-
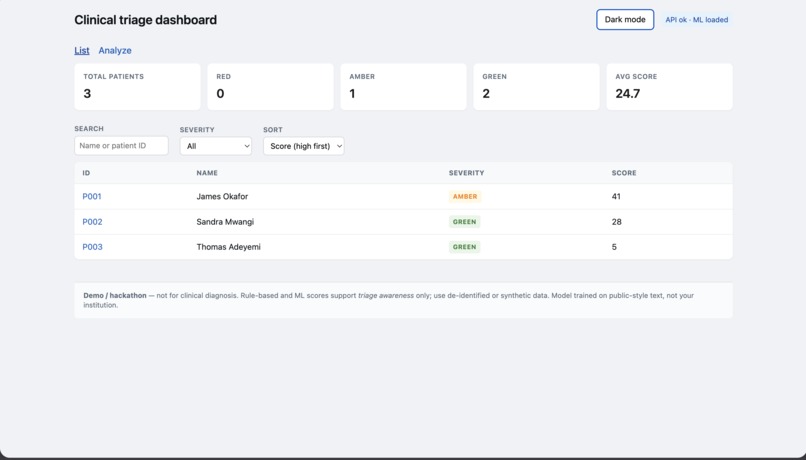
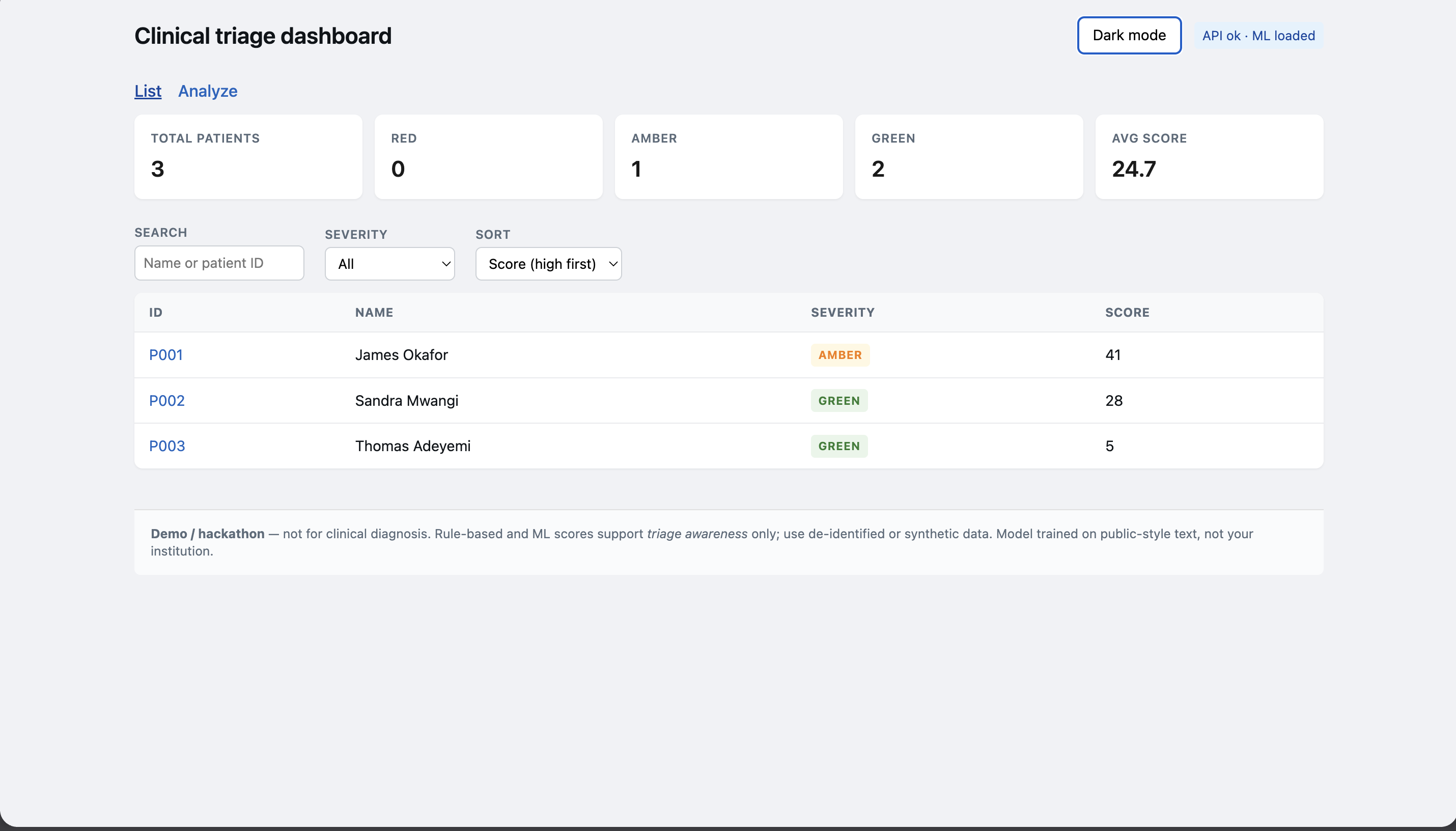
Doctor's dashboard
Inspiration
Healthcare workers spend critical minutes piecing together patient information scattered across notes, labs, and medication records — and patients deteriorate in the gaps. We built MedRank because the handover moment, when a doctor arrives for a shift and needs to rapidly assess 20 patients, is where information overload costs lives.
What it does
MedRank ingests raw patient data — clinical notes, vitals trends, lab results, and medication records — and runs it through a multi-agent pipeline that analyzes each dimension in parallel. A vitals agent detects deterioration patterns, a labs agent flags critical values, a medication agent catches dangerous interactions, and a history agent classifies risk from clinical notes. An orchestrator agent synthesizes all four outputs into a composite risk score and generates a structured clinical brief. The result is a real-time ward dashboard where every patient is ranked by severity, with full breakdowns of what is wrong, what has been administered, and what needs to happen next.
How we built it
We trained a RandomForest classifier on 5,000 real de-identified clinical transcriptions from the MTSamples dataset, using TF-IDF vectorization to learn which note patterns predict high-risk presentations. The backend is a Python Flask API with five agents — vitals, labs, medications, history, and a summary composer — dispatched in parallel via ThreadPoolExecutor and managed by an orchestrator. The frontend is React with Recharts for live vitals charts and a dark clinical dashboard designed to surface critical information in seconds.
Challenges we ran into
