-

Out of sample Meme
-

In Sample Meme
-
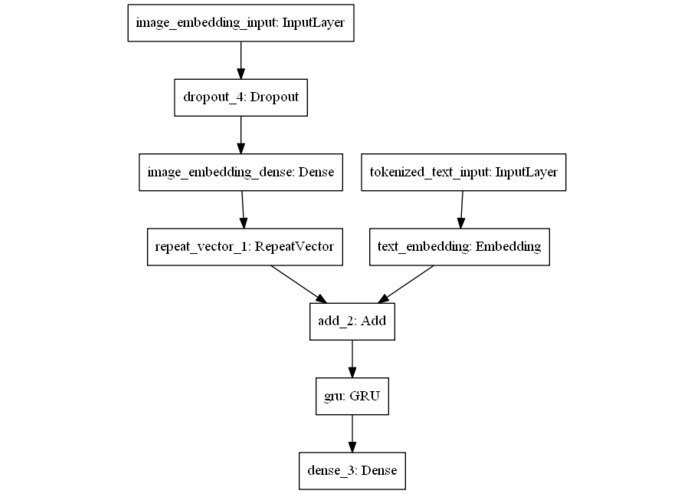
Network Architecture


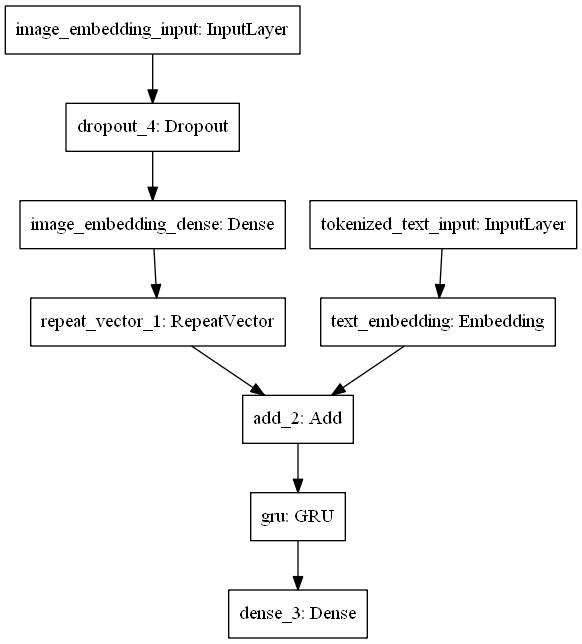
Inspiration
Inspired by Show and Tell: A Neural Image Caption Generator and Dank Learning: Generating Memes Using Deep Neural Networks, we decide to explore the ideas of creative work with image-captioning using deep neural networks.
What it does
Our app generates meme text based on an image input using our trained Tensorflow Keras model. The model endpoint is deployed both locally and on AWS Sagemaker. After the text for an image is generated, we send it to our Twitter app on the front end to integrate and annotate the image with the text and post it to Twitter. We are hoping to gauge the quality of the generated meme once we have enough followers.
How we built it
We scrapped both images and texts from various different websites such as Imgflip, Reddit, Google/Bing images search, etc and store them in an S3 bucket on AWS. We scrubbed the input text out of foreign languages and obscenities and we ended up with 108 images and around 200 memes per image.
We built our par injected meme generation model using Tensorflow Keras with built with the following architecture.
 . We used pre-trained InceptionV3 weights with
. We used pre-trained InceptionV3 weights with globalaveragepooling2d to encode the preprocessed images into an image vector. We used an embedding layer to encode the training text data into text embedding. Then we combine both the text and image embedding together and use a GRU layer as the decoder.
At evaluation time, we only use an image embedding encoder and GRU decoder. We used beam-search to return the top 5 best memes generated to achieve variations to our model outputs.
We design and tune the models on our local machine with NVidia GTX 10x0 GPU and then on an AWS p3.2xlarge (NVidia V100) Sagemaker instance for our final training.
Challenges we ran into
Typical NLP tasks are one-to-one or one-to-few mappings and use metrics such as BLEU/ROGUE scores. But for our creative work, we have one-to-hundreds mapping. There are no good quantitative metrics for determining the quality of the output text. As a brute force method, we checkpoint and save our model every 10 epochs, generate text from in-sample images, and determine the quality of the output with human evaluation. To scale this up, we decided to use our Twitter frontend to gather qualitative feedback.
The second challenge we ran into is to figure out a way to generate different memes each time we feed in the same image. The idea is simple: to tell a story from an image, people do not tell the same story verbatim every time they see the same picture. We tried two different methods. First, we tried to add gaussian noise to the input images. We tried random noise in the range of 1-20%. The result was not as well as expected; it made multiple different in-sample memes images generate the same text. Then, we tried and settled with beam-search with a beam size of 5. We found that the top 5 texts generated usually have pretty close scores with each other due to the wide diversity of our 'reference' texts.
One other major challenge we ran into is the inference speed budget for our AI meme generator. Originally, we deployed both the encoder model and the decoder model together with the REST API endpoint. While it works fine, the inference speed is quite slow at almost half a minute per beam search with the endpoint crashing. We found that increasing the endpoint compute power alleviate that somewhat at a great monetary cost. We also tried to separate out the model serving from the API endpoint to take advantage of Tensorflow Serving's speed and batch inferencing. While that works great, the monetary cost of using either AWS ECS or EKS greatly exceeded our compute budget. At the end, we opt to serve batch-transformed images and texts to fit our compute budget.
Accomplishments that we're proud of
We were able to work around our extremely limited budget to train a large image-to-text encoder-decoder model. We were especially proud of the memes that it can generate and all the engineering decisions we made to make the model/app work in real-time.
What we learned
If we knew what we know now, we might have gone with Tensorflow 2.0 framework from the getgo for more flexibility to try out different models. And separate out model serving endpoints with the app API endpoints early on in the process.
What's next for Memefly
We intend to keep on iterating on the models and data to better understand creative works using deep learning. Further, we will be posting AI-generated memes on @memefly2 and use the replies, retweets, and likes to gauge the quality of the meme.
Built With
- amazon-web-services
- keras
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.