-
-
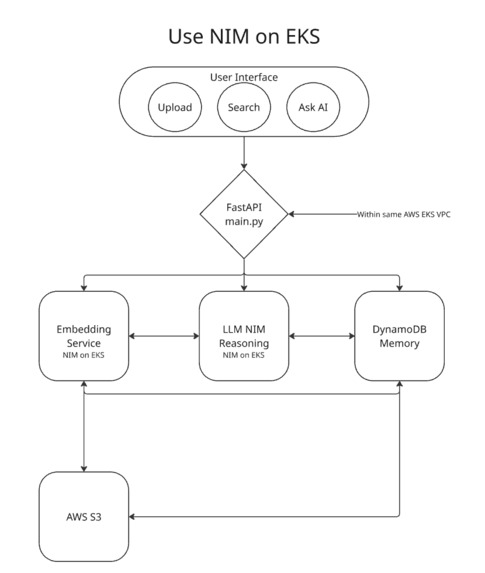
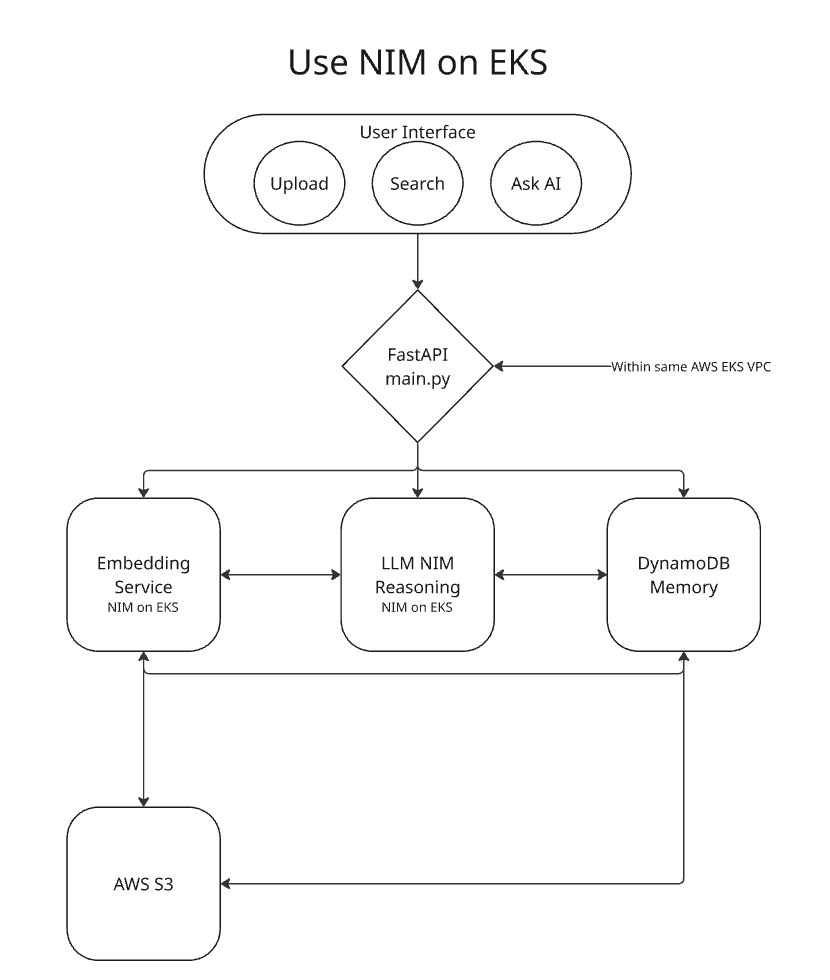
Use of NIM on EKS
-
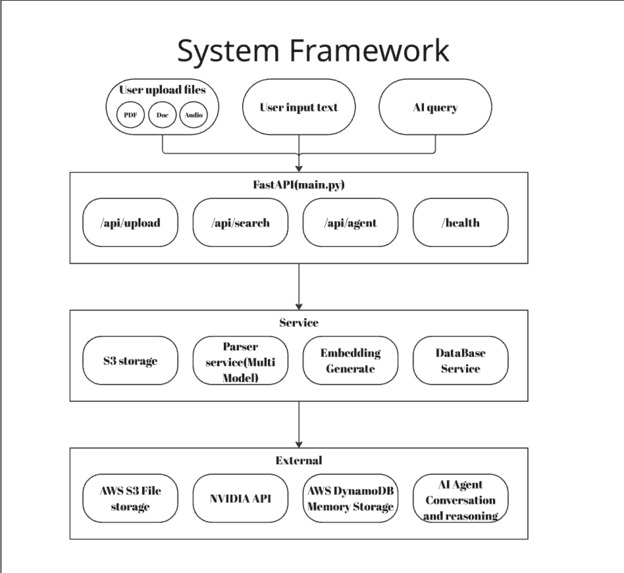
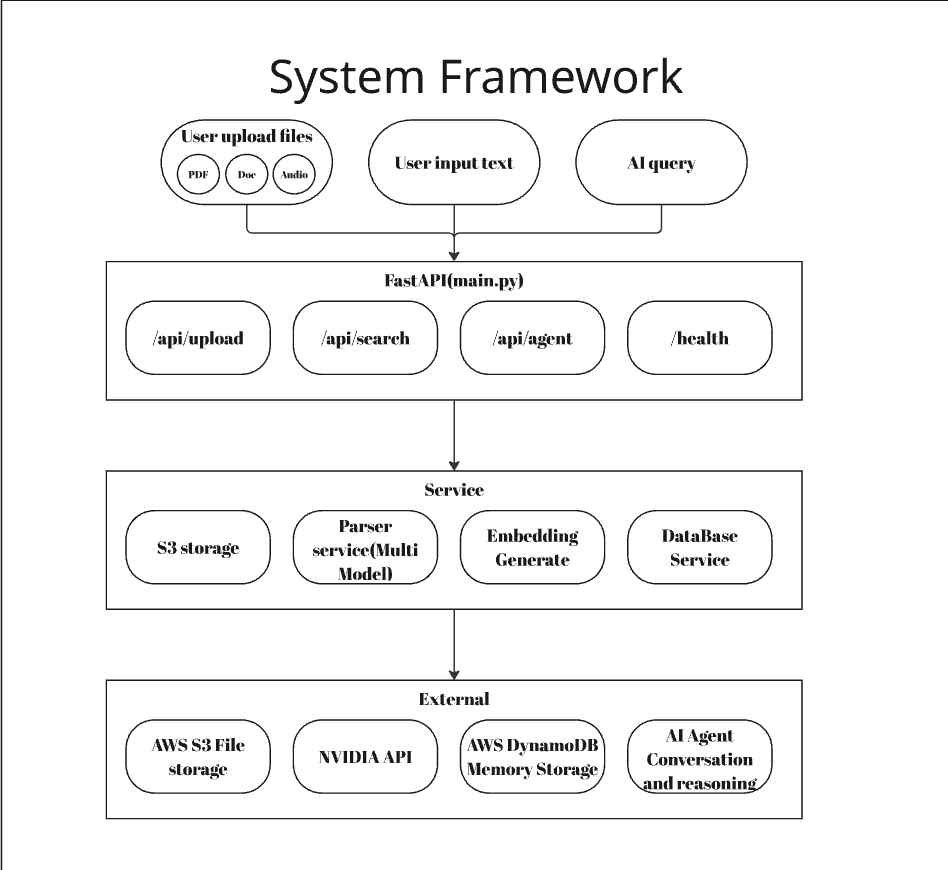
System Framework
-
