-
-
MedStick
MedStick
Inspiration
Our team member Ahmed is from Yemen, where he's seen firsthand what poor infrastructure and unreliable internet mean for healthcare. The knowledge to save these lives exists, it's just locked behind a Wi-Fi signal that doesn't reach the people who need it most.
Every healthcare AI tool we looked at, ChatGPT, Med-PaLM, OpenEvidence, assumes a stable internet connection. In conflict zones, refugee camps, and rural clinics across Yemen, Sudan, and beyond, that assumption breaks down. So we built MedStick: a clinical AI that runs 100% offline.
What it does
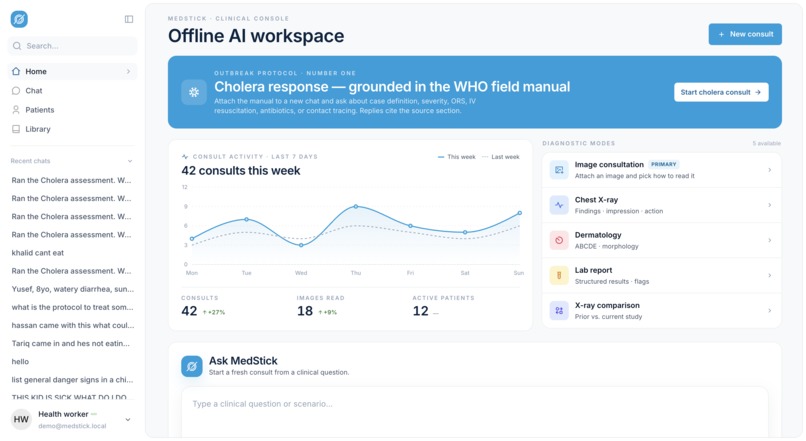
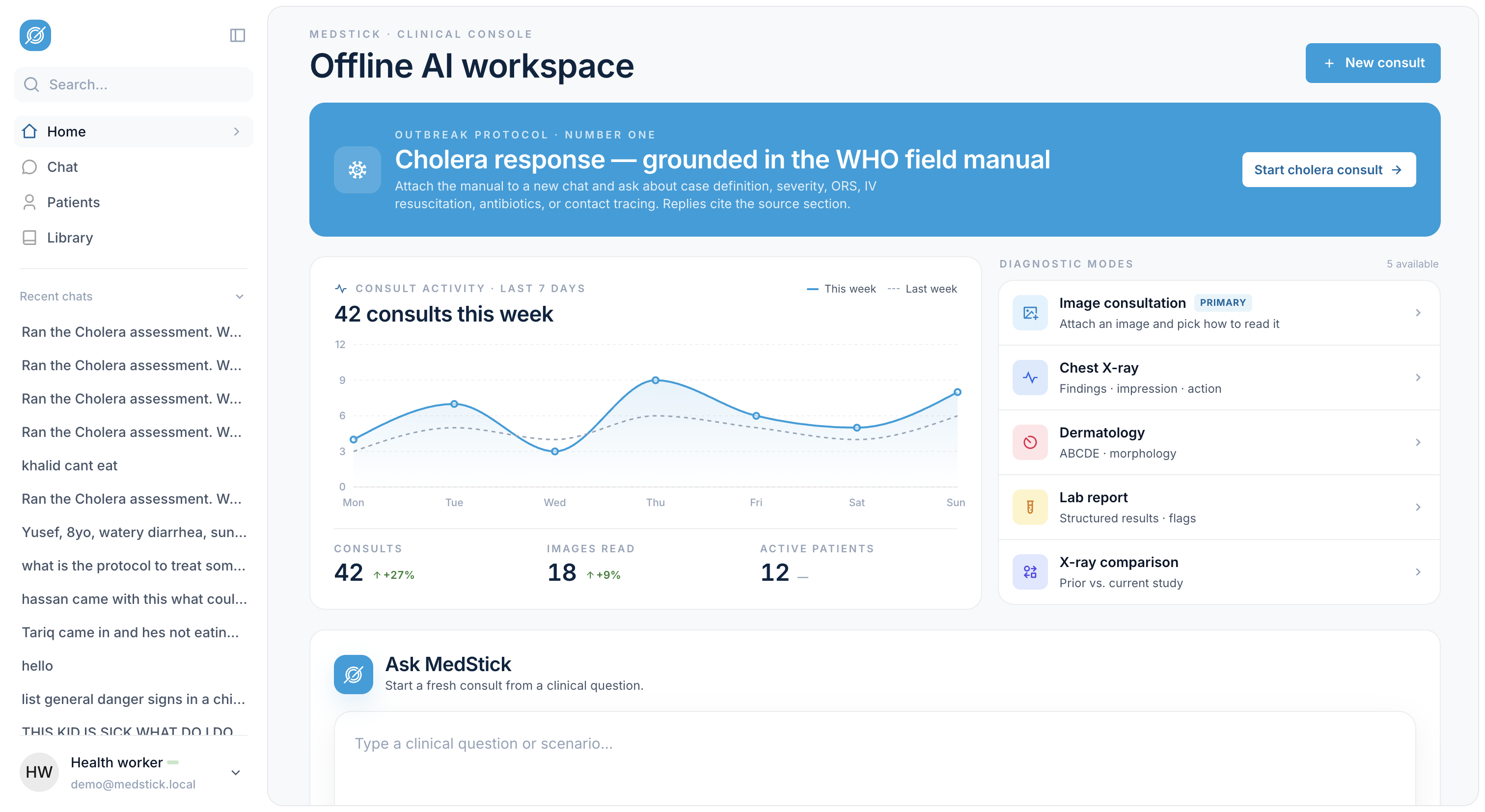
MedStick is an offline-first AI clinical workspace for frontline health workers. Everything below runs against a local vision-capable LLM, no internet, no cloud, no API keys.
