-
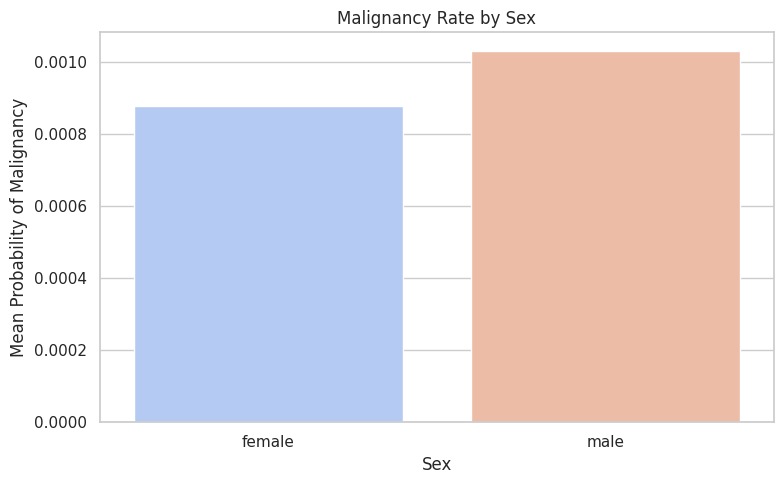
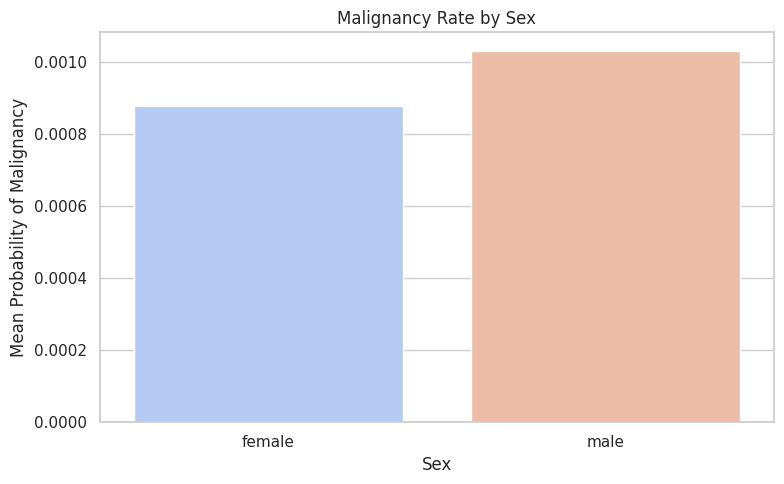
melanoma by sex
-
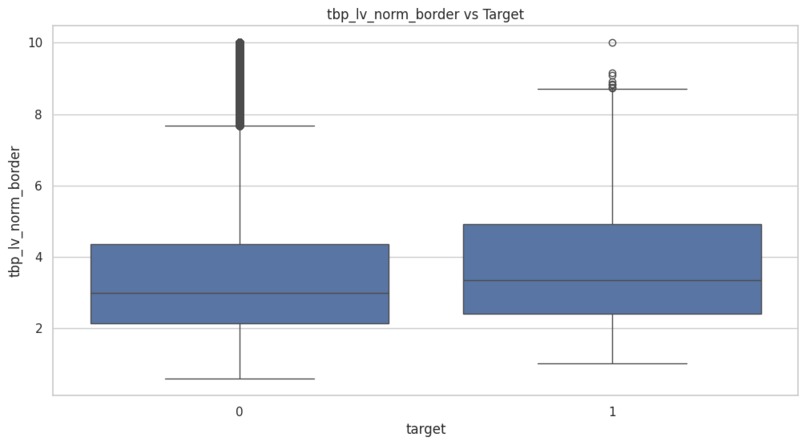
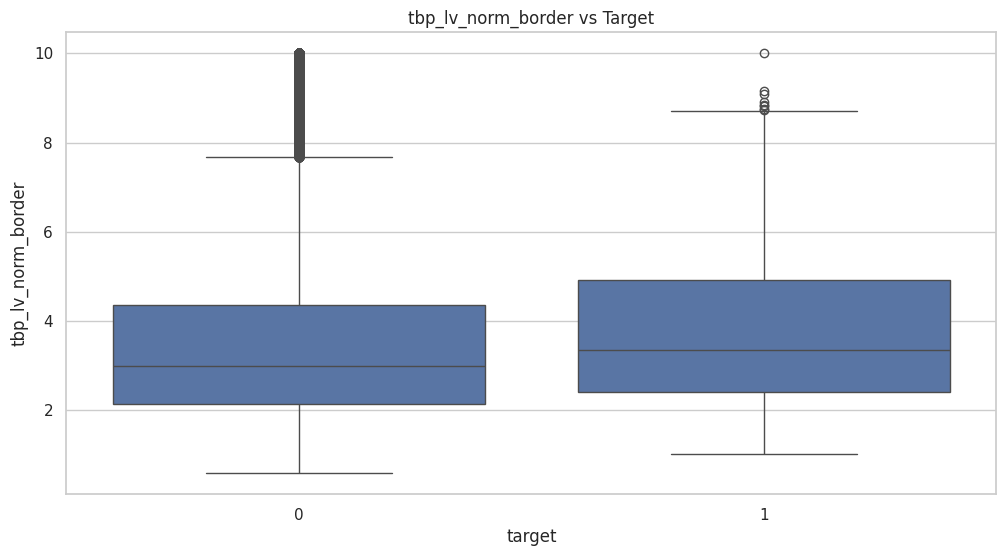
