About the Project
Inspiration
Modern knowledge workers are overwhelmed by scattered information. We constantly lose track of important documents buried in email threads, bookmarked tweets, Slack conversations, and uploaded files. Existing solutions only organize data—they don't understand your goals or proactively suggest what to do next. We envisioned an AI that doesn't just manage information but becomes your intelligent knowledge assistant, understanding what you're trying to achieve and helping you get there.
What it does
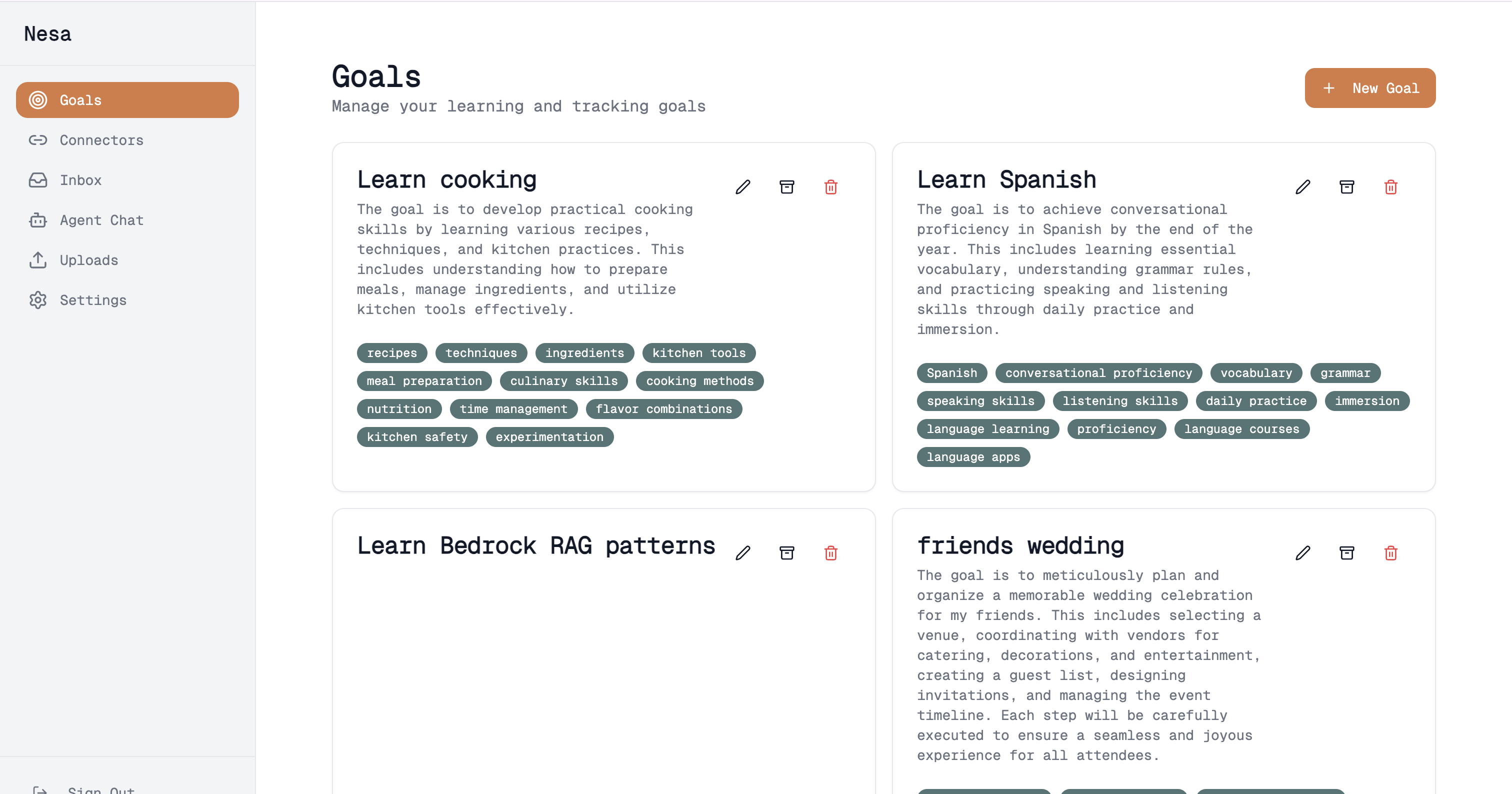
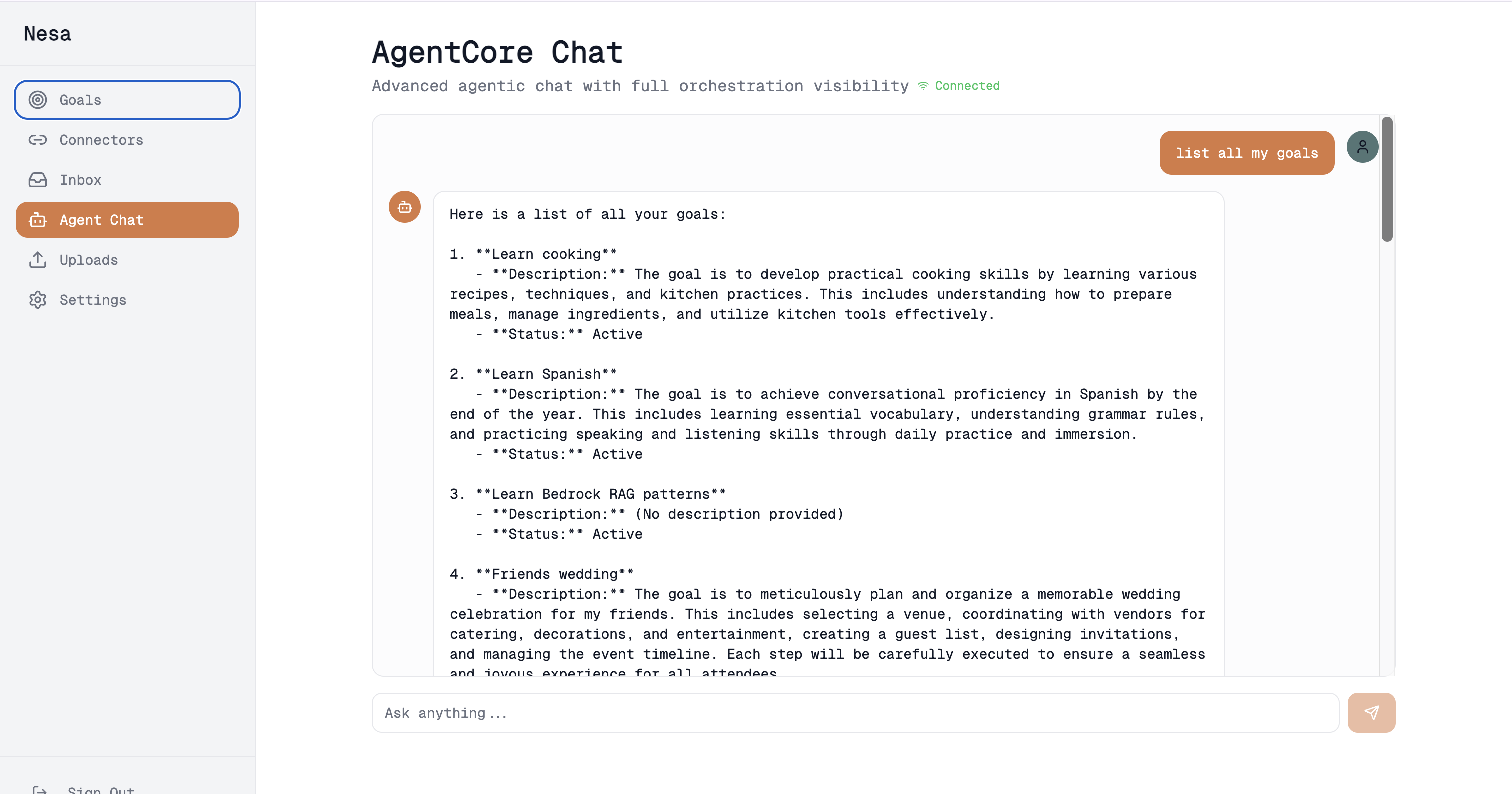
Meet Nesa creates a unified, goal-centric knowledge routing system. It automatically ingests content from multiple sources (email, Twitter bookmarks, Slack messages, file uploads), processes everything using AWS Bedrock , and intelligently routes information to your personal goals based on hybrid AI scoring (embeddings + keywords + entities + recency). The system proposes actionable tasks with full citations and source transparency, but crucially—everything requires human approval before taking external actions. Users can chat with their knowledge base in natural language, seeing exactly why the AI made each suggestion.
