-
-
Software Architecure Dia
-
query time data comparing graph hits and db queries
-
direct mcp interaction within the Claude App
-
graph persistence across various sessions
-
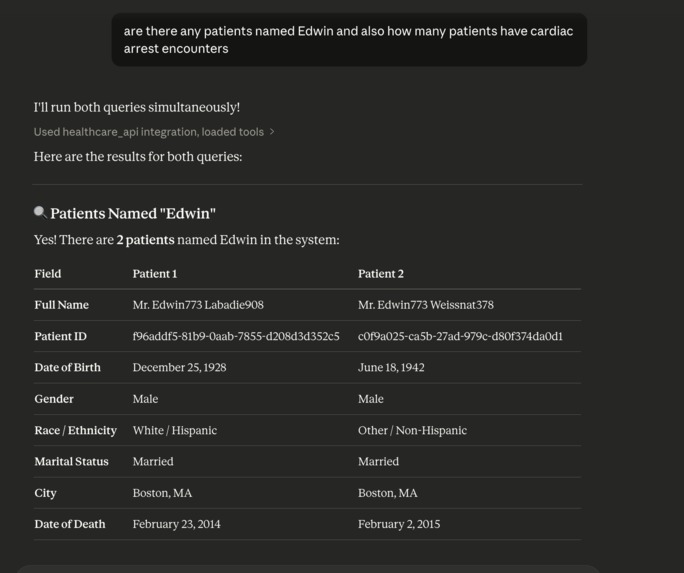
Various simultaneous tool calling
-
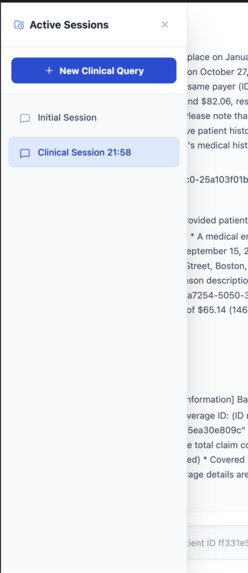
mutliple chats possible
-
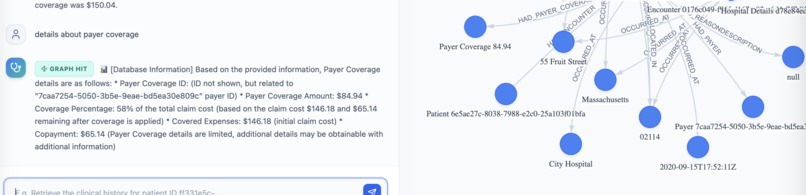
