
Inspiration
Studies suggest that 10-15% of all medical cases can be traced back to misdiagnoses. As a team, we wanted to come together and develop a product that could help alleviate this metric for users of all backgrounds.
What it does
Our app offers personalized diagnoses based on user-inputted symptoms. Whether it’s a cough, joint pain, or a more severe issue, our advanced Large Language Model powered by Google BERT provides a prognosis tailored to the symptoms entered. MediSense also guides patients on the recommended next steps to manage their diagnosed condition or disease.
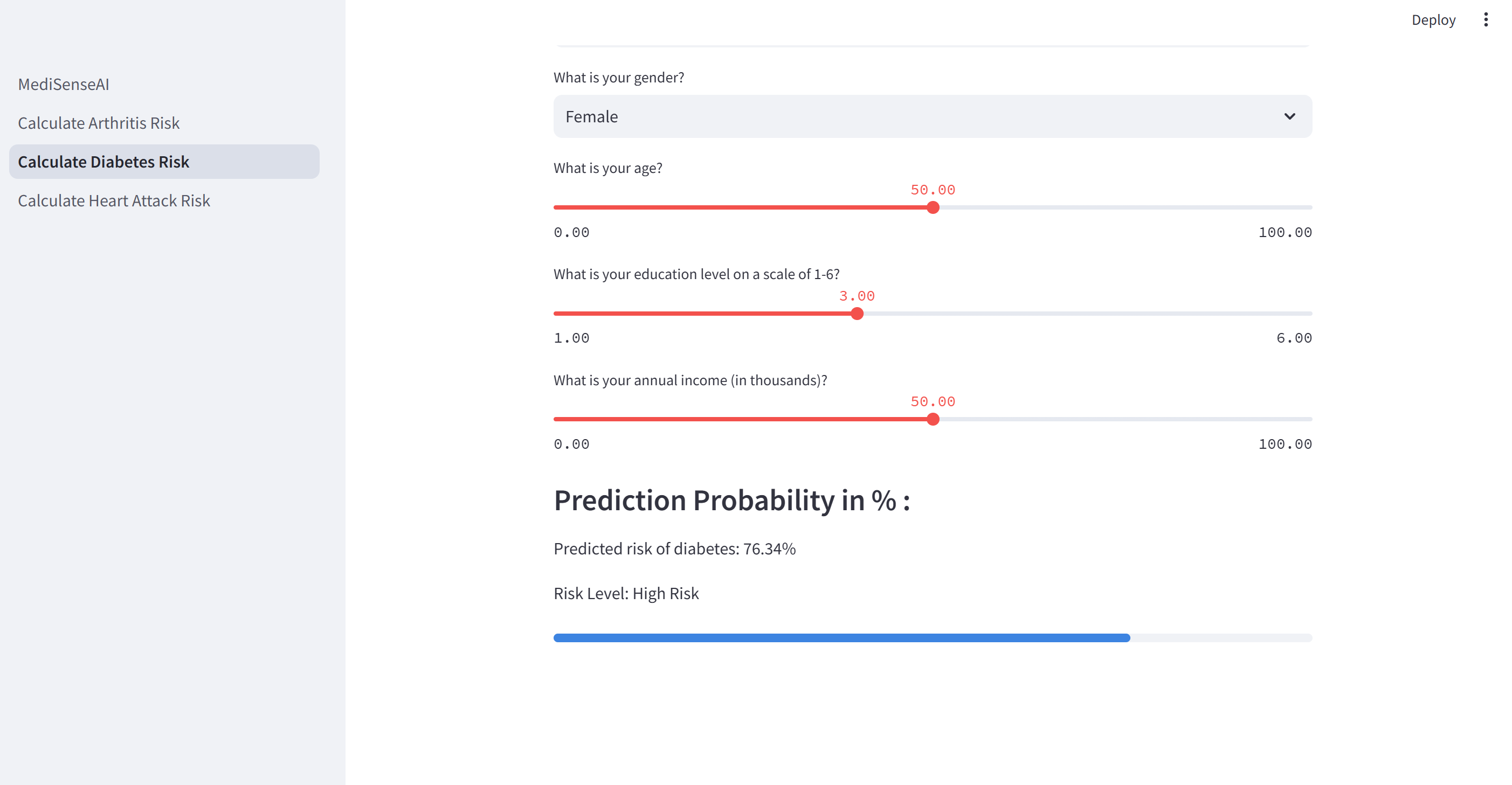
In addition to diagnosis, patients can access our specialized risk calculators to understand their risk percentages for various conditions based on their personal risk factors. Currently, we offer calculators for three conditions that utilize logistic regression and random forest classifier models to assess risk levels. These tools help patients gain insight into how their lifestyle choices and individual attributes impact their likelihood of developing specific conditions or diseases.
