-
-
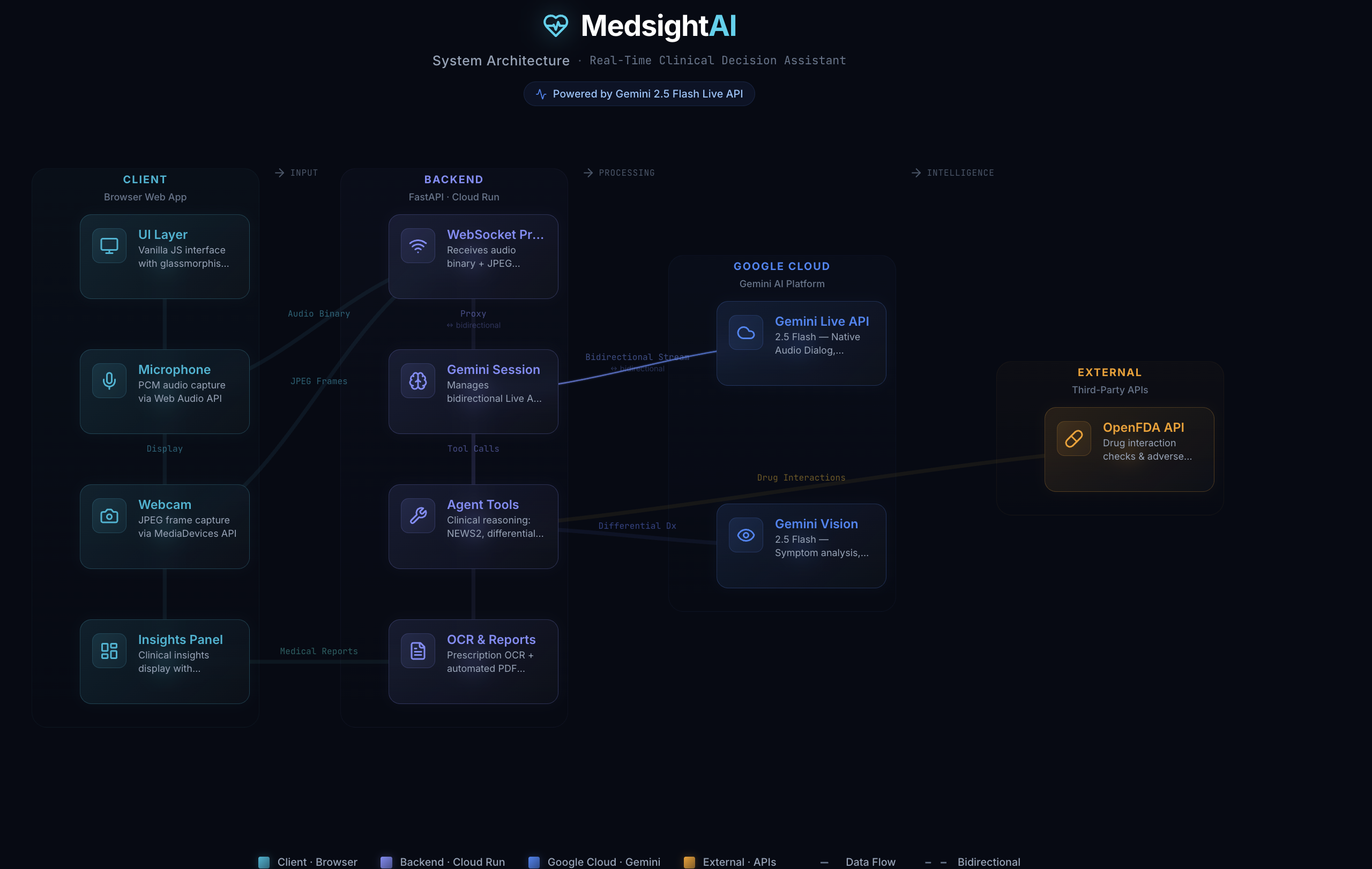
Architecture design
Inspiration
During hospital rounds, physicians are under immense time pressure. They must rapidly assess patient symptoms, recall complex drug interactions, reference clinical guidelines, and make critical decisions—often with limited immediate access to reference materials. Crucially, a doctor's hands are frequently sterilized, gloved, or busy examining the patient. Turning to a laptop or tablet to type into a traditional "chatbot text box" is simply not a viable workflow.
We realized that to truly help doctors at the point of care, we needed to break the "text box" paradigm entirely. We were inspired by the Gemini Live Agent Challenge to create a next-generation assistant that acts like a real colleague standing next to the doctor. We wanted an agent that could see the patient, hear the doctor's thoughts, speak clinical insights aloud, and be interrupted mid-sentence when the clinical context changes.
