Inspiration
Have you ever wondered why so many get sent to the hospital each year? Maybe it’s injuries or accidents. However, most of the cases relate to patients’ failure of taking care of their own health. Such cases can come from patients’ inaccessibility to medical attention due to unjust insurance prices; patients’ having a hard time to finding specialized doctors; and more commonly, patients’ unawareness of their risk to become diagnosed with diseases.
Big Data is proliferating in the healthcare system, and overwhelming providers, patients, payers, and policymakers. With the advance of technology, we can make use of past data to create AI that can predict the future through Machine Learning, so users can be prepared early; analyze and visualize data for insurance companies to provide fairer means of insurance prices; finding the right, accessible doctors through doctor profile database and geolocation.
What we built
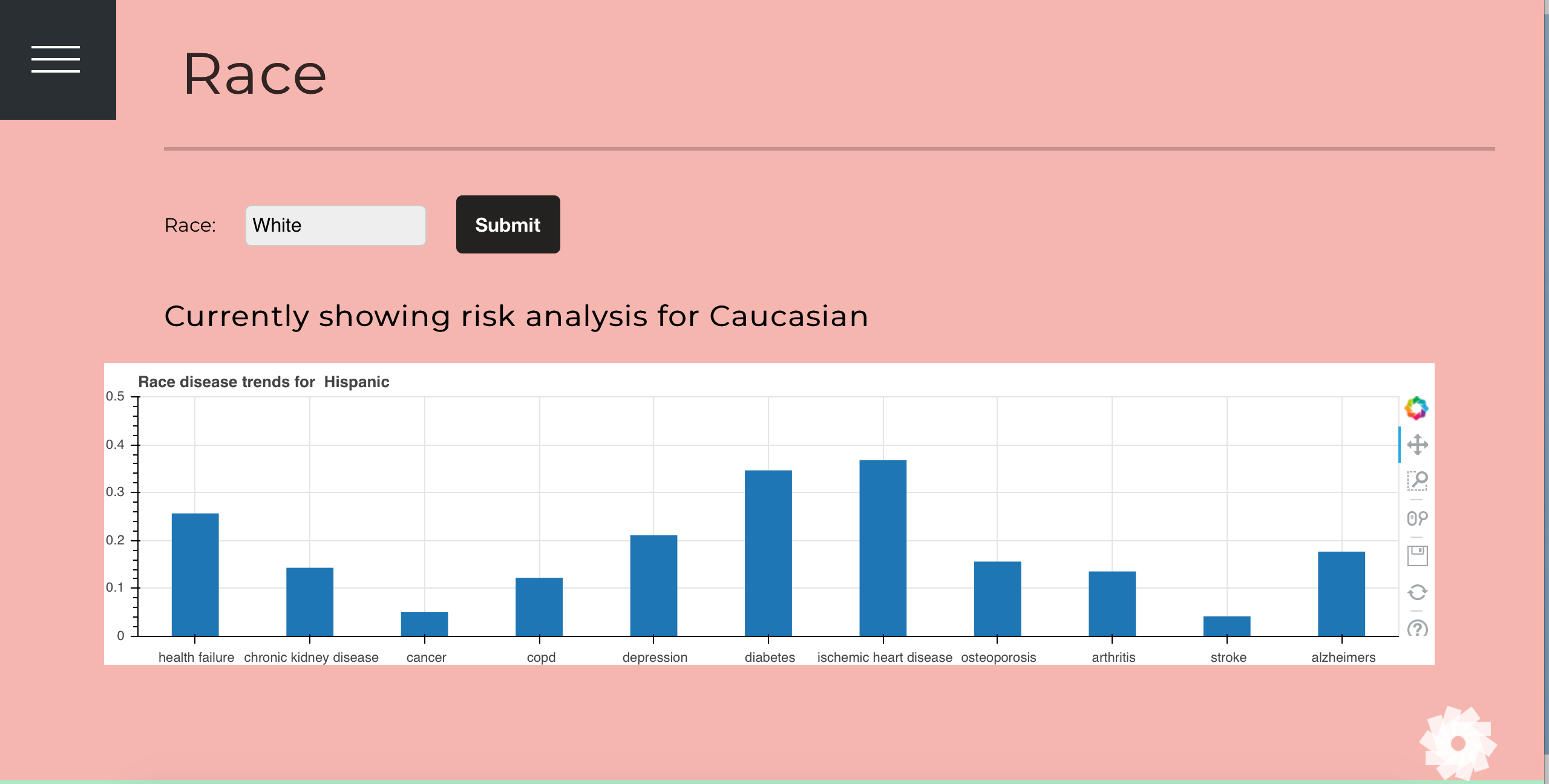
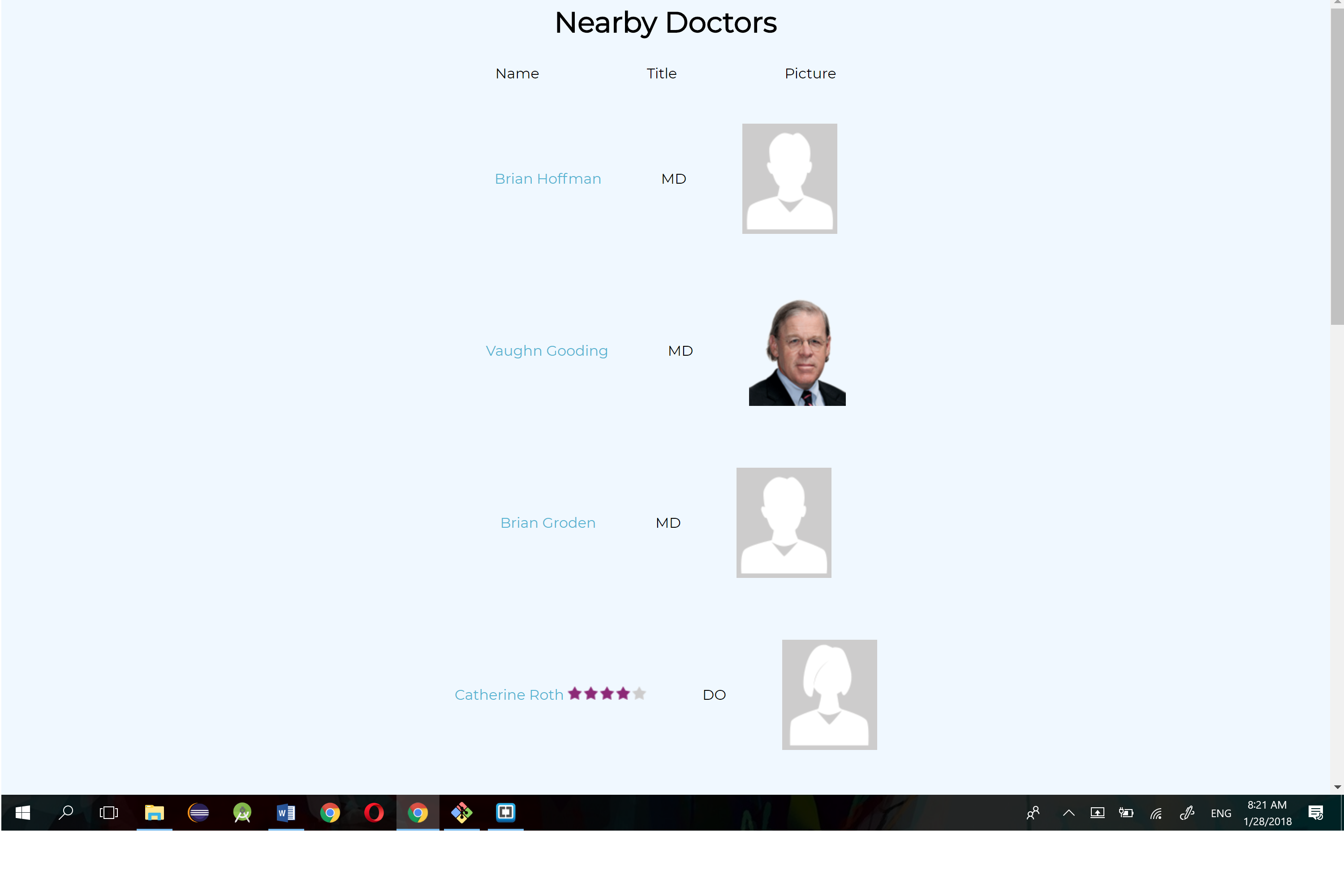
We created a webapp that features a machine learning model that assesses risks for Multiple conditions for each person of different demographics and historical conditions. We also analyzed the CMS database to create visualizations of risk assessments based on demographic parameters. We created a US heatmap visualization that differentiates risk assessment by color depthness based on geographical location. The idea is that these visualizations and analysis would allow clients (such as clinicians or insurance companies) to assess the risk of a patient before hand, given certain parameters available through the dataset. We also created visualizations for other parameters such as age group, ethnicity, and gender. Lastly, we created a tool that allows patients to search for doctors nearby, with access to the doctor’s detail information such as degree and specialization.
