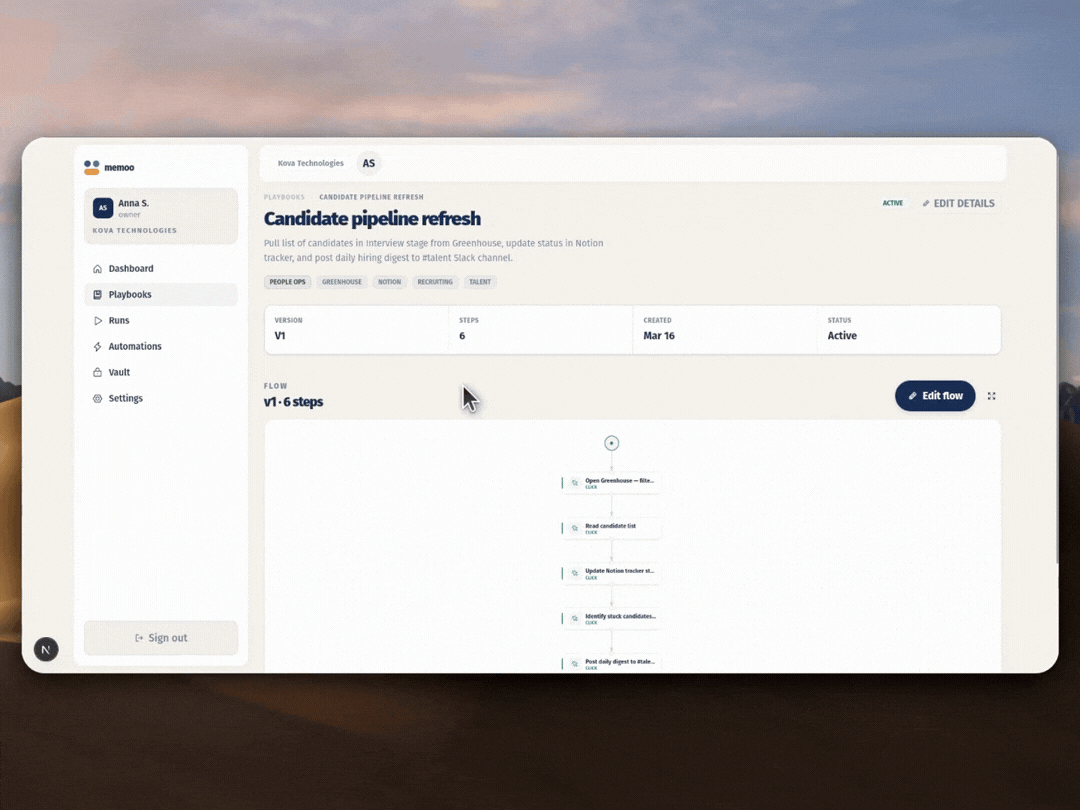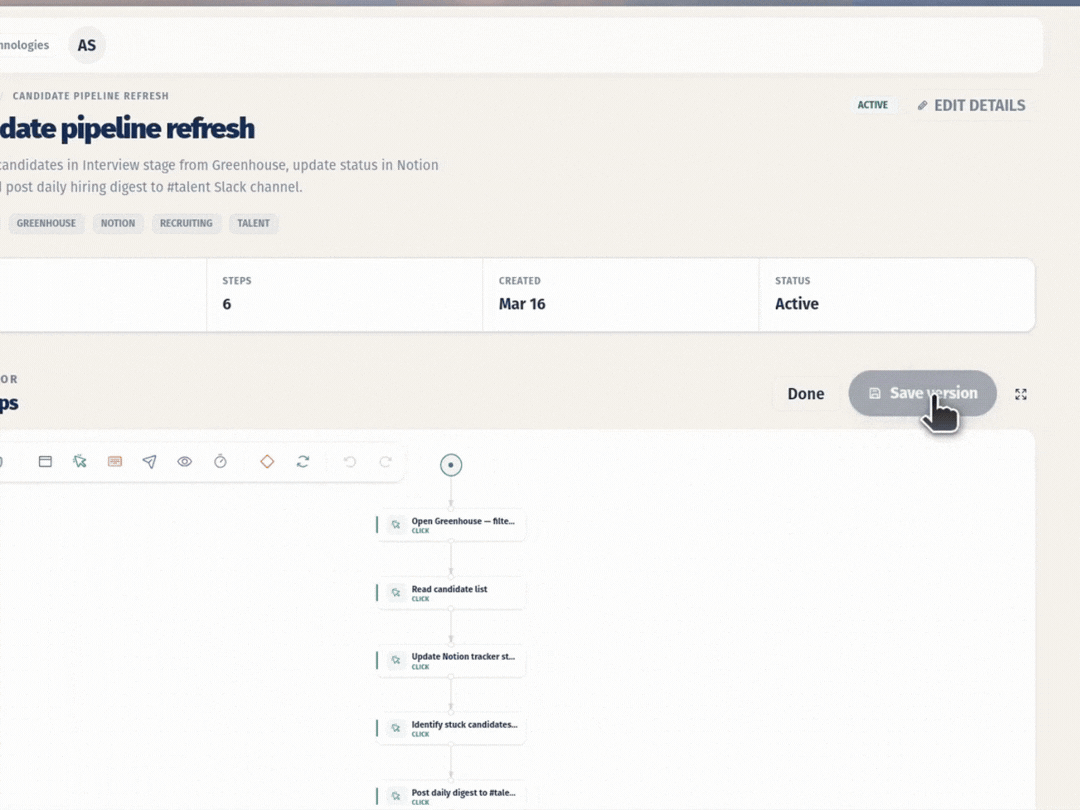
2. Semantic compilation. When the session is done, Gemini takes the raw events and voice notes and turns them into structured playbook steps: human-readable titles, CSS selectors, variable placeholders, and verification checks.
3. Resilient execution. Playwright runs each step inside a visible Chromium sandbox (Xvfb + noVNC + CDP). When a selector breaks because the UI shifted, the system hands off to a Stagehand-based agent backed by Gemini that navigates by what it sees on screen instead.
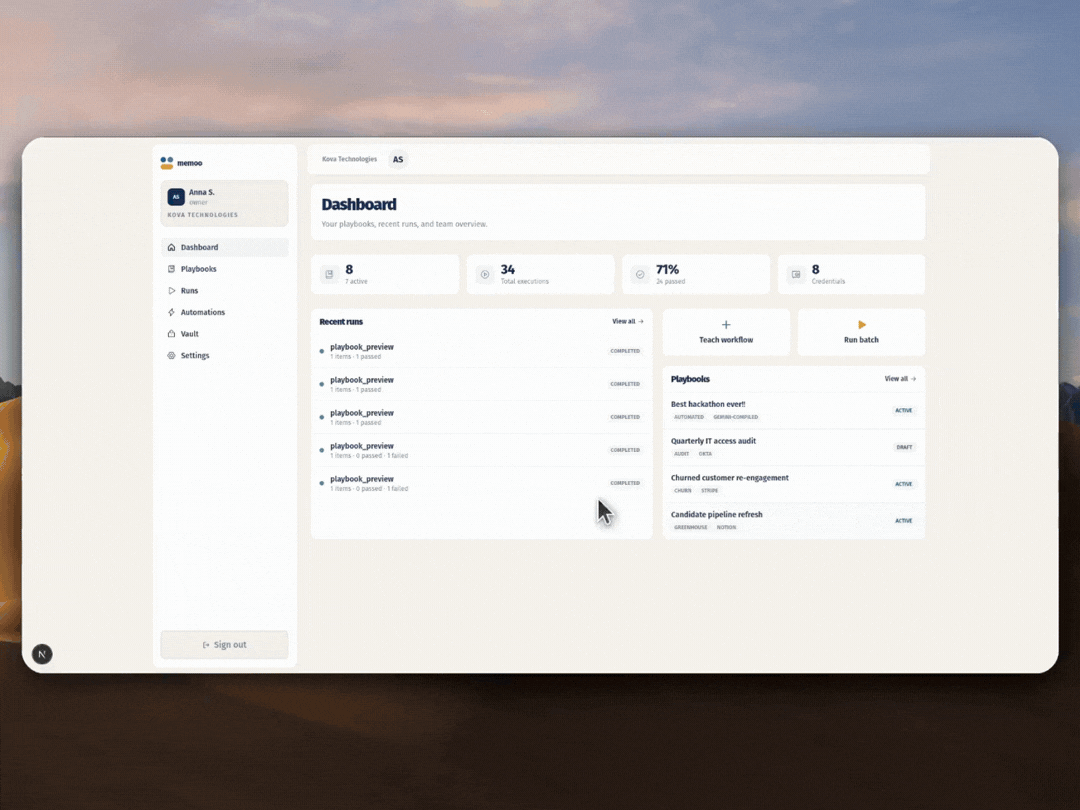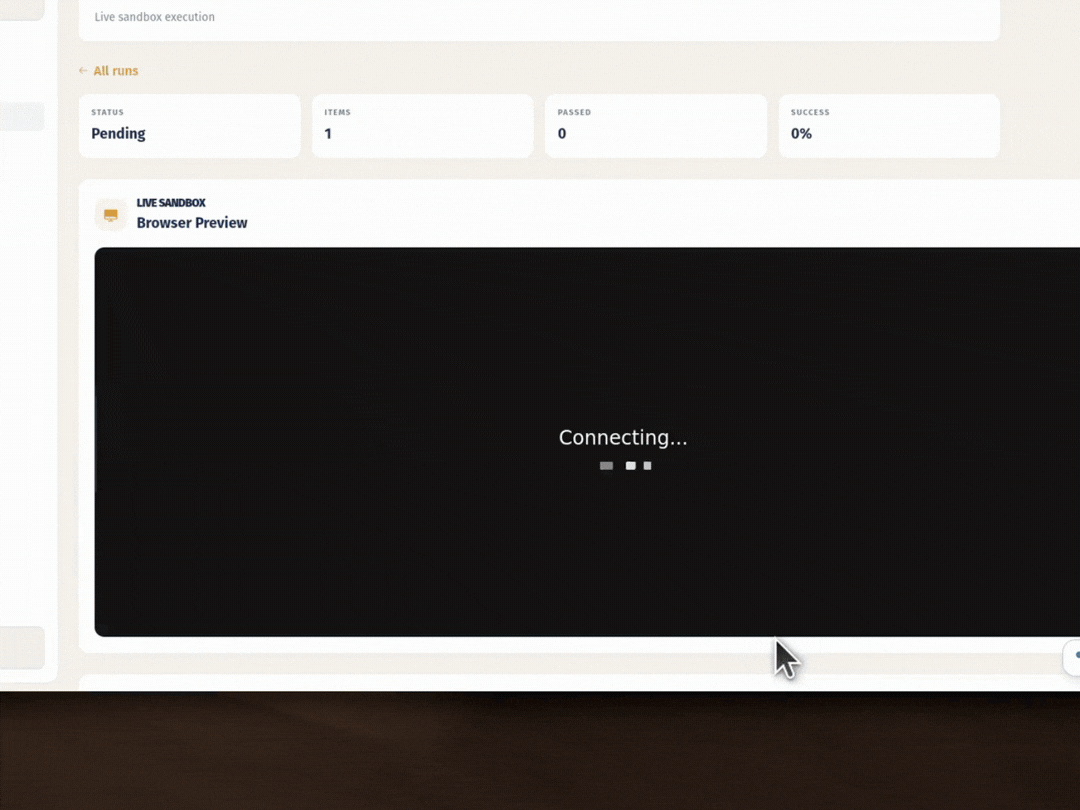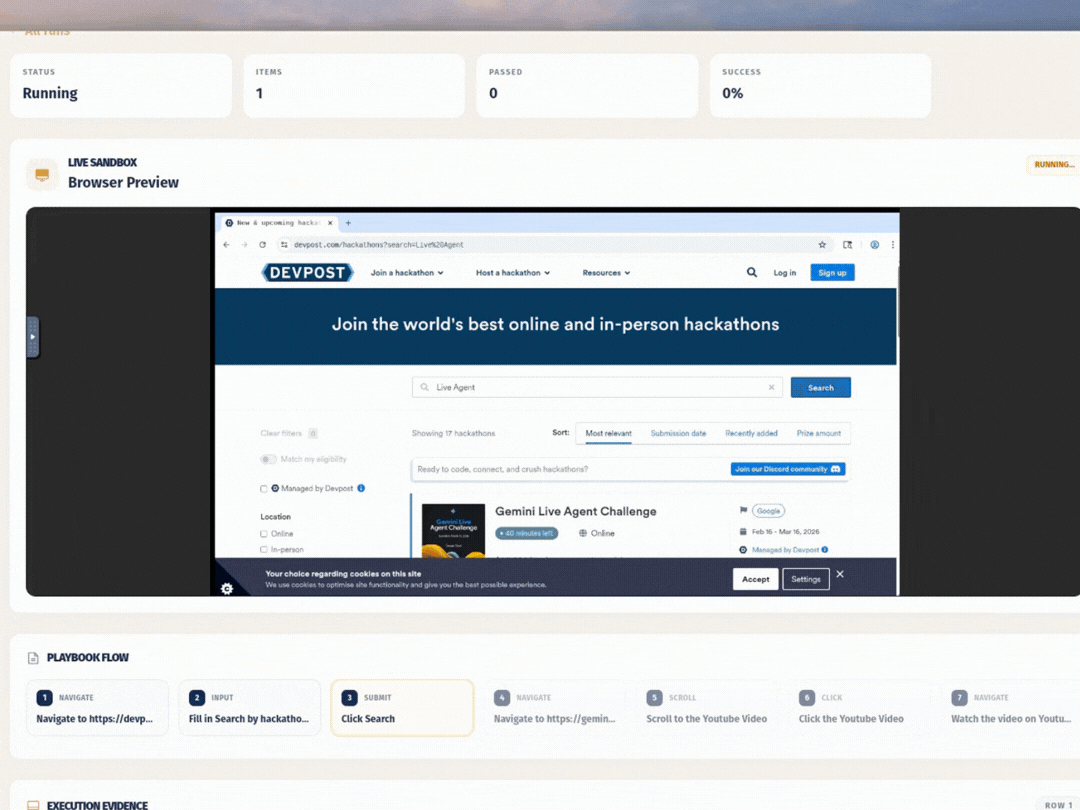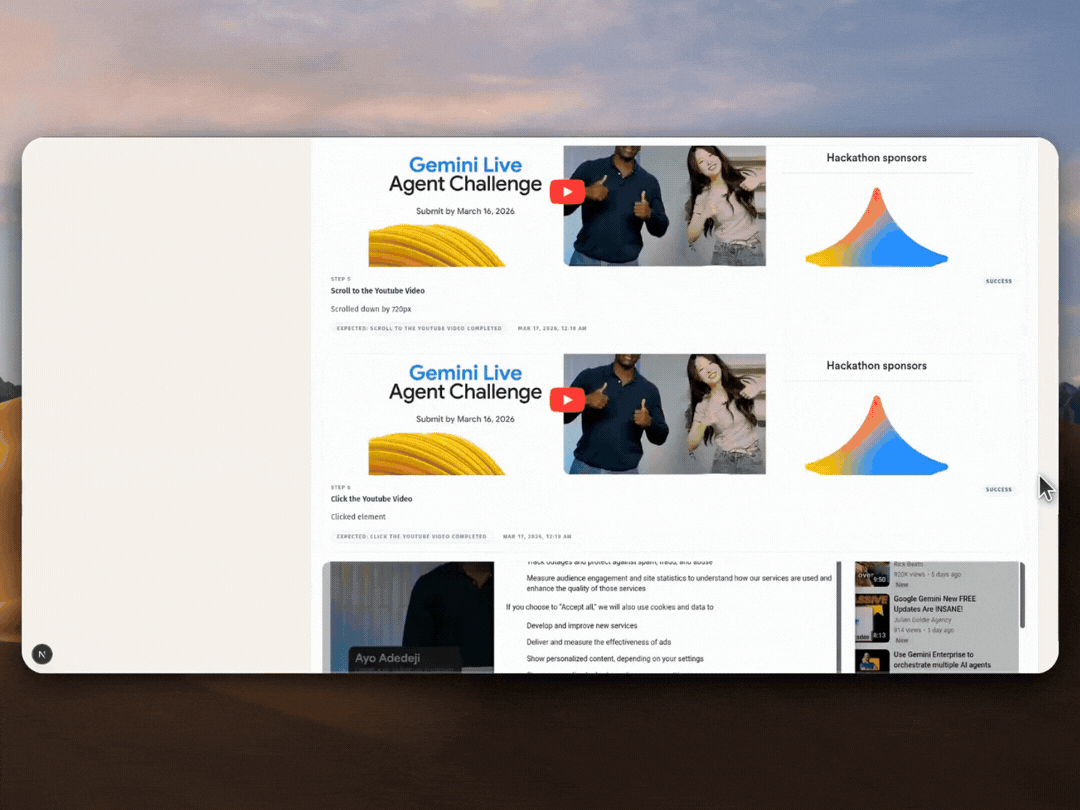