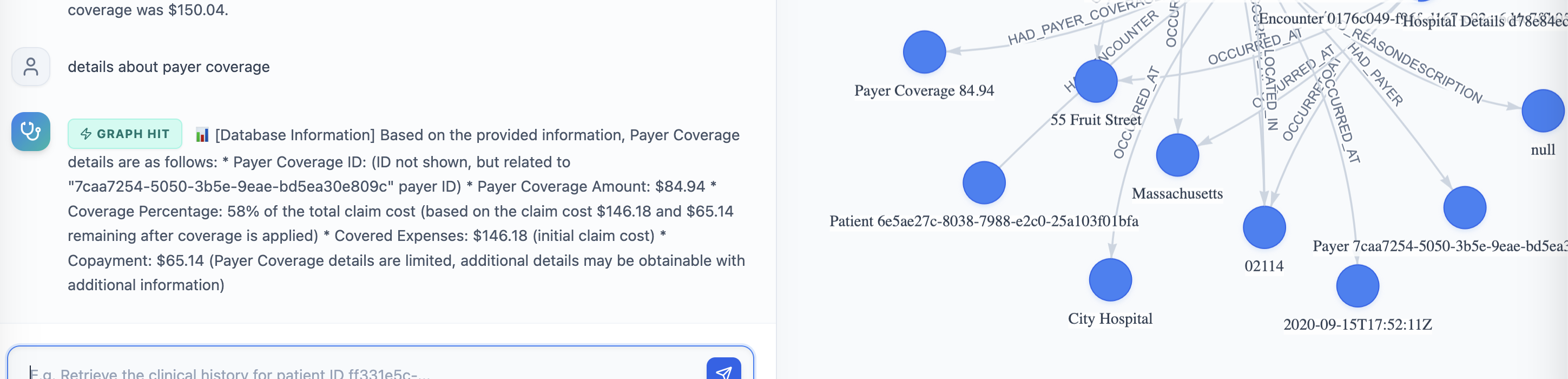
A graph hit returning blazing fast replies
-
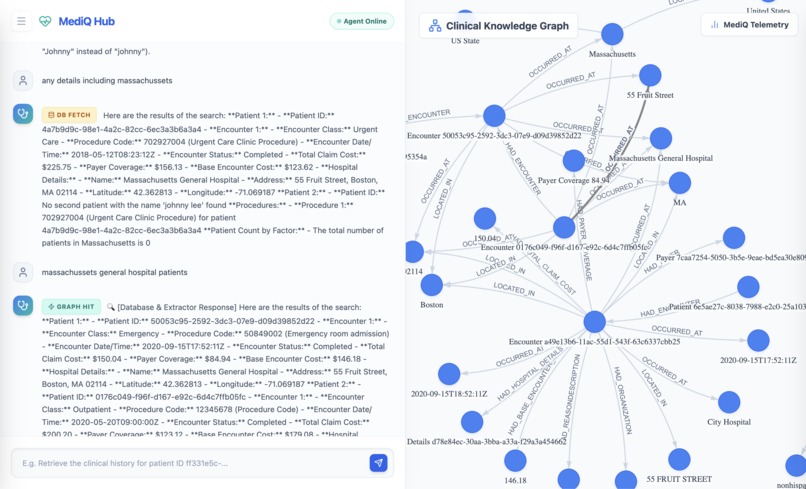
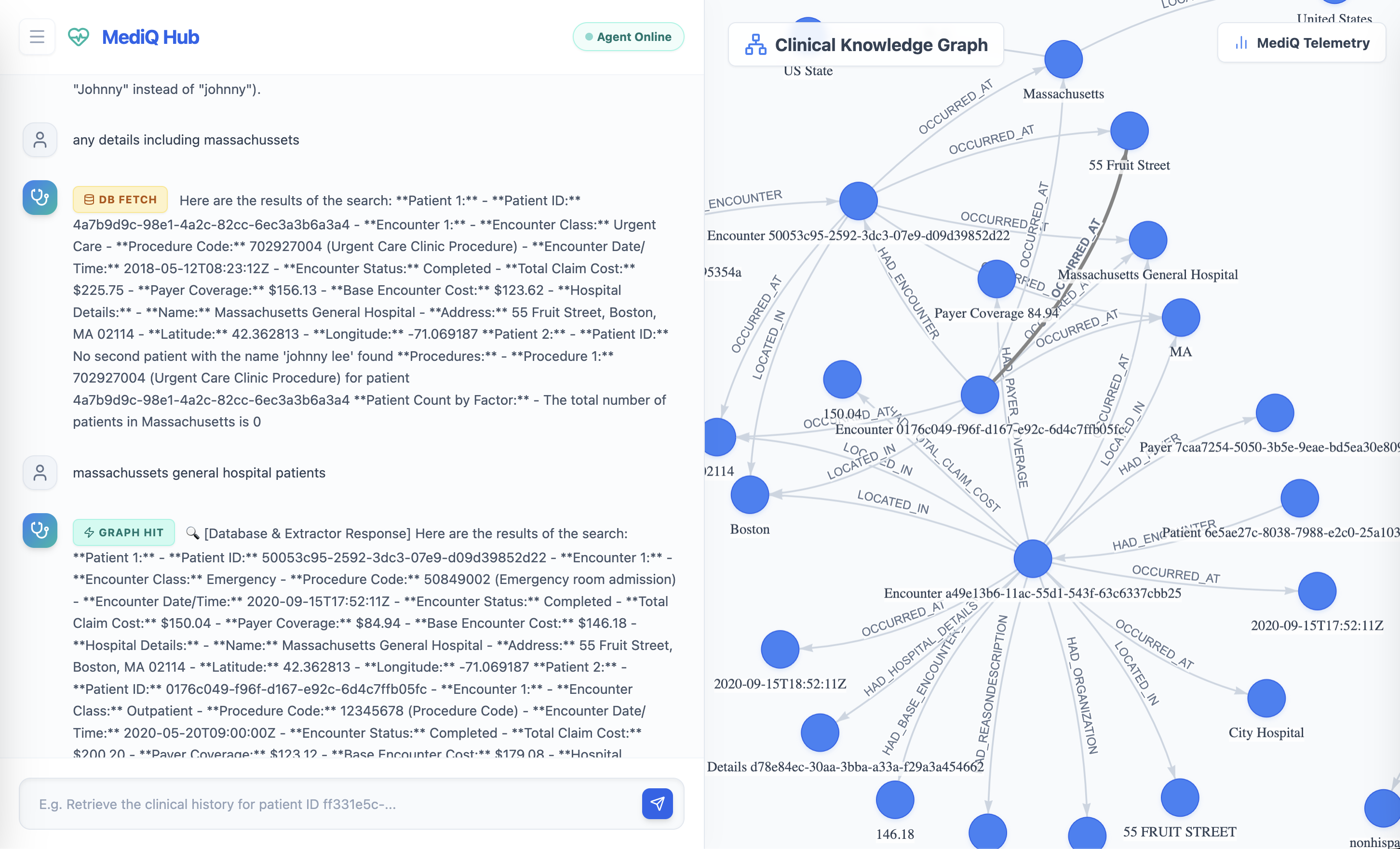
Overall graph and chat interface
MediQ
Inspiration
Hospitals nowadays, face an increasingly difficult challenge. Patients experience extremely long queues, appointment scheduling delays, and overwhelmed healthcare staff.
