-
-
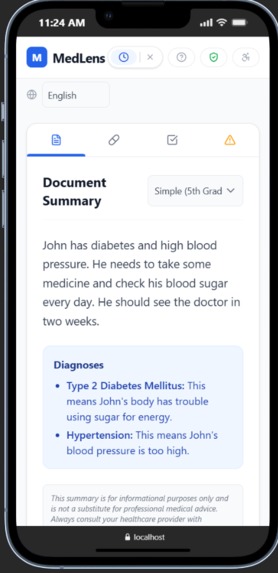
Display of results on a mobile device.
-
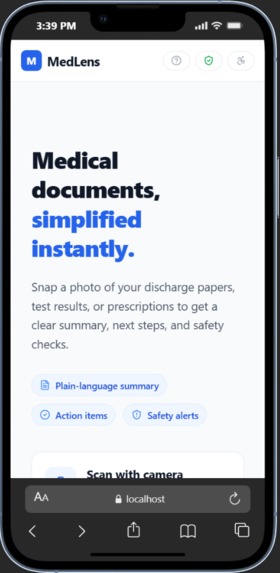
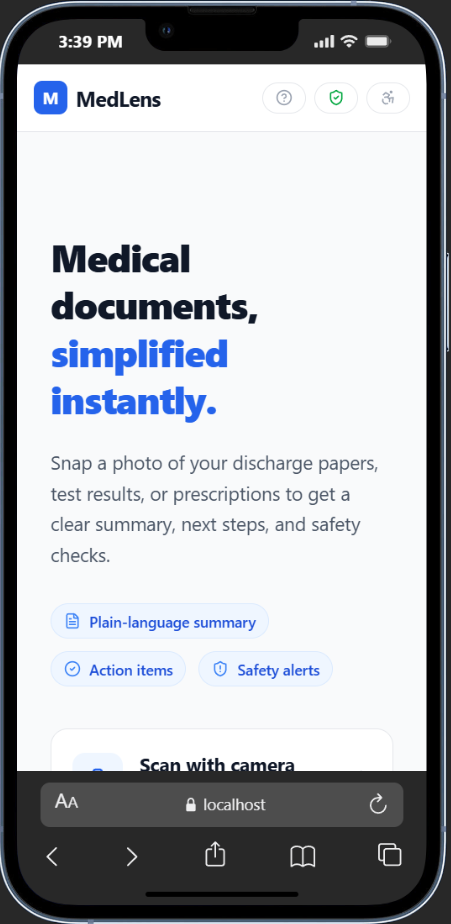
Landing Page
-
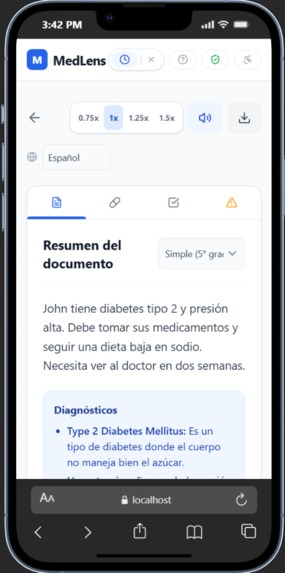
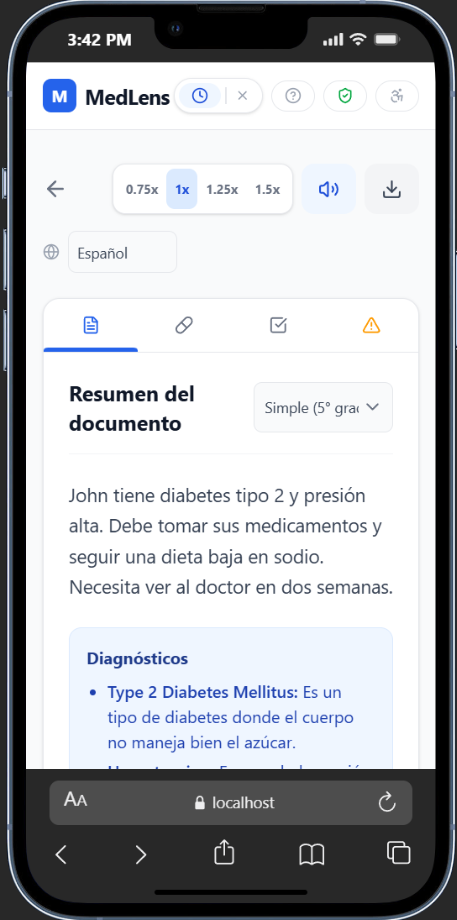
Results (translated)
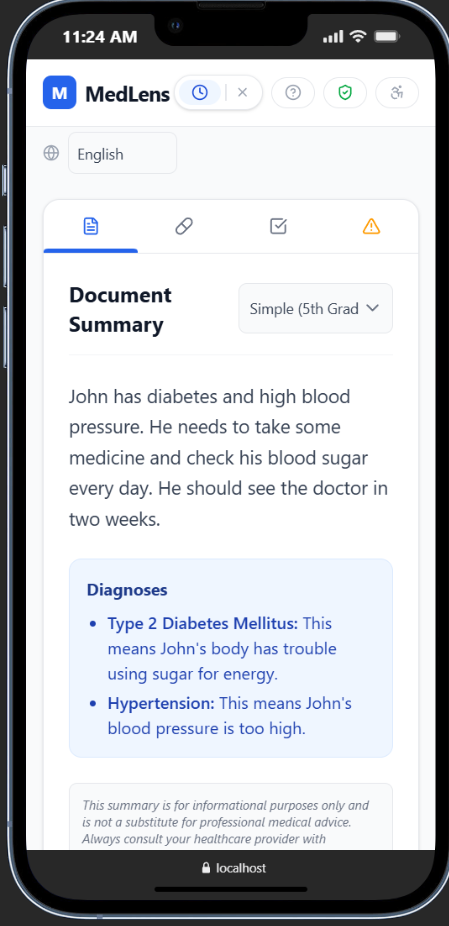
Inspiration
36% of U.S. adults have limited health literacy. In D.C.'s Wards 7 and 8, patients face the highest chronic disease rates in the city and the lowest access to digital health resources. When patients can't understand their discharge papers, they miss medications, skip follow-ups, and end up back in the ER — costing the U.S. healthcare system $528 billion annually in medication non-adherence alone. We built MedLens to bridge this gap.