4. Evidence and collaboration. Every run saves a screenshot and result for each step. Teams share playbooks through folders, schedule automations by interval or webhook, and manage secrets in an encrypted vault.
The stack: Next.js 16 + React 19 on the frontend, FastAPI on the backend, PostgreSQL for data, MinIO/GCS for evidence storage, and full GCP deployment through Terraform (Cloud Run, Cloud SQL, Compute Engine for the sandbox VM) ![GCP Proof (https://youtu.be/M2mCkiibgEQ)] .
Challenges we ran into
Three things gave us the most trouble. First, getting Gemini's frame analysis to work reliably at scale. Raw screenshots produce a lot of noise, so we had to build a confidence threshold and a filtering pipeline that keeps only the actions that actually matter. Second, UI selectors break all the time. We ended up with a two-tier execution model: Playwright handles the deterministic path, and when that fails, a Gemini-powered visual agent takes over so runs don't just stop because a button moved 10 pixels. Third, syncing voice intent from Gemini Live with the visual capture timeline was tricky. Getting the timing right so the playbook steps come out coherent took more work than we expected.
Accomplishments that we're proud of
Gemini isn't a side feature here. It runs every stage: understanding the screen during capture, interpreting voice to capture intent, compiling steps into structured playbooks, and falling back to visual navigation when selectors fail. The two-tier execution (deterministic first, AI fallback second) means runs hold up when UIs change. And the whole thing deploys to Google Cloud with Terraform in one command. This isn't a thin wrapper