-
-
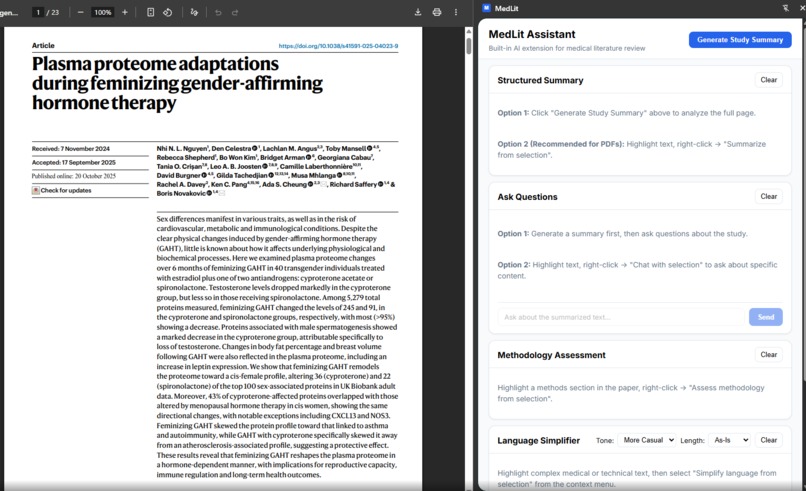
Side panel showcase
-
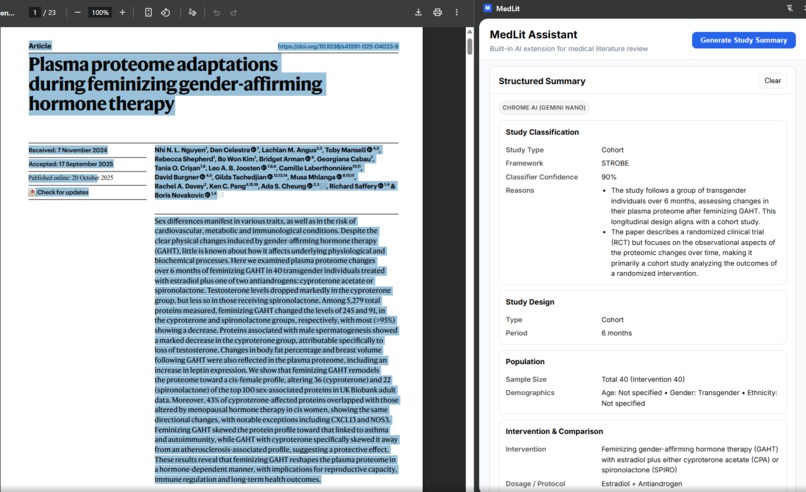
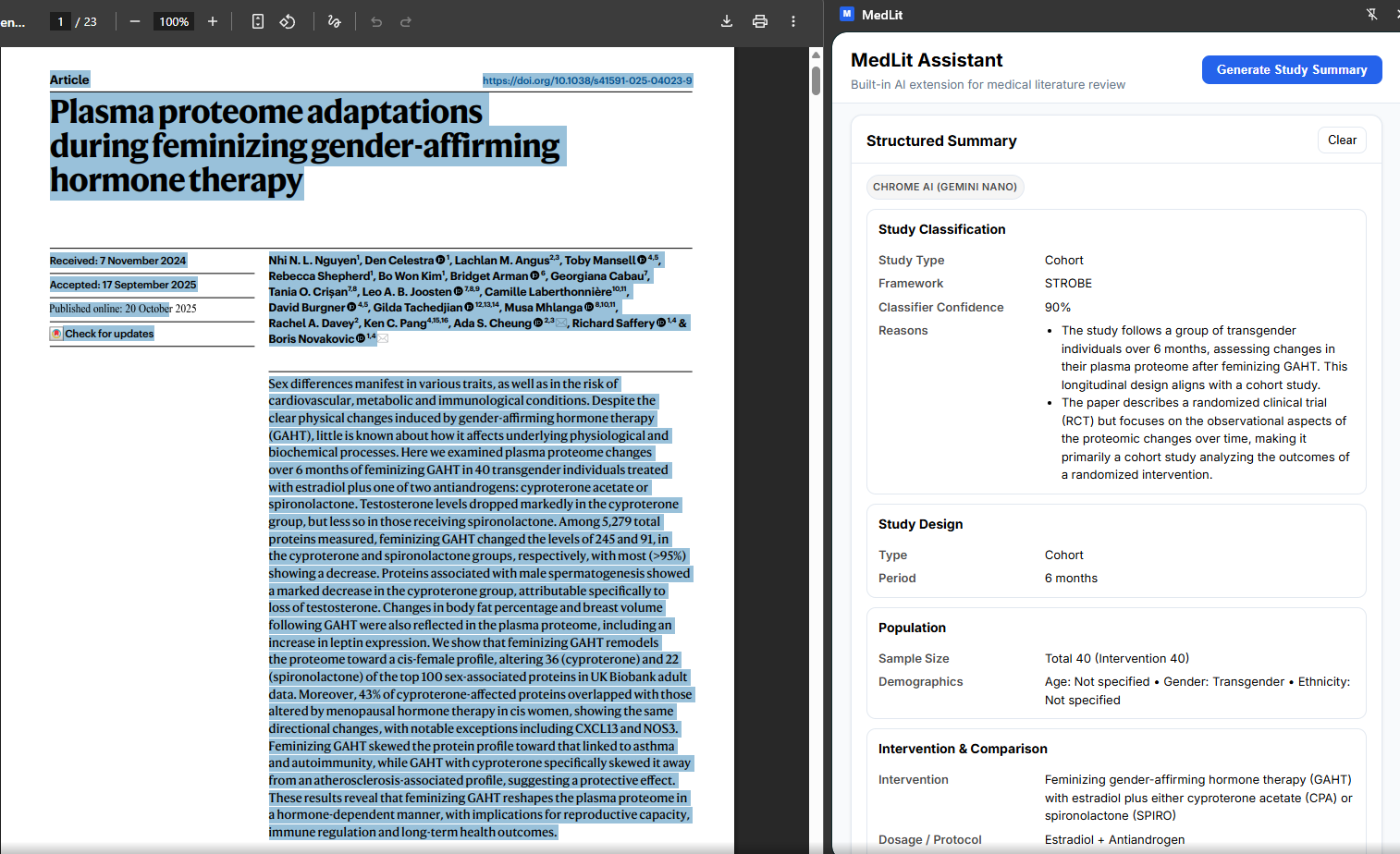
Summarization feature of a pdf article
-
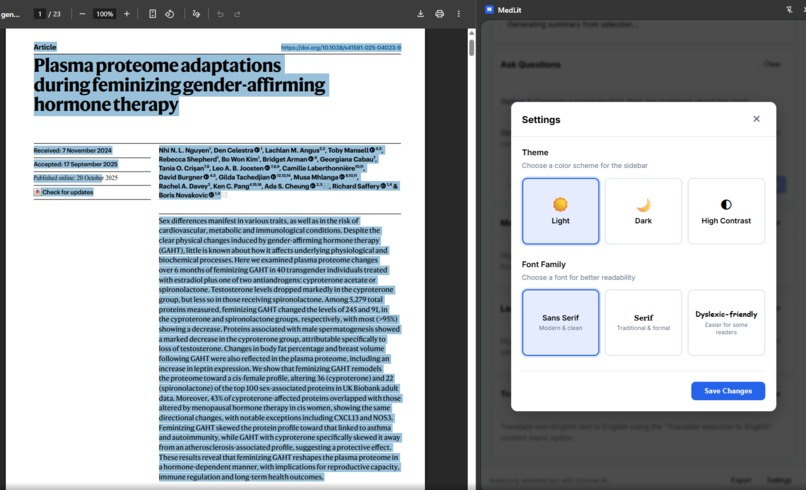
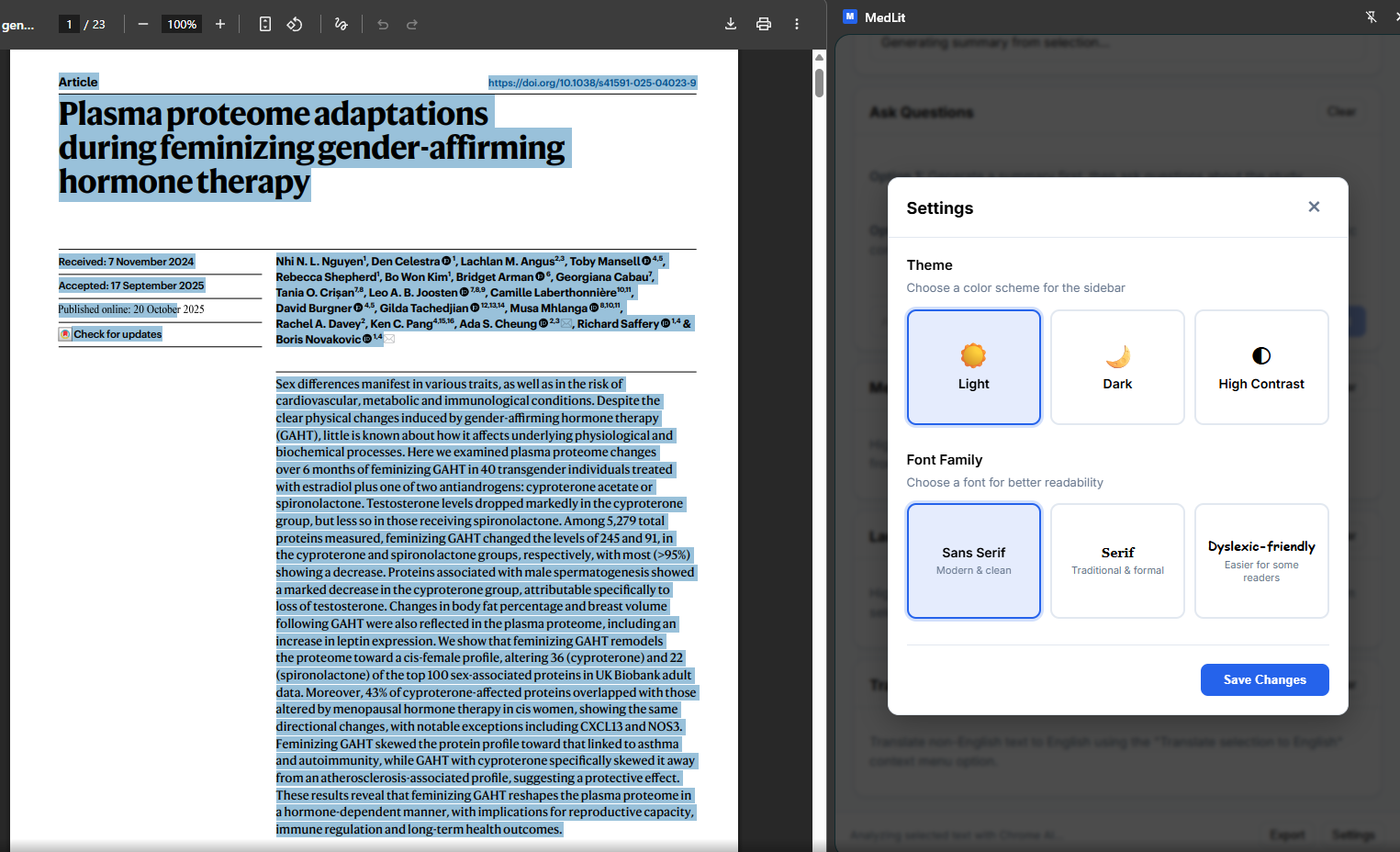
User interface customization settings for accessibility
-

Chat interface feature

Inspiration
Medical professionals, students, and researchers face a common frustration: spending hours manually extracting study design elements from research papers and assessing research quality. Existing AI solutions create additional friction—they require navigating to separate chatbot interfaces and uploading potentially sensitive medical documents to cloud services, raising privacy concerns for patient data and proprietary research.