box plot
-
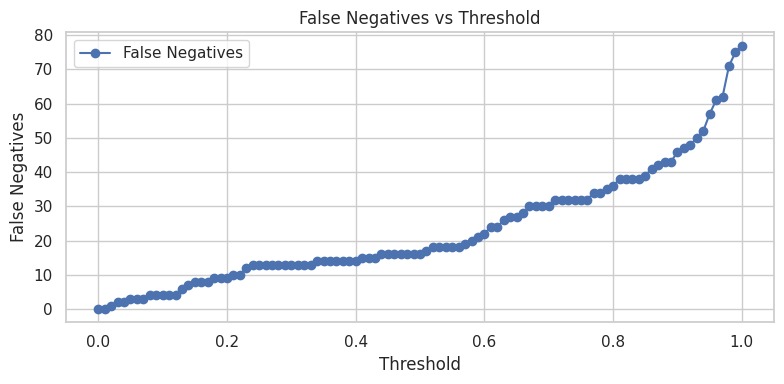
thresholds
-
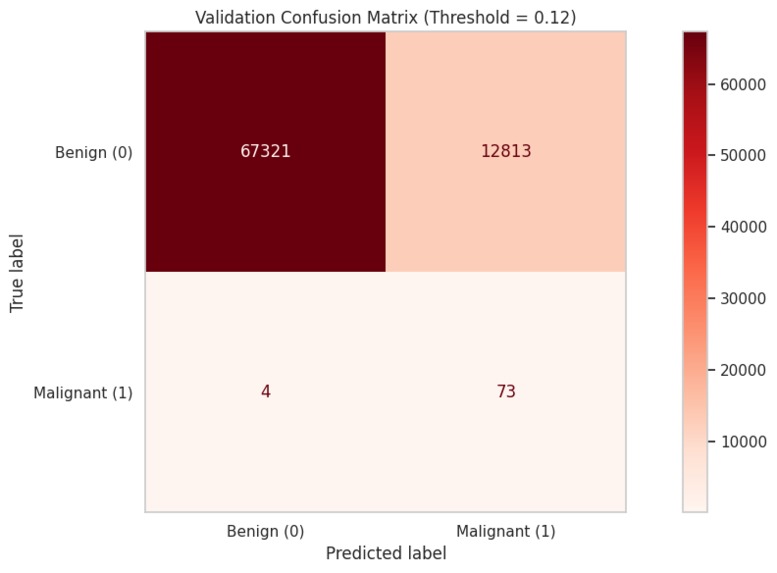
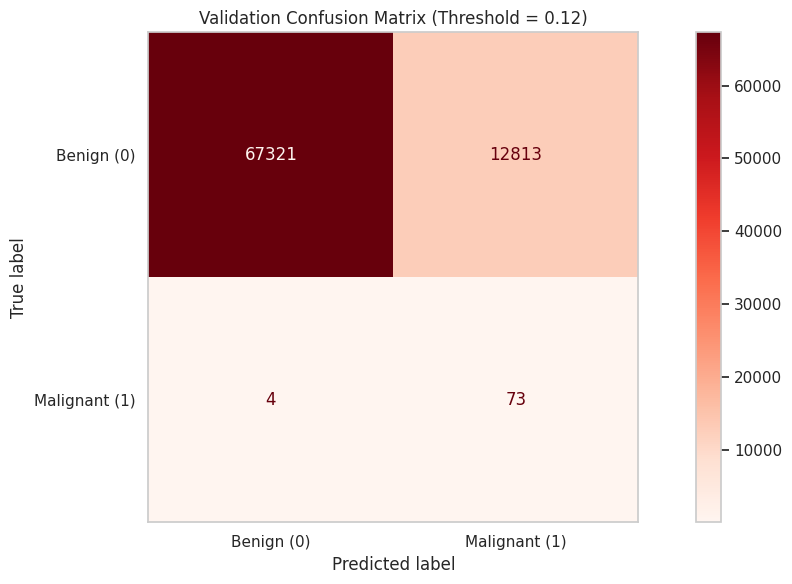
confusion matrix
-