How we built it
We developed our tool using CMS dataset provided by IBM, which consists of historical medical claims in US with thousands of records. The tool itself is a web application developed using flask for the server side and backend code running HTML and CSS code for the front end. The tool consists of two parts: an analysis side and a predictive model. Using HighCharts, we created a US heatmap visualization that differentiates risk assessment by color depthness based on geographical location. It categorize risk assessment by conditions to provide easier-understanding information for insurance companies to determine risk. We also provide visualizations based on other categories such as race and gender. We used IBM’s dataset to create our prediction model and visualizations. We learned juypter to analyze IBM’s database, and extracted demographics parameters to create an interactive heatmap of disease trends in each state in US. We also used bokeh visualization library for python to create interactive graphs for other parameters such as ethnicity and gender. Using sklearn and the pandas library, we created a logistic regression model to predict the possible diagnosis of a user based on demographic parameters. We chose the logistic regression model to assess risks for multiple conditions by predicting the likelihood of a patient with a certain disease to contract other diseases. We did this by looking at features such as age, gender, race and county. We created a UI to take as input a new patient’s information and show how likely he/she is to contract diseases, given that the patient already has a specific disease. We created the heatmap visualization using a python visualization library HighCharts. We developed other visualization using Bokeh.
Challenges we ran into It took us some time to understand and learn the dataset and learn the software to manipulate the dataset. We also spent a long time experimenting various machine learning models to determine the best model to predict diagnosis trends. We had never worked with logistic regression model before, and implementing it was very challenging. Additionally, none of us had experience with Flask. Integrating backend and frontend code also took a long time. We also ran into many many problems importing the different libraries for visualizations and integration into the web tool.
Accomplishments that we are proud of
We are proud that we were finally able to integrate the linear regression model at 6AM and integrate everything right before the deadline. We are proud of our idea as it makes uses of the proliferating medical big data to provide a way that may improve the health insurance system and raise awareness of disease prevention among people of a large variety of demographics. We are also proud of learning two completely new softwares to analyze the very-complicated dataset and integrating everything.
What we learned
We learned a lot about ML, IBM’s dataset, flask, juypter, and the bokeh library. We researched a lot of machine learning models for the one that best fit our purpose and is possible to learn and implement over a short period. It was the first time for all of us to work with such large database, and learning to analyze it certainly improved various skills. We learned flask from scratch to create a website that combines HTML and CSS front end with python backend.
What's next for MedRisk
We can further implement machine learning models to predict diagnoses based on more relatable factors such as symptoms, eating habit, and genetics. With a more accurate model on diagnoses, we can find doctors better suited for the patient, and provide insurance companies with more predication data so they can make better decisions.
Built With
- api
- bokeh
- bootstrap
- css3
- flask
- highcharts
- html
- javascript
- pandas
- python
- sklearn






Log in or sign up for Devpost to join the conversation.