I developed MedLit to solve this problem by bringing AI directly into the browser where medical literature lives. By leveraging Chrome's built-in AI capabilities, I created a privacy-preserving, framework-aware assistant that eliminates the context-switching and data exposure of traditional tools. As a plus, it is also available offline!
What it does
MedLit is a Chrome extension that transforms medical literature review through intelligent, on-device AI processing:
Structured Study Extraction: Automatically detects study types (RCTs, cohort studies, systematic reviews, etc.) and extracts key elements using appropriate medical research frameworks (CONSORT, PRISMA, STROBE, STARD, CARE, COREQ). It identifies PICO elements, study demographics, interventions, and outcomes.
Methodology Quality Assessment: Evaluates research quality using the Cochrane Risk of Bias framework across five dimensions, providing 0-100 quality scores with confidence-based adjustments and anti-pattern detection to prevent unreliable assessments.
Medical Language Simplification: Translates complex medical terminology into accessible language with three customizable tone levels (casual/neutral/formal) and length options (concise/as-is/detailed), while extracting and defining key terms.
Multilingual Translation: Converts highlighted texts to English while preserving medical terminology accuracy, with support for multiple language pairs.
Context-Aware Chat: Provides an interactive Q&A interface based on extracted summaries or selected text, with markdown-rendered responses and conversation history.
Theme Options: Choose from Light, Dark, or High Contrast themes to match your preference or reduce eye strain during long literature review sessions.