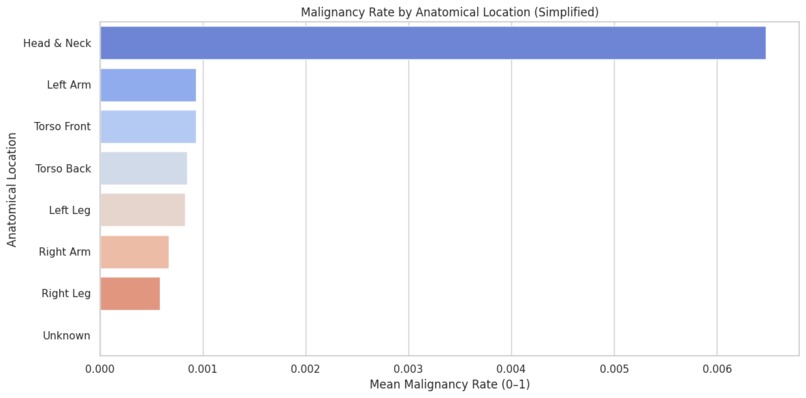
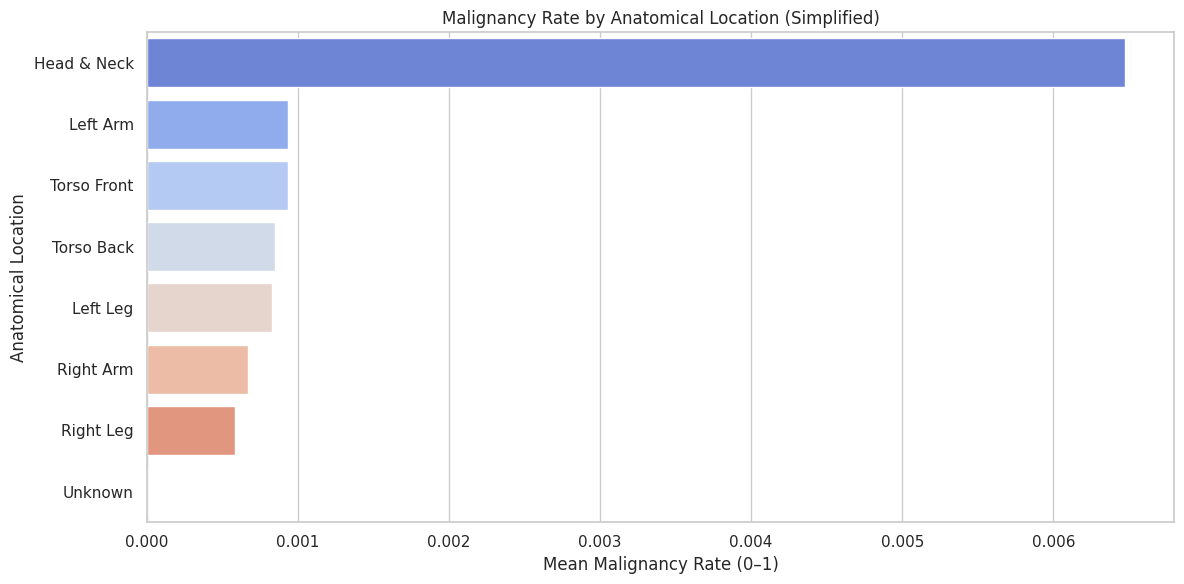
melanoma by location
-
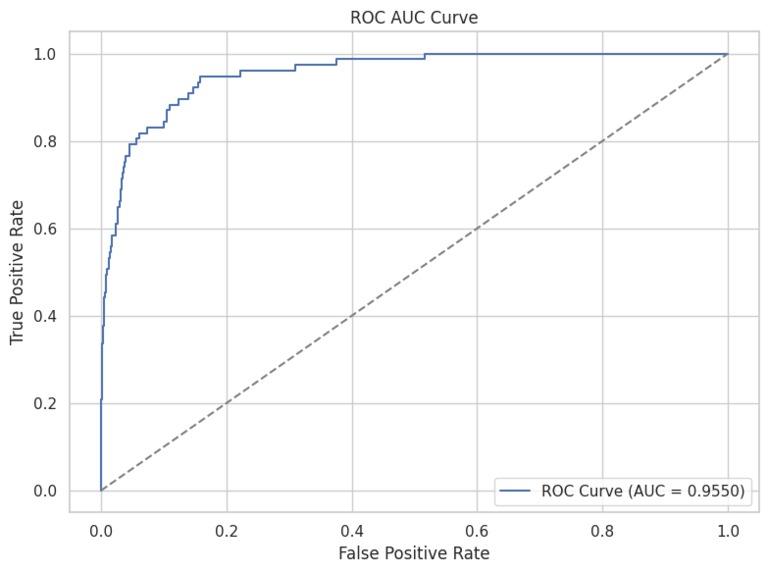
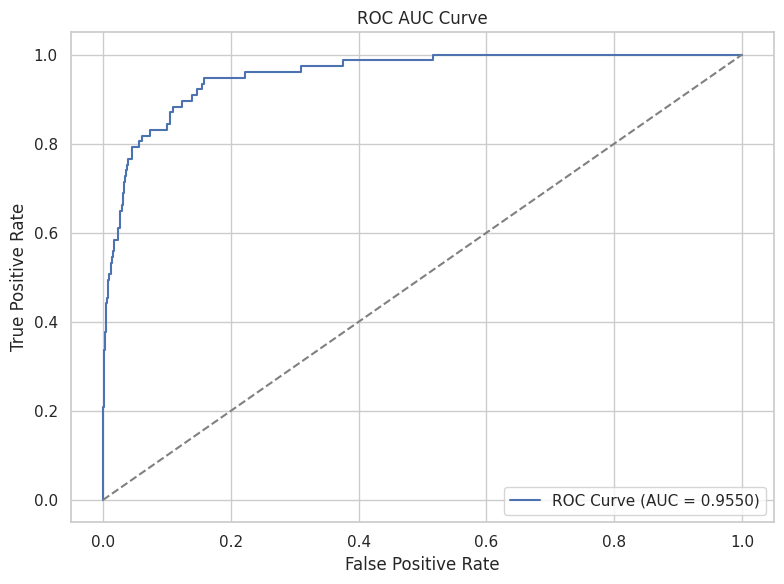