How we built it
We built on AWS serverless architecture using Bedrock AgentCore for fine-grained agent control, Dynamo DB Service for hybrid vector and BM25 search, and the Strands SDK for autonomous processing of complex documents.
Processing involves AWS Textract, Transcribe, and Rekognition for multi-modal content extraction, followed by intelligent chunking and embedding with Titan models. The frontend is React with real-time WebSocket streaming, showing users each step of the AI's reasoning process.
Challenges we ran into
The biggest challenge was balancing AI autonomy with human control—users want proactive help but not invasive automation. Creating effective goal relevance scoring required extensive tuning of our hybrid algorithm weighing semantic similarity, keyword matching, entity extraction, and recency factors.
We also struggled with real-time processing of large documents while maintaining responsive chat interactions, leading us to implement the Strands sub-agent architecture for complex document analysis.
Accomplishments that we're proud of
We successfully implemented Amazon Bedrock AgentCore primitives, giving us unprecedented control over agent behavior, tool execution, and memory management compared to classic Bedrock Agents. Our hybrid search combining vector embeddings with traditional keyword search significantly outperformed pure semantic search for personal knowledge retrieval. The approval-gate system maintains user agency while still providing intelligent automation. We built a scalable architecture that processes multi-modal content (text, images, audio) and routes it intelligently to user-defined goals.
What we learned
Human-AI collaboration works best with clear boundaries—AI should propose, humans should approve. Users need transparency into AI decision-making, so we invested heavily in showing each step of the agent's reasoning process. Pure vector search isn't enough for personal knowledge; adding keyword matching, entity recognition, and recency weighting dramatically improved relevance. The new AgentCore primitives provide much more flexibility than classic agents but require careful orchestration to avoid complexity. Most importantly, goal-centric organization resonates strongly with users compared to traditional folder-based systems.
What's next for Meet Nesa
We're planning multi-tenant deployment for enterprise customers, browser automation integration for richer workflows, enhanced citation UI with document previews, and daily digest dashboards. Future integrations include deeper Slack/Notion workflows, calendar scheduling, and collaborative team knowledge spaces. We're also exploring commercial licensing for the core routing algorithms and partnering with productivity tool vendors to integrate our goal-centric approach into existing workflows.
Technical Highlights
AWS Services Used
- Amazon Bedrock - Claude 3.5 Sonnet for reasoning, Titan Embeddings for semantic search
- Bedrock AgentCore - Fine-grained agent orchestration with custom tools
- Amazon OpenSearch Service - Hybrid vector + BM25 search
- AWS Lambda - Serverless processing functions
- Amazon S3 - Document storage and CDN
- Amazon DynamoDB - Metadata and user state
- Amazon SES - Inbound email processing
- AWS Textract/Transcribe/Rekognition - Multi-modal content extraction
- Amazon Cognito - Authentication with Google IdP
- AWS Amplify - Frontend hosting
Key Features
- Multi-Source Ingestion - Twitter, Slack, email, file uploads
- Goal-Centric Routing - Intelligent content-to-goal matching
- Human-in-the-Loop - All actions require approval
- Conversational Interface - Natural language chat with citations
- Hybrid Search - Vector + keyword + entity + recency scoring
- Strands Sub-Agent - Autonomous large document processing
- Real-time Streaming - WebSocket-based chat interface
Built with ❤️ using Amazon Bedrock, AgentCore, and the Strands SDK
Built With
- amazon-web-services
- aws-agentcore
- aws-amplify
- aws-bedrock
- aws-cognito
- aws-lamda
- aws-ses

Log in or sign up for Devpost to join the conversation.