Dyslexia-Friendly Fonts: Select from multiple font families including a specialized dyslexic-friendly option designed to improve readability for users with dyslexia.
Adjustable Typography: Fine-tune character size and letter spacing with intuitive sliders. These accessibility features help users with visual processing differences or low vision customize the reading experience to their needs.
Flexible Export Formats: Export study summaries and methodology assessments in multiple formats (JSON, Markdown) for integration with reference managers or systematic review tools.
How we built it
MedLit integrates three Chrome Built-in AI APIs into a cohesive codebase:
Prompt API: Powers structured extraction with framework-specific templates and medical research classification logic. We engineered a decision tree with anti-hallucination rules to ensure accurate study type detection.
Rewriter API: Simplifies technical language with medical domain-specific context, using configurable tone and length parameters.
Translator API: Handles multilingual abstracts with automatic fallback to the Prompt API for broader language compatibility.
Architecture: Built with ES6 modules and Manifest V3, featuring a modular structure with dedicated AI client logic, comprehensive prompt templates, content validators, and robust fallback systems. The side panel UI provides intuitive access to all features.
UX Design: Integrated context menu shortcuts for text selection-based operations, side panel summaries for full-page analysis, accessibility features (dyslexia-friendly fonts, adjustable character sizing), and export capabilities for summaries and assessments in Markdown/JSON formats.
Challenges we ran into
Framework-Aware Classification: Creating accurate study type detection without hallucination required building a sophisticated decision tree with validation rules. We had to balance sensitivity (catching edge cases) with specificity (avoiding false classifications).
Confidence-Based Quality Scoring: Methodology assessment needed pre-validation to prevent inflated ratings on low-quality or irrelevant content. We implemented a 60% confidence threshold and developed anti-pattern detection to ensure garbage-in doesn't produce garbage-out.
Token Limit Management: Gemini Nano has context limits (~4000 characters) that could truncate important medical information. We engineered smart field filtering, user warnings for large contexts, and chat history management (last 3 Q&A pairs) to work within constraints.
PDF Text Extraction: Chrome's PDF viewer has limited extraction capabilities. We optimized for context menu usage on selected text rather than relying solely on full-page extraction.
Privacy-First Architecture: Maintaining complete on-device processing while delivering sophisticated analysis required careful prompt engineering and efficient use of limited model capabilities—no shortcuts to external APIs.
Accomplishments that we're proud of
True Privacy Preservation: Every single AI operation happens on-device. I developed an useful tool that medical professionals can trust with sensitive research without any data leaving their browser.
Medical Framework Integration: Supporting six major research frameworks (CONSORT, PRISMA, STROBE, STARD, CARE, COREQ) with automatic study type detection demonstrates deep understanding of medical literature standards.
Comprehensive Error Resilience: There is a multi-layer fallback system that ensures the extension works reliably even when certain APIs are unavailable.
Accessibility Focus: Dyslexia-friendly fonts, adjustable character sizing and spacing, theme options, and flexible export formats make MedLit inclusive for diverse users.
Zero External Dependencies: Built exclusively with Chrome's built-in AI APIs—no external API calls, no build process, just clean ES6 modules that work offline after initial model download.
What we learned
On-Device AI Has Real Constraints: Working within token limits and model capabilities forced me to be creative with prompt engineering and validation strategies. This taught me to build intelligent pre-processing and post-validation layers.
Medical Domain Requires Deep Context: Generic AI prompts don't work for medical literature. I have learned to embed framework knowledge, terminology awareness, and quality assessment standards directly into our prompts.
Fallback Architecture is Critical: Browser AI APIs are experimental. Building robust fallbacks isn't just good practice—it's essential for real-world deployment.
Privacy Sells Itself: The "everything on-device" architecture resonates strongly with my target users (which also includes me :P). In healthcare, privacy isn't a feature—it's a requirement.
User Context Matters: I learned that researchers interact with literature in different ways (full papers vs. selected sections), which drove my dual-mode design (side panel + context menu).
What's next for MedLit
Enhanced Export Options: PDF and CSV export formats for compatibility with reference managers and systematic review tools.
Extended Framework Support: Adding more specialized frameworks (ARRIVE for animal studies, CHEERS for economic evaluations) and custom template creation.
Citation Network Analysis: Extracting and visualizing citation relationships between papers for literature mapping.
Advanced Methodology Features: Statistical power calculation validation, p-hacking detection, and reproducibility assessment tools.


Log in or sign up for Devpost to join the conversation.