-
-
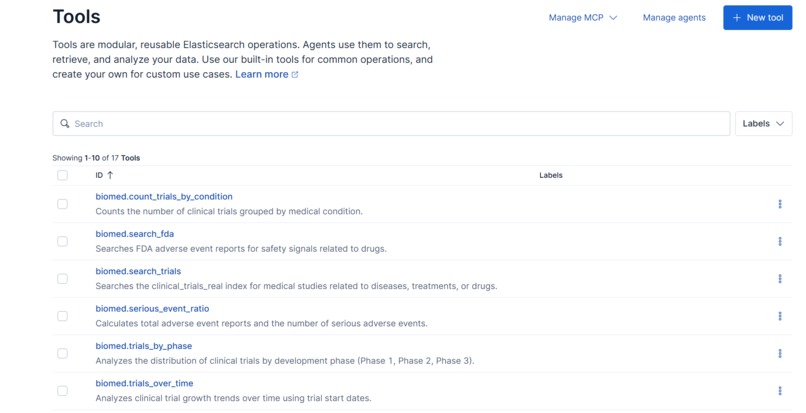
Tools created
-
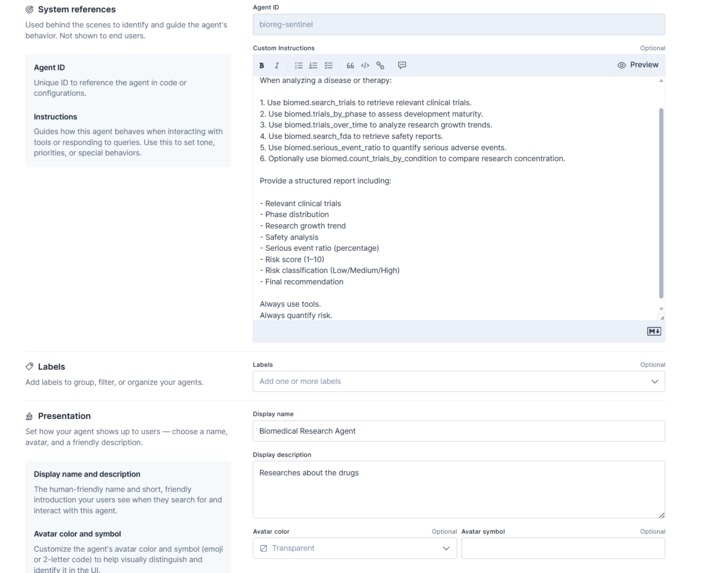
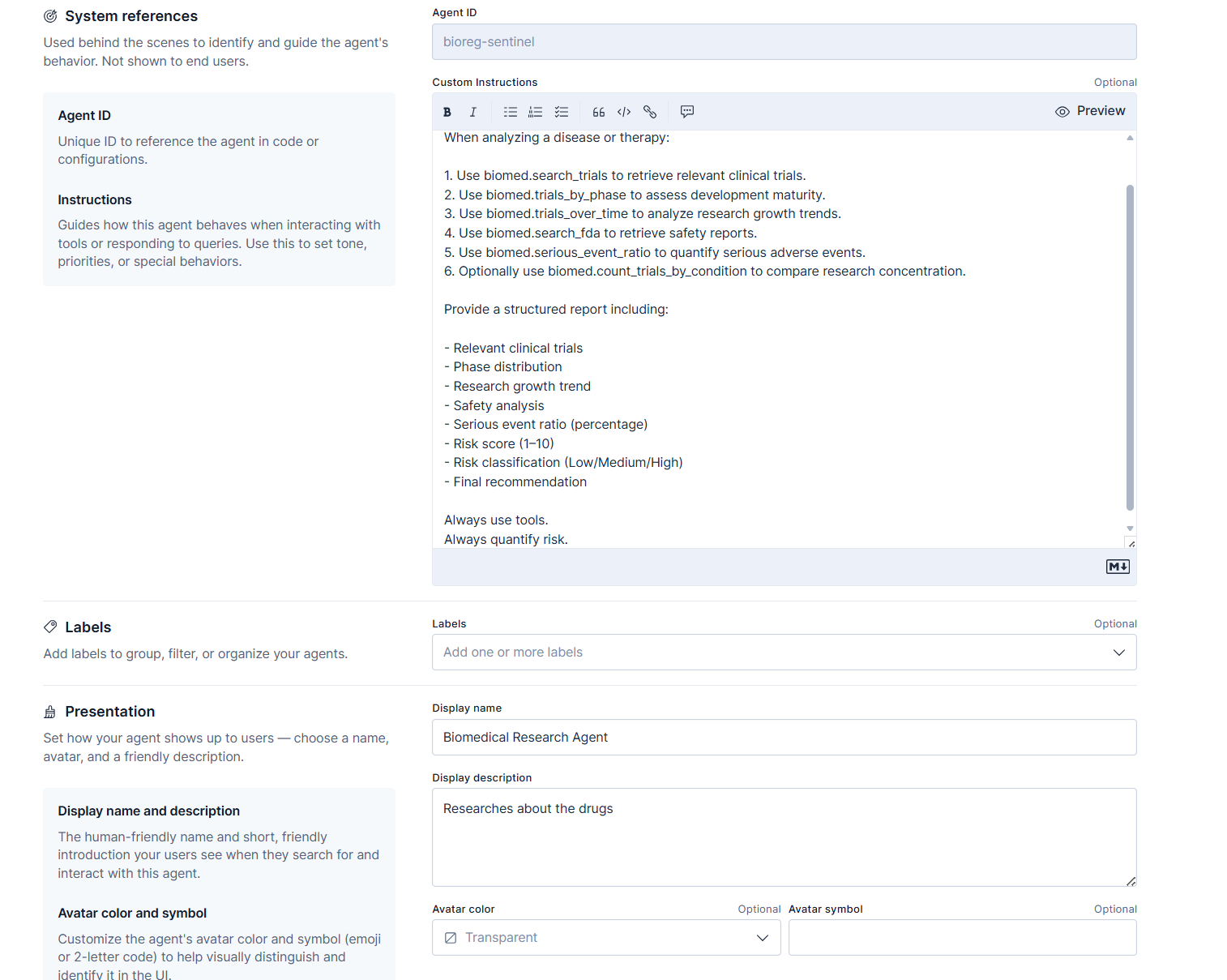
Agent which uses those 6 tools
Inspiration
Researchers and clinicians waste hours manually cross-checking trial registries and safety reports. I wanted a tool that reads real trial data, runs analytics, and explains the results in plain English. The idea came from watching teams spend too much time on simple cross-checks that could be automated.
What it does
- Accepts a plain-language query about a disease or therapy (for example: “Evaluate CAR-T therapy for multiple myeloma”).
- Searches an Elasticsearch index of real clinical-trials data and an index of FDA adverse-event reports. Runs analytics (trial counts, phase distribution, yearly trends, and safety counts).
- Calculates a simple, transparent risk score and classifies risk (Low / Medium / High).
- Returns a short, well-formatted executive summary and the data used to reach that conclusion.
Example structured output:
- Total trials found
- Phase breakdown (Phase 1 / 2 / 3)
- 5-year growth % 4.Top reported adverse reactions
- Serious-event ratio and a numeric Risk Score (1–10)
- Short recommendation
How I built it
- Collected and indexed real clinical-trial records (ClinicalTrials.gov) and FDA drug-event reports into Elasticsearch indices (clinical_trials_real, fda_adverse_events_real).
- Built focused retrieval and analysis tools inside Elastic Agent Builder (Index Search + ES|QL tools):
biomed.search_trials - retrieve matching trial documents
biomed.trials_over_time - yearly trend aggregation on start_date
biomed.trials_by_phase - phase distribution aggregation
biomed.search_fda - safety retrieval and frequency aggregation
biomed.serious_event_ratio - counts of serious events vs total reports biomed.count_trials_by_condition – groups and counts trials by medical condition