Conversational clinical AI
Health workers talk to the AI in plain language about a patient. They describe symptoms, ask follow-ups, and get back structured answers, assessment, differential, plan, red flags, next steps, with red-flag warnings and recommended actions visually called out so a clinician can scan it in seconds.
Medical image interpretation
Snap or upload an image and pick a mode. The local vision model reads it on device:
- Chest X-ray — findings, impression, recommended action
- X-ray comparison — what changed between a prior and current study
- Dermatology — full ABCDE evaluation of a skin lesion plus morphology
- Lab report — extracts every test from a printed report into a structured table with high/low/normal flags and a one-line clinical summary
- Anatomy locator — describe in plain language where a queried feature is in any medical image
WHO-grounded outbreak response
For cholera (and more outbreaks coming), the AI's answers are grounded in the WHO Cholera Outbreak Response Field Manual that ships with the app. Inputs: patient weight + symptoms. Outputs: severity classification, IV/ORS rehydration plan, antibiotic guidance, and red-flag triggers, each citing the source section of the manual rather than hallucinating.
Patient records
Full patient management built around the AI:
- Create and edit patients (name, age, sex, language preference)
- Every chat is auto-saved per patient with the first message used as the title
- Every AI mode run auto-saves an encounter to the patient's file with the raw result and SOAP fields where applicable
- Per-patient photo gallery with thumbnails
- Click any past chat or encounter to open it back up exactly where it was left
- Bilingual English and Arabic with full right-to-left support
How we built it
- Frontend: Next.js 15 , Tailwind, Zustand, AlignUI components
- Backend: Express + SQLite , streaming SSE for token-by-token chat
- AI:
llama.cpprunning MedGemma-4B Q4 with the f16 vision projector - Grounding: Custom RAG pipeline over WHO PDFs, chunked by page with headings preserved, retrieved by keyword scoring, prepended into the system prompt
Challenges we ran into
- Context overflow. Our RAG pipeline kept blowing past the llama-server context window mid-demo. Cholera responses with 4 retrieved excerpts plus a 1,200-token reply were exceeding 4,096 tokens. We bumped the context to 8,192 and tuned chunk sizes.
- A nasty race condition where the first message in a new chat would silently disappear. Turned out the chat-load
useEffectwas racing the optimistic UI updates and wiping them. Fixed with ajustCreatedChatRefguard. - Service worker poisoning. An earlier prod build registered a
NetworkFirstcache for/api/*with a 24-hour TTL — newly created chats stayed invisible to the sidebar because the SW was returning stale data. We rebuilt the runtime caching rules to useNetworkOnlyfor the API and shipped a one-shot purge script. - Gemma's chat template rejects consecutive messages of the same role with a Jinja error. Required us to merge same-role messages and concatenate system prompts before forwarding to llama.
- Encounters were orphaned when no active patient was set at the moment a mode ran. Fixed by joining through
chats.patient_idso an encounter belongs to a patient via either direct link or shared chat.
Accomplishments that we're proud of
- A clinical AI that actually works with no internet, no cloud, no API key — and does so on a laptop you'd find in any clinic.
- WHO-grounded answers: every cholera response cites the field manual rather than hallucinating clinical advice.
- A structured output system that turns a paragraph of model text into Assessment / Impression / Red flags / Next steps callouts clinicians can scan it in seconds.
- Full English + Arabic with proper right-to-left text rendering, so it's usable by Arabic-speaking health workers without a language barrier.
- Bug fixes that mattered: chat history actually persists, encounters auto-save to the right patient, the sidebar shows what you'd expect.
What we learned
- Running LLMs locally is a tradeoff sandbox. Context size, KV-cache quantization, vision projector quality, prompt cache hits, every knob has a cost in RAM, latency, or output quality. We learned to instrument the system before tuning.
- RAG doesn't always need embeddings. For small corpora like a single WHO manual, keyword scoring with chunk + heading overlap is good enough and cuts our memory footprint by 1–2 GB.
- Service workers are easy to enable, hard to debug. A cache rule written once can silently corrupt your app for a 24-hour window across every browser that ever loaded the prod build.
- Designing for clinicians is different from designing for consumers. Information density matters. Visual hierarchy matters. "Red flags" needs to actually look red.
- Working with a chat template as strict as Gemma's taught us how much structural assumption goes into modern LLM serving.
What's next for MedStick
- More outbreaks: extend the WHO-grounded mode beyond cholera to measles, polio, malaria, and tuberculosis using the same ingestion pipeline.
- More languages: Pashto, Somali, French, Swahili — each language pack ships with the same WHO corpus.
- Building the platform to manage the different Medstick deployments and syncing the data using Claude
- Voice input for low-literacy users using Whisper running locally.
- Real semantic RAG with quantized embedding models, once we hit corpora large enough to need it.
- Field deployment in Yemen partnering with a local clinic to test MedStick with real health workers and gather feedback.
- A health-worker training mode that turns the AI into a teaching assistant: walk through WHO protocols interactively, quiz mode, certification prep.
- A printable encounter export so when a referral is needed, the AI's notes can travel with the patient on paper.
Built With
- express.js
- llama
- medgemma
- next.js
- sqlite



Log in or sign up for Devpost to join the conversation.