Mémoire
A shared brain for your whole family, living inside WhatsApp.
Inspiration
Every family has this group chat. Ours had about four hundred unread messages, three of which actually mattered: a school fee deadline, a prescription that needed refilling, and "someone please call the plumber." All three scrolled past. The plumber one cost us a flooded bathroom.
We kept trying the obvious fix — a to-do app, a shared calendar, a spreadsheet. They all died the same way. The two of us would use them for a week, and everyone else in the house quietly ignored them. The reason wasn't laziness. It was that the apps lived somewhere nobody else went. Our grandmother has never opened an app store in her life, but she sends voice notes every single day. Asking her to "just install this and make an account" was never going to work.
So we stopped trying to move people to a new place and built the helper where they already are. The insight was small but it changed everything: the task manager shouldn't be an app the family has to adopt. It should be a participant in the conversation the family is already having.
What it does
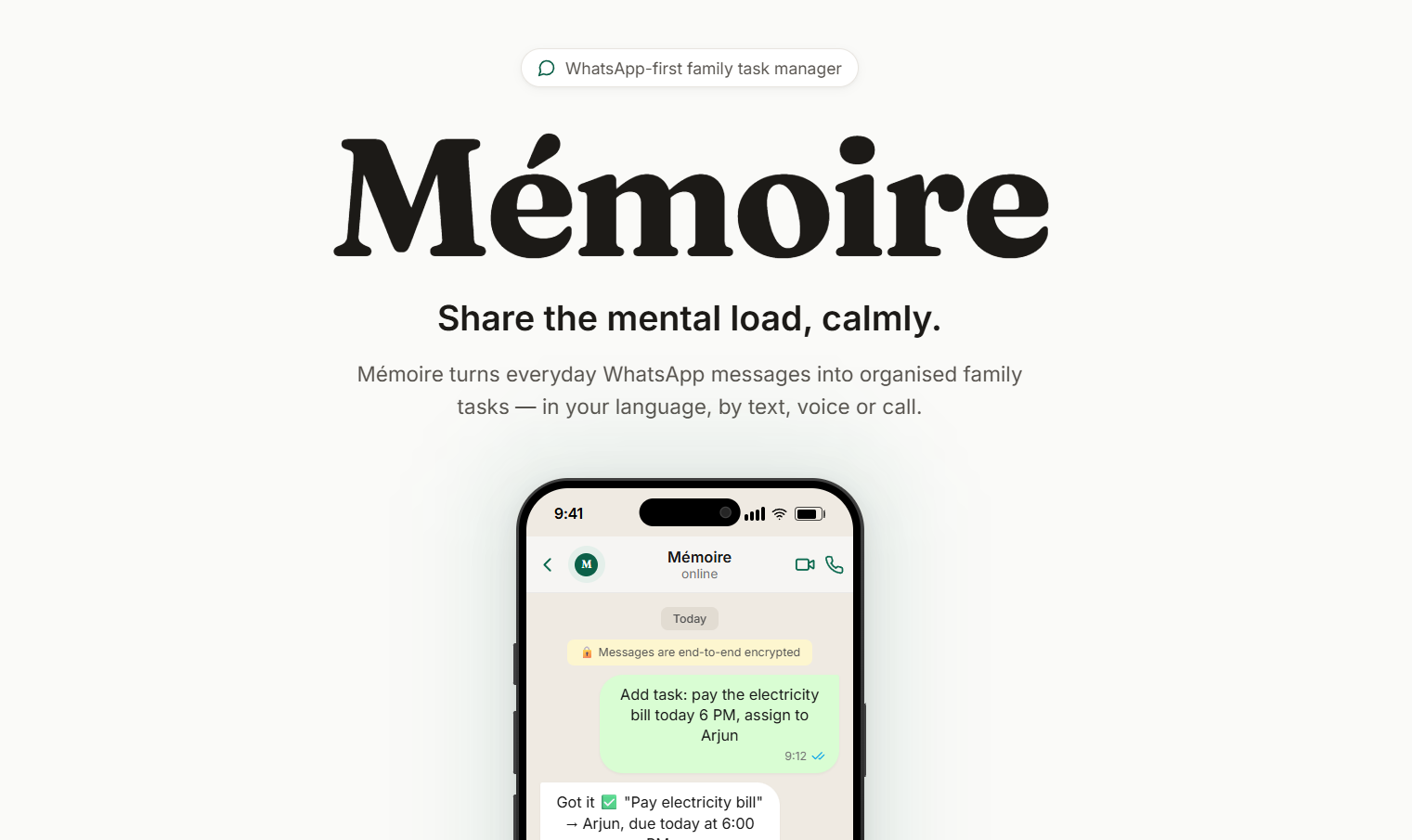
You talk to Mémoire on WhatsApp the way you'd talk to a person. Type "remind dad to pay the electricity bill tomorrow at 6" and it creates the task, assigns it, and quietly nudges him at the right time. Reply "done" and it closes. Send a voice note in Malayalam, Hindi, or Tamil and it understands you and answers back in the same language. And if something is genuinely urgent and keeps getting ignored, it will place a real voice call and talk it through with you.