What it does
MedsightAI is a real-time clinical decision support assistant powered by the Gemini Live API. It acts as a true multimodal Live Agent designed for the hands-free clinical environment.
A doctor opens the web app and interacts naturally:
- 🗣️ Speaks to the AI assistant using natural voice.
- 📸 Shows symptoms (e.g., a rash, wound, or X-ray) through the live webcam feed.
- 🧠 AI analyzes both voice and image inputs simultaneously in real-time.
- 🔊 AI responds with spoken clinical insights, differential diagnoses, and safety checks.
- ⚡ Barge-in Support: If the AI suggests Amoxicillin, the doctor can interrupt mid-sentence with, "Wait, the patient is allergic to penicillin," and the AI will immediately halt and pivot its response to safe alternatives.
Beyond chatting, MedsightAI utilizes custom Agent Tools to access factual medical data. It integrates with the OpenFDA API to perform rigorous drug interaction checks, calculates NEWS2 risk assessments, and can even read handwritten medical prescriptions via Multimodal OCR.
How we built it
MedsightAI was built with a strict focus on low-latency, real-time multimodal interaction.
- The AI Brain: We utilized
gemini-2.5-flash-native-audio-latestas our core model, connecting to it via the Gemini Live API using the official Google GenAI Python SDK. For visual symptom analysis (Tool Calling), we routed specific snapshot frames to the standardgemini-2.5-flashmodel. - The Backend: We built a high-performance Python FastAPI application serving as a WebSocket proxy. It manages the bidirectional streaming of raw PCM audio and JPEG frames between the browser and Google's Live API.
- Google Cloud Hosting: To ensure scalability and meet hackathon requirements, the backend is containerized using Docker and deployed entirely on Google Cloud Run. We automated the CI/CD pipeline using Google Cloud Build and Artifact Registry via an infrastructure-as-code shell script.
- The Frontend: We opted for a lightweight Vanilla JS frontend to maximize performance. It uses the Web Audio API and MediaDevices API to capture microphone inputs and webcam streams.
Challenges we ran into
Building a true "Live Agent" is vastly different from building a turn-based chatbot:
- Bi-directional Audio Streaming: Managing the WebSocket connections and handling raw PCM audio conversions (ensuring the 24kHz, 16-bit LE format matched the browser's Web Audio API requirements) required significant debugging to eliminate audio artifacting.
- Vision + Audio Concurrency: Sending a live video feed while talking to an audio model without lagging the browser was tough. We solved this by using an offscreen canvas to capture video frames at 1 FPS to send to the backend, keeping the visible UI perfectly smooth.
- Connection Stability: WebSockets can drop. We had to build a robust auto-reconnect wrapper (
GeminiLiveSession) in Python that could transparently reconnect to the Gemini API without breaking the browser's connection or losing the ongoing clinical context.
Accomplishments that we're proud of
- Breaking the Text Box: We successfully built an interface where the user never has to touch a keyboard. The seamless fusion of sight, hearing, and speech feels like a massive leap forward in UX.
- Graceful Interruptions: Implementing the "barge-in" feature so the AI stops talking the millisecond the doctor interrupts it makes the tool feel incredibly natural and reliable for high-stakes environments.
- Agentic Architecture: We successfully bridged native audio conversations with external data by creating strict function-calling schemas that allow Gemini to securely query the OpenFDA API in real-time.
What we learned
- Native Audio vs. TTS: We learned that a native audio model is fundamentally different from a Text-to-Speech (TTS) pipeline. The latency is remarkably low, and the emotional tone matches the context of the conversation.
- Google GenAI SDK: We gained deep experience using the
LiveConnectConfigand defining strictly typedFunctionDeclarationtools within the new Python SDK. - Cloud Run for WebSockets: We learned how to properly configure Google Cloud Run to support long-lived WebSocket connections, adjusting timeout limits and concurrency settings to handle constant bidirectional streaming.
What's next for MedsightAI
For this hackathon, MedsightAI is a powerful demonstration of what is possible with the Gemini Live API. Moving forward, we envision:
- EHR Integration: Connecting the agent directly to Electronic Health Record (EHR) systems (like Epic or Cerner) via FHIR APIs, allowing the agent to pull patient history automatically before the doctor even speaks.
- Edge Deployment: Exploring ways to run smaller, quantized versions of these multimodal models locally on hospital devices to ensure absolute data privacy and zero-latency even during internet outages.
- Expanded Medical Vision: Fine-tuning the visual model specifically for complex radiology (MRI/CT scans) and dermatology edge-cases to improve the confidence scores of the visual differentials.
Built With
- css
- docker
- fastapi
- gemini
- gemini-2.5-flash
- gemini-live-api
- google-cloud
- google-genai-sdk
- html
- javascript
- mediadevices-api
- openfda-api
- python
- web-audio-api
- websockets


Log in or sign up for Devpost to join the conversation.