
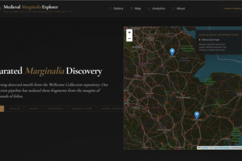

Inspiration
I've always been fascinated by how weird medieval art can get. I'm talking specifically about the stuff in the margins. You have rabbits hunting hunters, dragons with human faces, and just general chaos that has nothing to do with the religious text next to it. The problem is, there are millions of digitized pages out there (British Library, etc.), but unless you know exactly which page of which book to look at, this art is basically lost. I wanted to build something that unearths these hidden gems automatically so anyone can explore them.
What it does
Medieval Marginalia Explorer is a web app where you can discover these marginal illustrations.
-Automated Discovery: I trained an AI model to scan manuscript pages and ignore the text, picking out only the drawings in the margins.
-Smart Classification: It automatically figures out if a doodle is a "Dragon," "Knight," or "Grotesque" (a -fancy word for hybrid monster things).
-Geospatial Visualization: You can see where these manuscripts actually came from on an interactive map.
-Clean UX: Instead of a clunky academic archive, it's a visual-first feed. You just scroll and explore.
How I built it
This is a full-stack project I built solo:
-Data Handling: I had to wrangle the IIIF (International Image Interoperability Framework) APIs. This was messy. There were lots of inconsistent metadata standards from different museums that I had to standardize and clean up to make it usable. -ML Pipeline: I fine-tuned YOLOv11 on a custom dataset I annotated. The challenge was getting it to distinguish between a "decorative border" (boring) and a "drawing of a monkey doctor" (cool). I also used ResNet50 for the motif classification. -Backend: Built with FastAPI because it's fast and handles the async image processing well. -Frontend: React + Vite. I focused heavily on making the UX smooth—using Tailwind for styling and Leaflet for the maps.
Challenges I ran into
The biggest headache was the data. IIIF manifests are technically standards, but every institution implements them slightly differently. I spent a lot of time writing specific parsers to get clean, high-res images from the Wellcome Collection and British Library without crashing the pipeline. Also, the ML model initially thought everything was a marginalia drawing, including water stains. I had to do several rounds of "negative mining" (showing it empty pages) to stop it from flagging blank parchment.
Accomplishments that I am proud of
I'm really proud of the pipeline's efficiency. It takes a raw manifest URL and spits out a fully indexed gallery in under a minute per manuscript. I also think I nailed the "accessibility" aspect. Most tools for this stuff are built for PhDs and are super hard to use. Mine is designed for anyone who thinks history is cool.
What I learned
I learned way more about computer vision constraints than I expected. Specifically, it's hard to detect "style" vs "objects." I also gained a huge appreciation for UX in digital humanities. Making complex archival data feel "snappy" and "modern" is a legitimate engineering challenge.
What's next for Medieval Marginalia Explorer
More Data sources: Adding the Bibliothèque nationale de France APIs. Better Search: Implementing a "find more like this" feature using visual embeddings. Crowdsourcing: Letting users correct the AI's tags if it mistakes a dog for a dragon.
Built With
- fastapi
- javascript
- numpy
- python
- pytorch
- react
- tailwind
- uvicorn
- vite
- yolov11


Log in or sign up for Devpost to join the conversation.