While population size contributes to this problem, a major underlying cause is the enormous volume of medical big data that hospitals must manage.
Doctors, nurses, and reception staff often spend significant amounts of time navigating slow databases and fragmented systems just to retrieve patient information. This reduces the time available for actual patient care.
We realized that traditional database systems treat healthcare data as static information that must be queried repeatedly.
Instead, we envisioned a system that could learn from every query and continuously improve how healthcare data is retrieved.
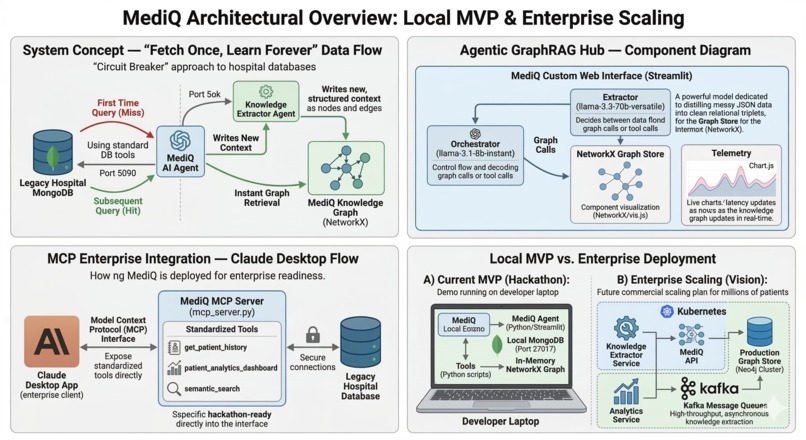
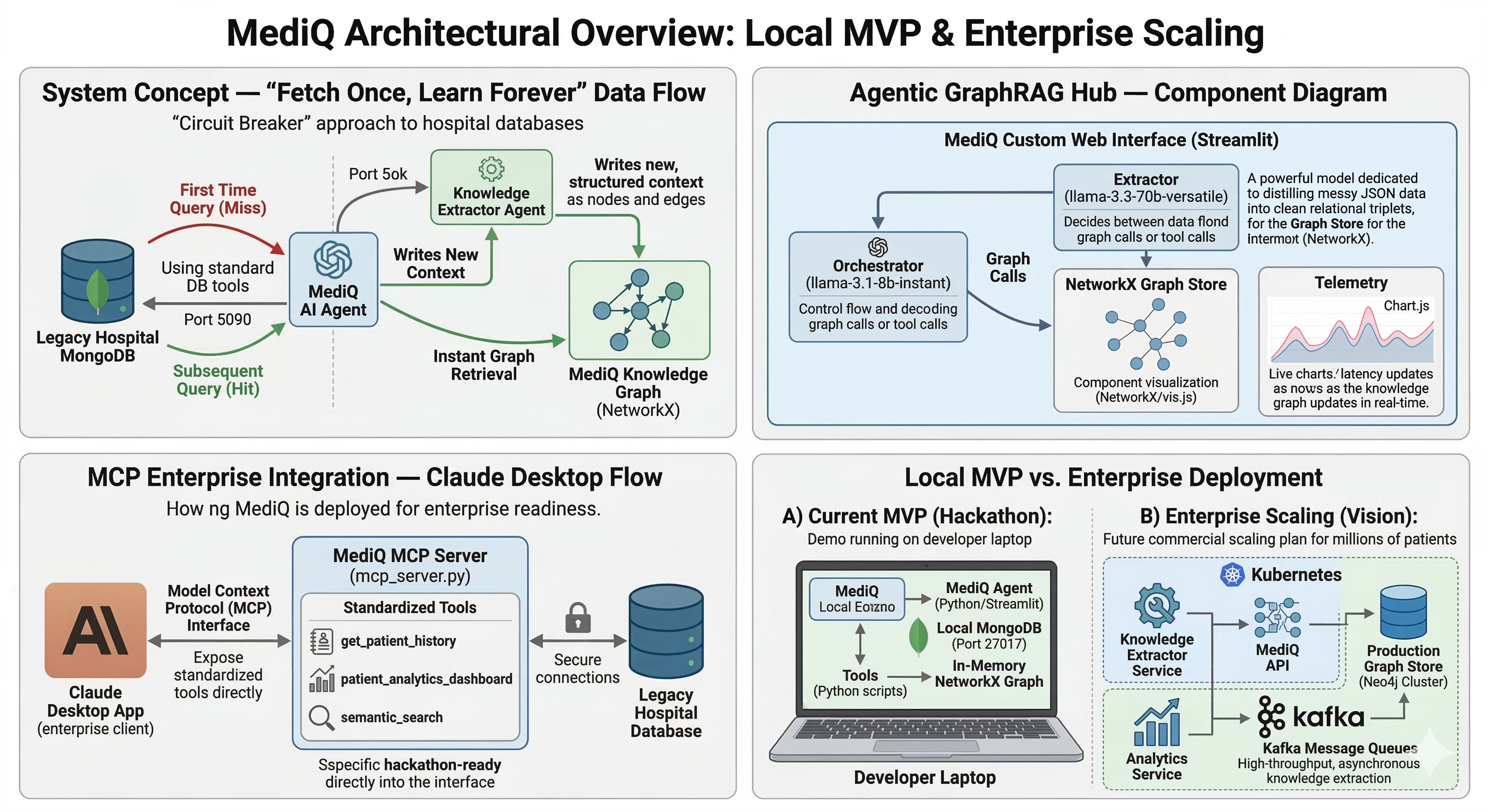
MediQ was created to address this challenge. It introduces a self-learning agentic framework that combines Knowledge Graphs and the Model Context Protocol (MCP) to transform raw patient databases into an intelligent reasoning system capable of near-instant responses.
What it does
MediQ operates using a core philosophy called:
Fetch Once. Learn Forever.