around an API call. It's a working product with team workspaces, playbook versioning, scheduled automations, a credential vault, and visible execution with screenshot proof at every step.
What we learned
Teaching a workflow by showing it on screen works far better than scripting it by hand. But a good model alone doesn't make automation reliable. You need confidence filtering, a deterministic-first execution strategy, human-in-the-loop verification, and screenshot evidence so teams actually trust what happened. We also found that voice context carries more weight than we expected: a click on a dropdown means nothing if you don't know which option matters and why.
What's next for Memoo
We're working on three things: collaborative playbook libraries with versioning and team-wide sharing, parameterized runs that adapt playbooks to CSV data or API inputs so you can run the same workflow across hundreds of records, and a secure credential vault with role-based access so companies can roll Memoo out across departments without passing around passwords. After that, we want to add branching logic: if a condition on screen is met, take one path; if not, take another. That turns linear playbooks into workflows that can adapt on the fly.
Built With
- adminer
- bash
- concurrently
- docker
- docker-compose
- eslint
- fastapi
- framer-motion
- gemini
- google-cloud
- google-genai
- javascript
- minio
- next.js
- playwright
- postgresql
- pydantic
- python
- react
- ruff
- sql
- sqlalchemy
- sqlite
- tailwind-css
- typescript
- uvicorn
- zod



Log in or sign up for Devpost to join the conversation.