How we built it
There were two parts to this project: the LLM and the ML models.
For the LLM, we first obtained an open-source dataset of medical data linking symptoms to a prognosis. For instance, if a patient were experiencing chest pain and a shortness of breath, then the prognosis in the dataset would most likely be heart attack because those are both common symptoms associated with heart attacks. In total, there were nearly 5,000 rows of data, with 131 unique symptoms and 41 unique diseases that were prognosed based on those diseases. We then preprocessed, lamented, and tokenized the data and fed the data into an untrained BERT model, fine-tuning the model based off of the data that we obtained. Once we had the model, we could feed the model with a user input of the symptoms they have in string format (ex: The input: “I have had shortness of breath for a while now, and my chest has been aching for the past few weeks and only getting worse” would return the prognosis “Heart Attack”).
To train the ML models, we cleaned the data, and followed with an 80/20 split for training and testing. We prompted the user to fill out a questionnaire that mirrored the inputs in the training data sets, and used a multitude of Python libraries to pre-process and scale the user input data. Finally, we used RandomForestClassifier and Logistic Regression machine learning learning models to train the data, and followed by calculating relevant outputs and the model’s accuracy.
Once we had both backend parts of the project, we used the streamlit library to create a front-end platform. The main component of the app is the LLM, so we put the LLM on the main page for the user to insert input into in order to get their prognosis. We also included a section of additional steps that the user could take to improve their health considering the prognosis. To access the machine learning models that predict the chance of certain diseases, there is a side-bar that the user can click on. There is then a questionnaire for the user to access, and the different models would then take those inputs and determine the percentage risk of the user having a certain disease.
Challenges we ran into
As we developed our Machine Learning models, one major challenge we faced was overfitting of the data. Since the number of Diagnosed and Undiagnosed cases was unequal in our datasets, the model would be inaccurate at first. We had to overcome this by using SMOTE to balance the data and ensure that each test case was being equally sampled in the data. Another challenge we faced was compiling each of our individual models (the LLM and the Machine Learning models) into one singular app. With many different datasets, file paths, and Streamlit configurations, it was weird to bring them all together. Using specialized Streamlit formatting, we were able to compile all the pages as a subdirectory of the main landing page, which made our user interface ready for use as well.
Accomplishments that we're proud of
We take immense pride in delivering a clean and intuitive front-end user interface that makes navigating our platform effortless for patients. Our web application is not only user-friendly but also thoughtfully designed, with comprehensive formatting that ensures a seamless experience. The carefully chosen aesthetic color scheme adds to the overall visual appeal, making the process of exploring their health journey feel approachable and engaging.
Beyond the front-end, we’re equally proud of the sophisticated work we’ve accomplished on the backend with our Machine Learning models and LLM. We have successfully developed highly accurate and reliable models that generate realistic and meaningful results, ensuring that patients receive dependable insights based on their input.
What truly sets us apart is our commitment to creating a real-world solution that offers tangible benefits. We are proud to contribute to the medical field by providing a tool that enhances clarity for patients, empowering them to better understand their health conditions and make informed decisions about their care. This blend of advanced technology with an emphasis on user experience demonstrates our dedication to creating a solution that is not only technically robust but also genuinely valuable in helping patients on their journey to better health.
What we learned
We learned how to work with LLMs and Machine Learning models in a real-world application. Working with these tools gave us experience with Pandas, PyTorch, Transformers, Bert, Scikit-Learn, and more libraries! Furthermore, we learned how to integrate these models with a user interface using the python Streamlit library, allowing us to create a full-stack project rather than just a backend application.
What's next for MediSenseAI
We aim to continue developing MediSenseAI in two primary pathways: improving model accuracy and allowing for more user input variability. To do so, we’ll conduct our training on datasets greater in size and accuracy, and continue to explore new ML technologies to train the data on. Although our ML Models achieved ~80% accuracy across different datasets, there is certainly motivation to refine our methods further.
Built With
- bert
- datasets
- imbalanced-learn
- numpy
- pandas
- python
- pytorch
- scikit-learn
- smote
- streamlit
- transformers

Log in or sign up for Devpost to join the conversation.