roc-auc curve
-
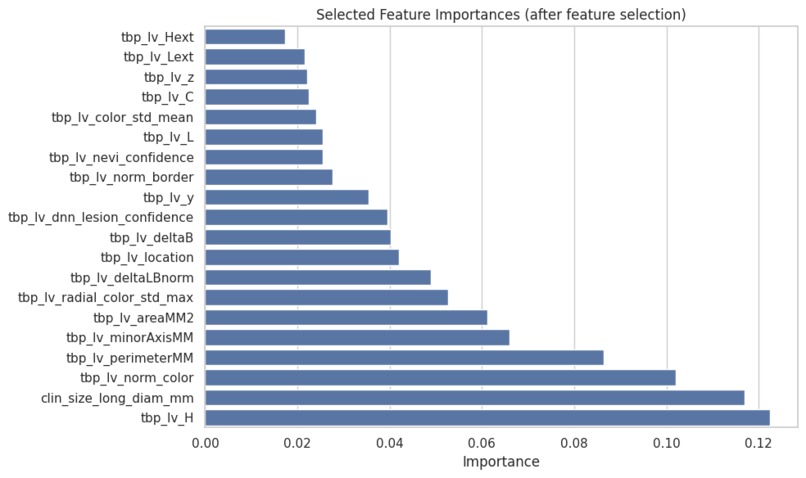
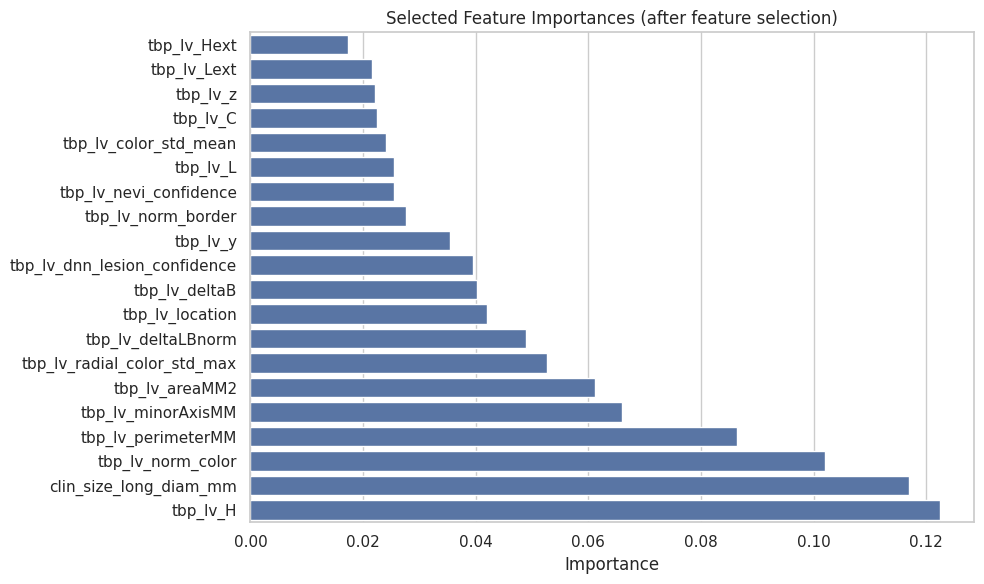
feature importance
-
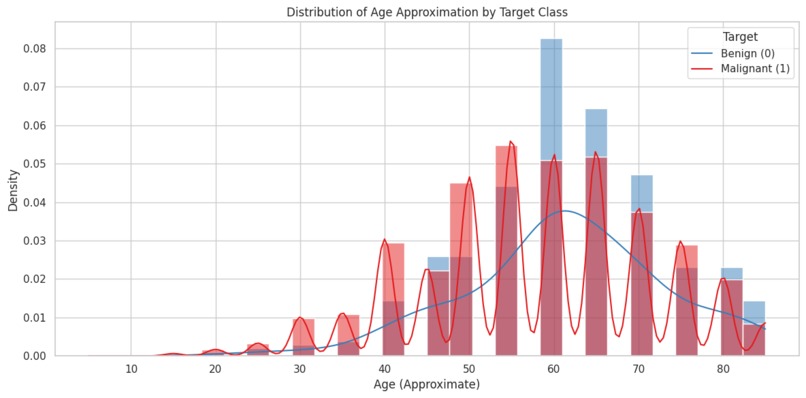
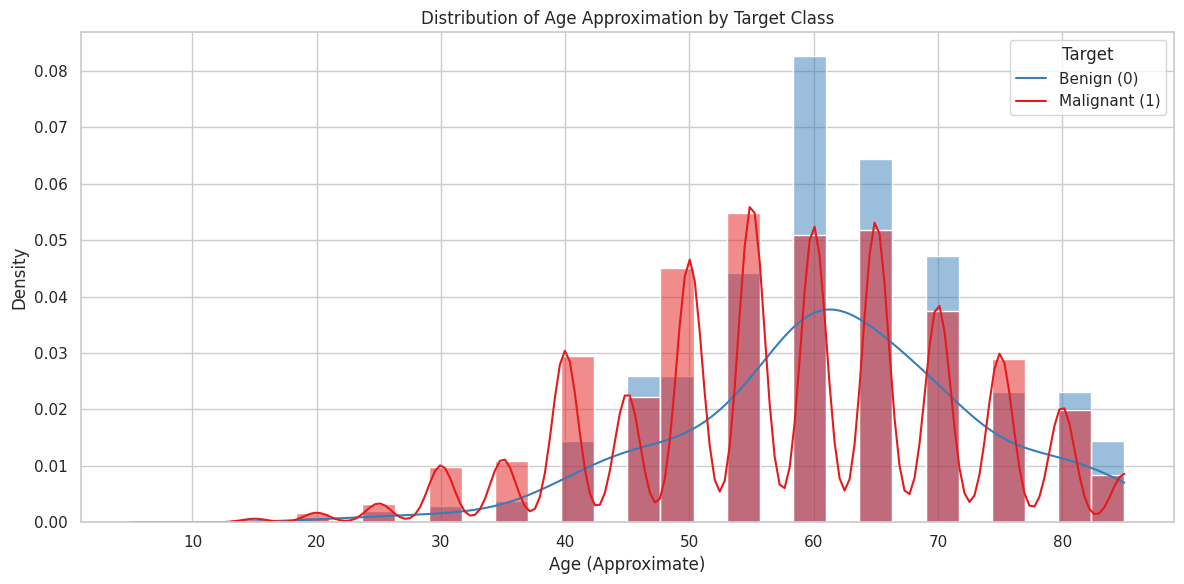
age distribution

Skin Lesion Classification Model
Project Overview
This project implements a machine learning system for the classification of skin lesions as either benign (0) or malignant (1). The model is designed to assist medical professionals in the early detection of skin cancer by providing an automated assessment of skin lesion images.