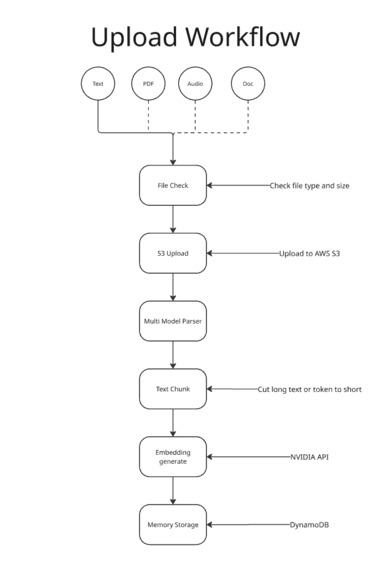
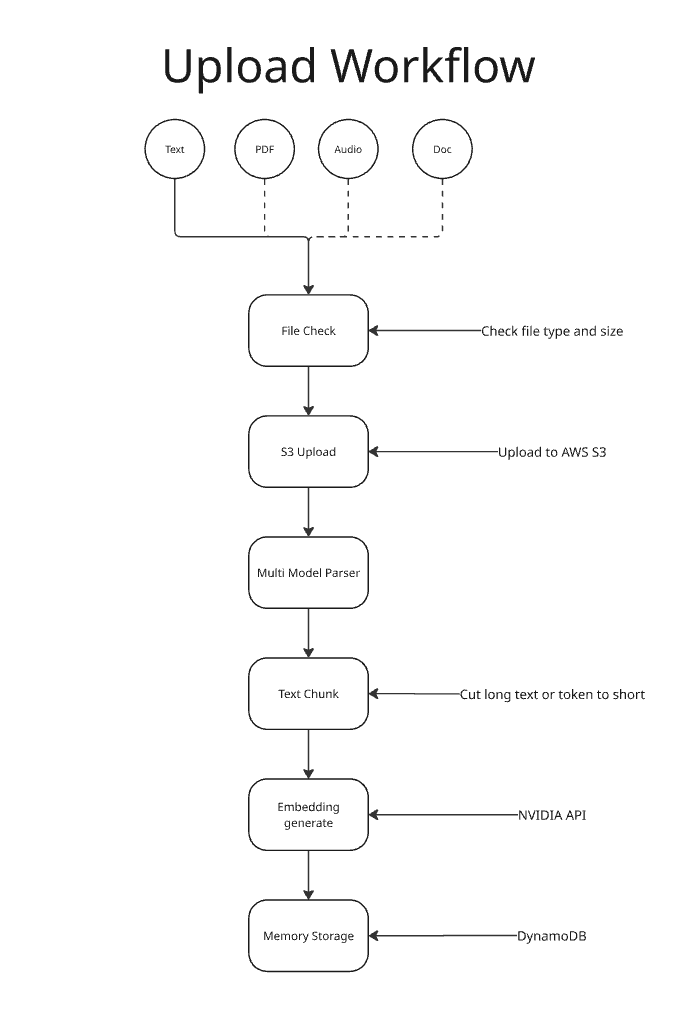
Upload Workflow
-
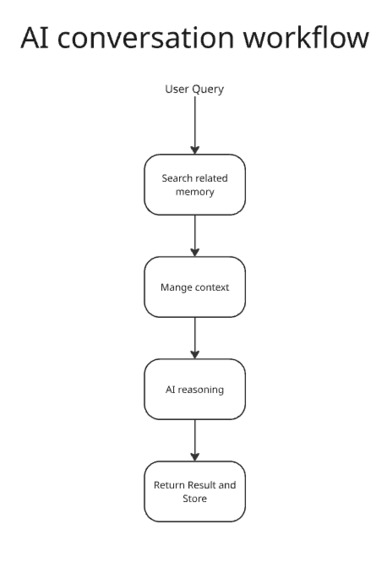
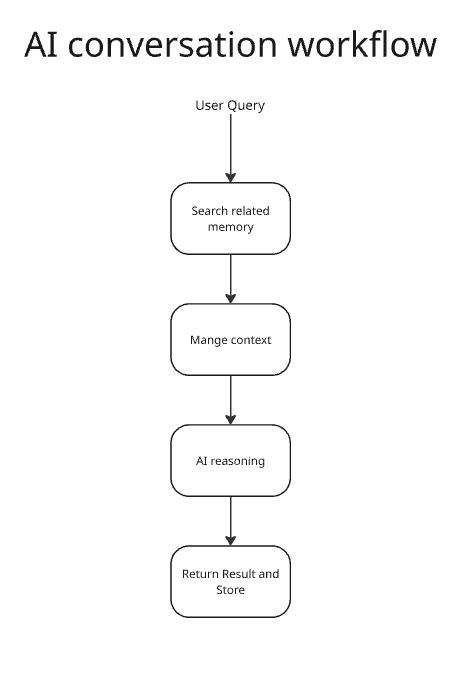
Al conversation workflow
-