Splitting the intelligence across agents that each produce a score and then meaningfully composing those scores into a single ranked output required careful weighting — getting the composite score to reflect real clinical priority rather than just arithmetic averaging took several iterations. Ensuring the ML classifier generalized across MTSamples specialties with unbalanced class distribution was also non-trivial within the time constraints.
Accomplishments that we're proud of
We trained a model on real clinical data and deployed it as a live component of a working system within 90 minutes. The multi-agent architecture genuinely runs in parallel, the dashboard updates in real time, and the medication interaction detection catches contraindications that could directly harm patients — all built from scratch with no pre-existing boilerplate.
What we learned
Clinical AI is less about model complexity and more about data pipeline design. The most impactful parts of MedRank are not the ML model itself but the structured agent outputs, the weighted risk composition, and the clarity of the final brief. We also learned that agentic systems need careful orchestration — running agents in parallel is straightforward, but merging their outputs into something clinically meaningful requires domain thinking, not just engineering.
What's next for MedRank: AI-Powered Patient Priority Intelligence
Direct EHR integration so patient data flows in automatically rather than via manual input. A deterioration alert system that pushes notifications when a patient's score crosses a threshold mid-shift. Expansion of the training dataset to MIMIC-IV for richer vital sign and lab trend modeling. And a mobile view so nurses can check the priority ranking from anywhere on the ward.

Log in or sign up for Devpost to join the conversation.