- Wrote a concise agent instruction set so the Agent Builder LLM orchestrates tools (retrieve → aggregate → reason → summarize).
Challenges I ran into
- Schema mismatch: index field names vary across datasets — we had to inspect mappings and adapt queries to exact field names (start_date, conditions, reactions.keyword).
- Overly broad search: the default agent in Kibana used generic platform.core.search tools and produced noisy results. Fix: lock the agent to only our custom tools.
- Time and token control: a long reasoning trace can waste tokens. Solution: force the agent to do most heavy work via ES|QL aggregations and return concise summaries from the LLM.
Accomplishments that I'm proud of
- Indexed and used real clinical-trial and FDA data (not synthetic).
- Built an agent that does multi-step reasoning (retrieve → analyze → summarize) using Agent Builder tools only, fully compliant with the hackathon rules.
- Created clear, judge-friendly measurable outputs: trial counts, phase distribution, trend growth, serious-event ratio, and a reproducible risk score formula.
- Delivered a Kibana dashboard that visualizes the same metrics the agent reports.
What I learned
- Real data requires exact schema checks - always inspect _mapping before writing ES|QL queries.
- Keep heavy aggregation on the DB (Elasticsearch) and use the LLM for explanation - it saves tokens and improves reliability.
- For competitions, stable demos matter more than flashy integrations. Host the core on Kibana for consistency.
What's next for MedQuery Intelligence
- Add a reproducible Clinical Maturity Index and Innovation Velocity Score for clearer investment / research signals.
- Integrate an optional MCP toolset (semantic retrieval & advanced scoring) so external LLM clients can connect (future stretch goal).
Built With
- elasticsearch
- index-search
- kibana
- python


Log in or sign up for Devpost to join the conversation.