Dataset: SLICE-3D
The model uses the SLICE-3D (Skin Lesion Images in Clinical Environment - 3D) dataset, which contains:
- High-quality dermatological images of skin lesions
- Rich metadata including patient demographics, lesion characteristics, and clinical measurements
- Expert-labeled classifications (benign/malignant)
Features
This repository contains:
- Data exploration and analysis scripts for understanding the dataset
- Feature engineering processes to extract meaningful information from metadata
- Two separate models:
- XGBoost model using only metadata features (without images)
- Basic CNN model for image-based classification
- Evaluation metrics focused on clinical relevance (prioritizing minimizing false negatives)
- Threshold optimization to balance sensitivity and specificity
Key Aspects of the Model
Metadata-Based Classification (XGBoost)
- Uses patient metadata and lesion measurements without requiring images
- Includes features like:
- Patient demographics (age, sex)
- Anatomical location (body site)
- Lesion geometry (size, perimeter, area)
- Color metrics (lightness, color variation)
- Border and symmetry characteristics
Image-Based Classification (Simple CNN)
- Basic convolutional neural network for image classification
- Processes images from HDF5 file format
- Serves as a baseline for future improvements
Class Imbalance Handling
- Uses stratified group k-fold cross-validation
- Implements class weighting techniques
- Adjusts prediction thresholds for clinical relevance
Clinical Relevance Focus
- Prioritizes minimizing false negatives (missed malignant lesions)
- Customizable threshold to balance sensitivity vs. specificity based on clinical needs
Installation
Prerequisites
- Python 3.8+
- Required packages:
pandas numpy matplotlib seaborn scikit-learn xgboost tensorflow h5py Pillow tqdm
Setup
Clone this repository:
git clone https://github.com/yourusername/skin-lesion-classifier.git cd skin-lesion-classifierInstall required dependencies:
pip install -r requirements.txtDownload the dataset files:
train-metadata.csv- Training set metadatatest-metadata.csv- Test set metadatatrain-image.hdf5- Training images- Place these files in the project root directory
Usage
Data Exploration
Run the exploratory data analysis notebook to understand the dataset:
jupyter notebook eda.ipynb
Training the XGBoost Metadata Model
# Example code snippet
import pandas as pd
from sklearn.model_selection import StratifiedGroupKFold
from xgboost import XGBClassifier
# Load and preprocess data
train_df = pd.read_csv("train-metadata.csv")
# Preprocessing steps as shown in the notebook...
# Define features and target
X = train_df.drop(columns=['target', 'isic_id', 'patient_id'])
y = train_df['target']
groups = train_df['patient_id']
# Split using stratified group k-fold
cv = StratifiedGroupKFold(n_splits=5)
for train_idx, val_idx in cv.split(X, y, groups):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
break # Just use the first fold for simplicity
# Train the model
model = XGBClassifier(
n_estimators=200,
learning_rate=0.05,
max_depth=4,
subsample=0.8,
colsample_bytree=0.8,
scale_pos_weight=1000,
eval_metric='aucpr',
random_state=42
)
model.fit(X_train, y_train)
Making Predictions
# For metadata model
test_df = pd.read_csv("test-metadata.csv")
# Preprocessing steps...
predictions = model.predict_proba(X_test)[:, 1]
# Apply custom threshold (e.g., 0.12 instead of default 0.5)
binary_predictions = (predictions >= 0.12).astype(int)
# Create submission
submission_df = test_df[['isic_id']].copy()
submission_df['predicted_probability'] = predictions
submission_df['predicted_label'] = binary_predictions
submission_df.to_csv("submission.csv", index=False)
Model Performance
XGBoost Metadata Model
- ROC AUC: ~0.92 (validation set)
- PR AUC: ~0.72 (validation set)
- At threshold 0.12:
- False Negative Rate: ~5.2%
- False Positive Rate: ~16%
CNN Image Model
- Basic implementation for demonstration purposes
- Performance depends on training parameters and architecture
Key Findings
- Anatomical location plays a significant role in malignancy risk (e.g., higher rates on certain body parts)
- Age shows a clear correlation with malignancy risk (increases with age)
- Border irregularity and color variation are strong predictors of malignancy
- False negative minimization is achievable with threshold adjustment (0.12 provides good balance)
- Patient-level stratification improves model generalization
Customizing the Model
- Adjust the
thresholdvalue to control sensitivity vs. specificity tradeoff - Modify feature selection criteria based on clinical priorities
- Enhance the CNN with transfer learning using pre-trained models
Future Improvements
- Implement ensemble methods combining metadata and image features
- Apply transfer learning with specialized dermatological model architectures
- Add explainability techniques to provide feature importance for individual predictions
- Integrate demographic risk factors for personalized risk assessment
Acknowledgments
- SLICE-3D dataset providers
- UCI Datathon 2025

Log in or sign up for Devpost to join the conversation.