What it does
MedLens transforms complex medical documents into plain-language summaries that anyone can understand. Patients can photograph a document, upload a file, paste text, or speak it aloud — and in seconds receive:
- A plain-language summary at 3 reading levels (5th, 8th, and 12th grade) with instant toggling
- Full translation into 6 languages (English, Spanish, French, Chinese, Korean, Vietnamese) — including all UI headings
- A daily medication schedule organized by morning, afternoon, evening, and bedtime
- Drug interaction alerts powered by FDA data, summarized into plain language by AI
- Text-to-speech so patients with low literacy or visual impairments can hear their results
- PDF export for offline access
How we built it
Frontend: React 19 + Tailwind CSS v4 with Framer Motion animations, mobile-first responsive design, and full accessibility (ARIA labels, 48px tap targets, focus rings).
AI Pipeline: GPT-4o-mini processes medical text through a structured prompt that extracts medications, diagnoses, action items, dates, and warnings while generating all 3 reading levels in a single API call. Tesseract.js v5 handles OCR entirely client-side for privacy. A confidence scoring system (0-100%) warns users when scans are unclear.
Drug Safety: Each extracted medication is queried against the OpenFDA drug label API. The raw FDA interaction text — often paragraphs of dense clinical language — is then summarized by a second LLM call into 1-2 plain-language sentences specific to the patient's medication list.
Voice I/O: The Web Speech API provides both speech-to-text (voice input) and text-to-speech (read aloud), with zero external dependencies.
Backend: FastAPI with MongoDB caching for drug interactions, async request handling, and ElevenLabs TTS integration for high-quality voice synthesis.
State Management: React Context shares document input and analysis results across all pages, enabling a clean data flow from input to processing to results.
Challenges we ran into
Summary shape mismatch: The frontend expected the summary as an object with 3 reading levels, but the AI pipeline initially returned a single string. We redesigned the prompt to generate all 3 levels simultaneously, making reading level switching instant with zero additional API calls.
Raw FDA text was unreadable: Drug interaction data from OpenFDA is dense clinical text that gets truncated and is useless to patients. We added a second LLM layer to summarize each interaction into plain language filtered for the patient's specific medications.
Translating the full UI: Switching languages initially only translated the AI-generated content — headings like "Summary," "Action Items," and "Morning" stayed in English. We built a client-side translations object covering all 6 languages so the entire interface translates seamlessly.
Integration across 4 team members: With separate frontend, backend, and AI pipeline development happening simultaneously, keeping the data contract aligned required constant communication and a shared JSON schema.
Accomplishments that we're proud of
- End-to-end working product with 5 input methods, 3 reading levels, 6 languages, medication scheduling, and drug safety checks — built in 24 hours
- AI-summarized drug interactions that turn incomprehensible FDA text into actionable patient warnings
- Full accessibility: voice input, text-to-speech, large tap targets, ARIA labels, OCR confidence transparency
- Privacy-first architecture: OCR runs client-side, no patient data is stored
What we learned
- Prompt engineering for structured medical output requires explicit JSON schema instructions and handling edge cases like non-medical documents
- Health literacy is a design problem, not just a translation problem — reading level, language, and modality all matter
- The gap between "AI can extract data" and "a patient can act on it" is where the real engineering happens
- Hackathon integration is harder than individual features — the data contract between components is everything
What's next for MedLens
- ElevenLabs TTS integration for natural-sounding multilingual voice output
- PWA deployment so patients can install MedLens on their phones
- Patient portal API connections (Epic MyChart, Cerner) for direct document import
- Expanded language support targeting D.C.'s Amharic and Tigrinya-speaking communities
- Caregiver sharing — text a simplified summary card to a family member
- Clinical validation with healthcare providers at Howard University Hospital

Log in or sign up for Devpost to join the conversation.