Instead of repeatedly querying slow databases, MediQ builds a dynamic knowledge graph from previous queries and uses that graph to accelerate future responses.
The system currently operates through two primary interfaces.
MCP Enterprise Integration
MediQ includes a Model Context Protocol (MCP) server that standardizes the hospital database into structured AI tools.
These tools expose the underlying MongoDB patient dataset through secure API endpoints.
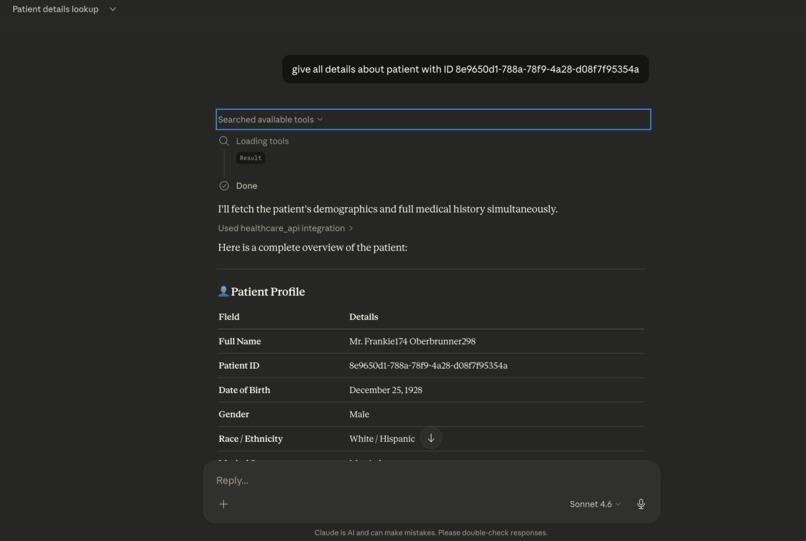
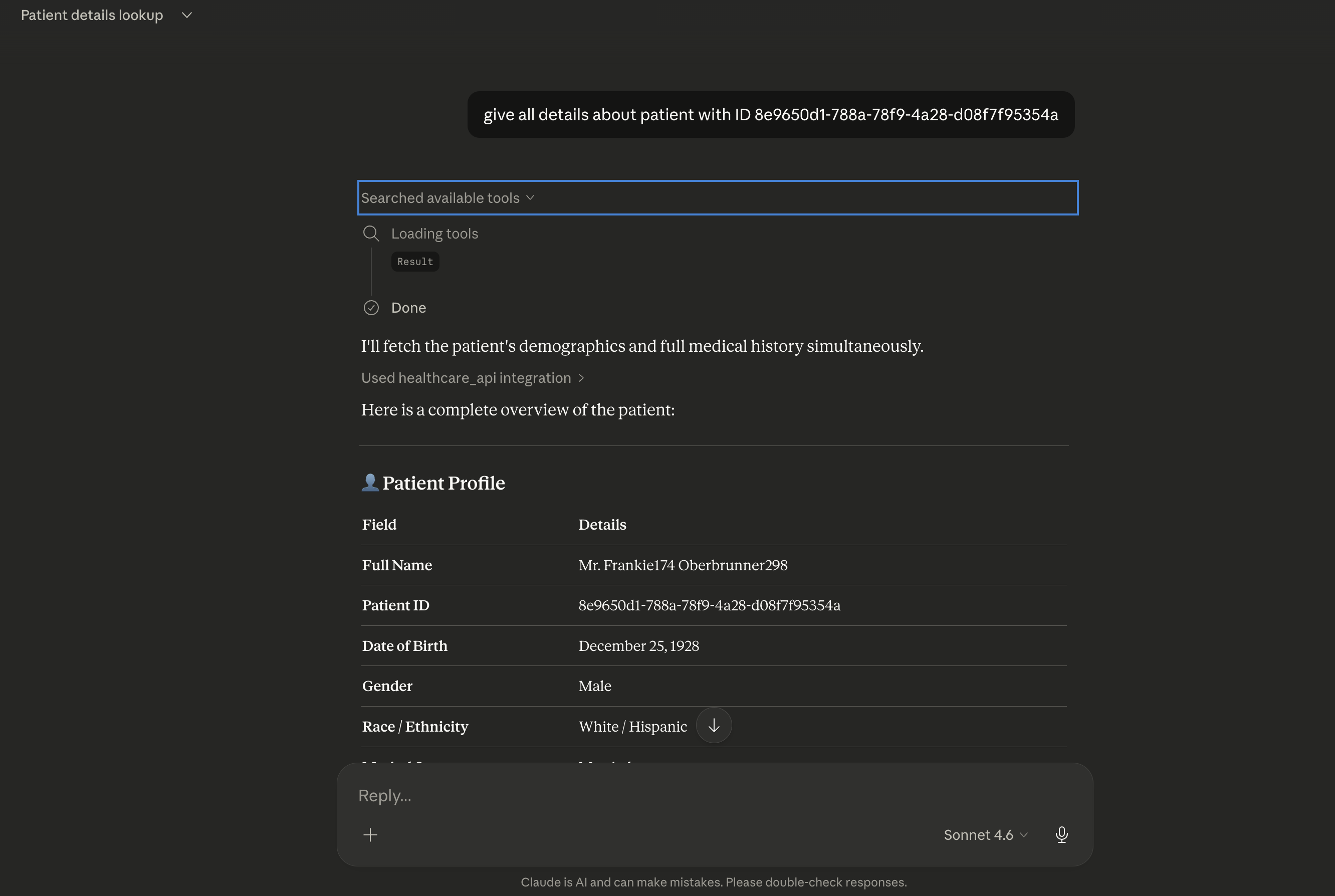
Any compatible enterprise LLM such as Claude Desktop can autonomously call these tools.