It works in 27 languages, by text, voice note, or call, and it never asks anyone to read or type more than they want to — most choices are a single tap. A web console sits alongside it for whoever wants the bird's-eye view of who's doing what, but the console is optional. The whole product is designed so that a family can run entirely from the chat thread.
How we built it
The backend is a single Bun + Hono service in TypeScript, with PostgreSQL (via Drizzle) as the one and only data store — no vector database, no second system. One inbound message travels a fixed pipeline:
verify → dedupe → (transcribe / translate) → classify → route → act → reply → deliver
Understanding is split across two model tiers: a small, fast model reads every message for intent, mood, and a confidence score, and a stronger model powers the agentic assistant that handles open-ended requests. Speech and translation for Indian languages run through Sarvam; international languages route through OpenAI; live calls are handled by a separate WebRTC bridge into a conversational voice agent. Replies go out text-first, then voice, so a voice-note user gets a spoken answer but never a half-delivered one.
The discipline that saved us was building every stage behind an injectable port. The dedupe store, the model client, the sender, the translator — each has an in-memory fake, so we could run the entire pipeline end to end in tests with no network, no model calls, and no database. That let us change the message flow fearlessly, which we did, a lot.
Challenges we ran into
Almost all of our hard problems were in the flow, not the AI.
The five-second handshake. WhatsApp expects the webhook to answer in seconds, but transcribing a voice note, calling a model, translating, and replying takes longer than that. We split the request: verify the signature and acknowledge instantly, then do the real work after the acknowledgement, and send a read-receipt plus a typing indicator so the person isn't staring at a silent screen while we think.
At-least-once delivery. Meta re-sends webhooks and retries for days. Early on, one "done" sometimes closed a task twice or fired two replies. We made the whole path idempotent: each message ID is claimed exactly once, and every action that changes a task is keyed to that ID, so a replay is a no-op rather than a duplicate.
Two messages, one person, at once. When someone sends two quick messages, the two runs raced and corrupted the conversation state. We serialized processing per phone number — one person's turns run strictly in order, while different families still run in parallel.
English logic, human languages. Our time parsing and routing are English. A message in Malayalam broke them. The fix was to translate the inbound text to English for the machinery, keep the member's original words for context, and translate every reply back into their language and register, so a casual message gets a casual answer.
Acting without overreacting. A misread "done" should never quietly erase a task. We gate every destructive action on confidence: an action only fires when the model's confidence clears a threshold, $c \ge \tau, \qquad \tau = 0.6,$ and below that bar it asks instead of acting, and changes nothing. A hijacked or unlucky model can never be the thing that mutates your data.
What we learned
The model was the easy part. The trustworthy part — dedupe, ordering, idempotency, the careful fallbacks — is the unglamorous machinery that makes a conversation feel calm instead of flaky. We also learned that designing for the least-technical person in the house, the grandparent who only sends voice notes, forced cleaner choices for everyone: taps instead of typing, plain words instead of jargon, and a system that would rather ask than assume.
Built With
- aiortc
- amazon-web-services
- azure-ai-foundry
- biome
- bun
- docker
- docker-compose
- drizzle-orm
- elevenlabs
- fastapi
- ffmpeg
- github-actions
- hono
- i18next
- jose
- meta-graph-api
- nginx
- openai
- postgresql
- python
- react
- react-query
- react-router
- sarvam-ai
- tailwindcss
- typescrip
- vite
- webrtc
- whatsapp-cloud-api
- zod


Log in or sign up for Devpost to join the conversation.