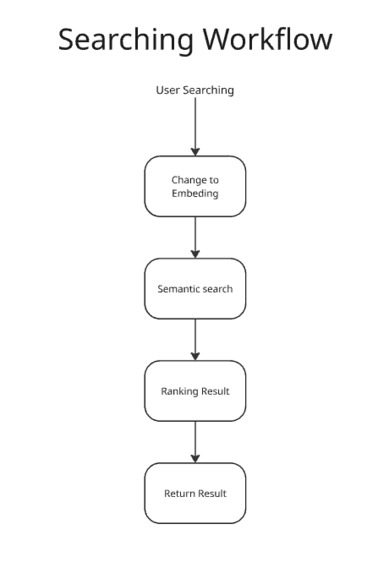
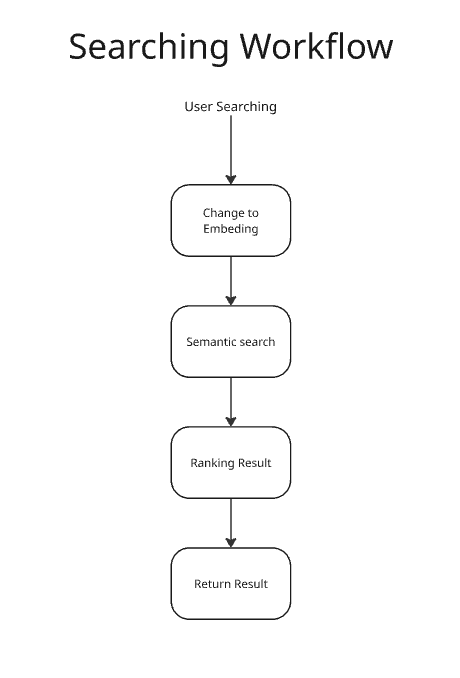
Searching Workflow
MemoHub: Your Personal USB for Every AI
Inspiration
Have you ever felt frustrated that every AI you use forgets everything?
You upload a file, switch models, and start all over again.
There’s no long-term memory, no shared context, and no unified place to store your data.
We wanted to change that.
MemoHub was inspired by the idea of a personal memory layer — a private hub where users can store, organize, and connect their files across different AI systems like GPT, Claude, or NIM.
What We Built
MemoHub is a personal memory platform that lets users upload text, images, and audio files, automatically generate embeddings, and make them searchable and chat-accessible through AI.
Core Features
- File upload and auto-tagging (docs, images, audio)
- 🔍 Semantic search powered by NVIDIA NIM Embedding Service
- Context-aware reasoning using NIM Nemotron-8B
- Integration with Google Drive and Notion
- Connector for AI integrations
- AI Chat interface connected to your personal memory library
How We Built It
Our backend runs entirely on AWS EKS, powered by NVIDIA NIM for both reasoning and embedding generation.
- Frontend: Next.js + Tailwind CSS
- Backend: FastAPI (Python)
- Inference: NIM Nemotron-8B (reasoning)
- Search: NIM Embedding Service (vector generation)
- Storage: AWS DynamoDB (metadata) + S3 (files)
- Database: pgvector (semantic retrieval)
- Authentication: Supabase
- Orchestration: LangChain + custom agentic flow
[ \text{Response} = f(\text{query}, \text{retrieved_embeddings}) \rightarrow \text{LLM}(context) ]
Workflow
- User uploads a file → parsed and sent to Embedding NIM → converted into vector embeddings.
- Embeddings + metadata stored in DynamoDB + S3.
- When a user asks a question, MemoHub retrieves the most relevant embeddings and forwards them to Nemotron-8B for reasoning.
- The backend returns the response to the chat interface.
[ \text{Response} = f(\text{query}, \text{retrieved_embeddings}) \rightarrow \text{LLM}(context) ]
What We Learned
- How to deploy NVIDIA NIM models on Amazon EKS and optimize GPU workloads.
- How to design a scalable memory retrieval pipeline using pgvector and DynamoDB.
- How to orchestrate multi-step reasoning through FastAPI and microservices.
- How to create a smooth user experience for multimodal data storage and retrieval.
Most importantly, we learned that memory is what makes AI feel truly useful
Challenges We Faced
- Version compatibility: Setting up the right EKS version to support NIM microservices took multiple attempts.
- NIM container access: Some regions had limited access to NVIDIA NIM APIs, requiring extra configuration.
- Multi-modal embedding: Handling and embedding images consistently required custom preprocessing pipelines.
Each challenge pushed us to think like engineers and product designers — solving real integration and deployment problems at scale.
What’s Next
We’re expanding MemoHub into a fully functional “Memory-as-a-Service” API that lets users connect their data across any LLM safely and privately.
Upcoming Features
- Multi-user collaboration
- AI-generated summaries for synced content
- Visual knowledge graph for contextual search
Built with ❤️ for the NVIDIA × AWS Hackathon 2025
Built With
- amazon-web-services
- aws-dynamodb
- aws-ec2-(g5-gpu)
- aws-eks
- docker
- fastapi
- langchain
- next.js
- nvidia-nim-embedding-service
- nvidia-nim-nemotron-8b
- postgresql
- python
- supabase
- tailwind-css
- typescript

Log in or sign up for Devpost to join the conversation.