For example, the model can:
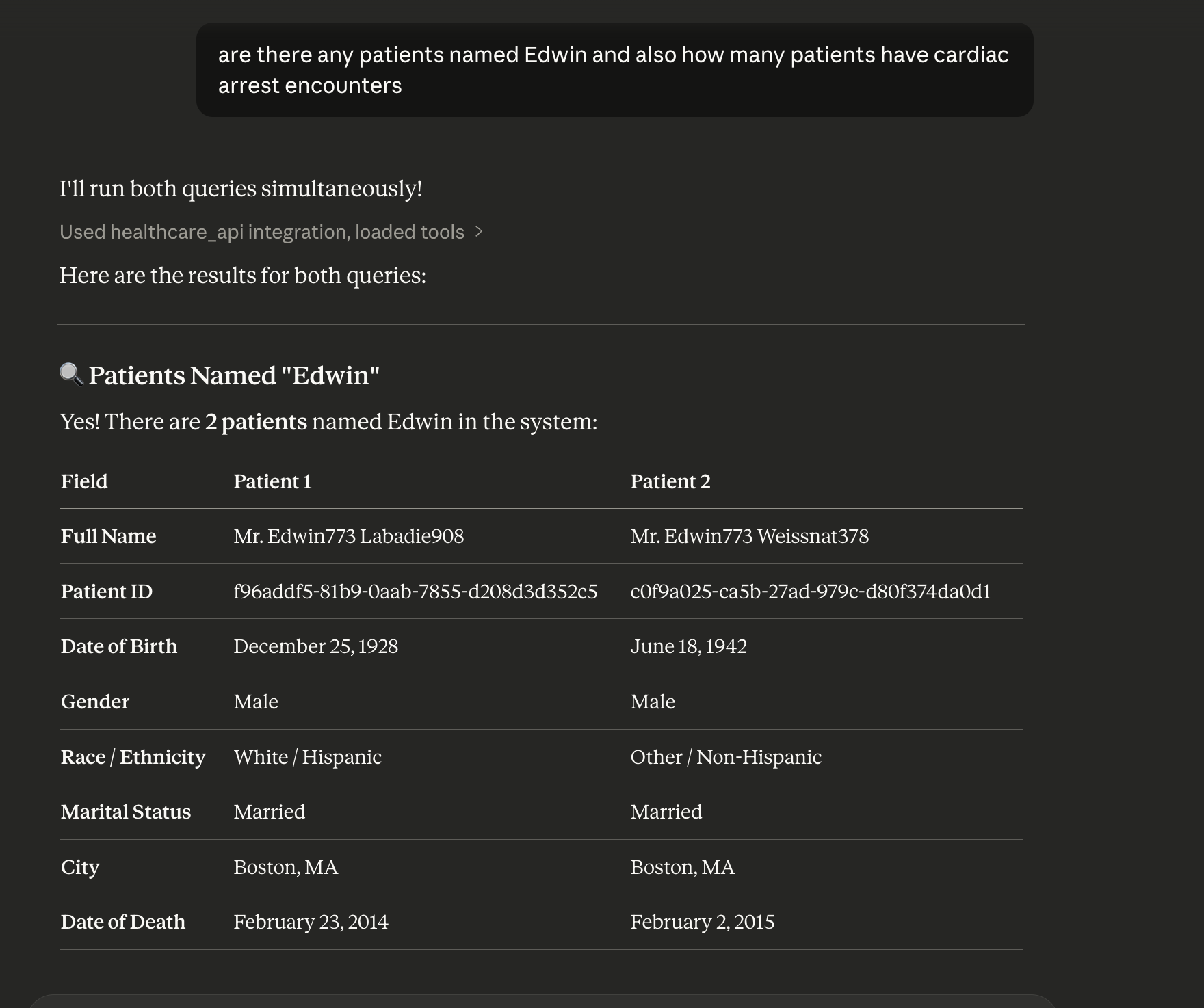
• Search for a patient by name
• Retrieve the patient's UUID
• Fetch their complete medical history
This process happens entirely through natural language tool orchestration, without writing SQL queries.
MediQ Hub — Agentic GraphRAG Interface
Alongside the MCP integration, MediQ includes a custom web application called the MediQ Hub.
When a user asks a question about patient data:
- The Agentic Orchestrator first checks an in-memory Knowledge Graph
- If the graph already contains the required relationships → the answer is returned instantly
- If the information does not exist → the orchestrator calls the database through MCP tools
The retrieved raw data is then:
• processed
• converted into semantic relationships
• used to update the knowledge graph in real time
As more queries occur, the graph continuously grows, allowing MediQ to bypass database queries and deliver sub-second response times.
How we built it
Data Layer
The system uses the Maven Analytics Healthcare Dataset, which contains records for:
• patients
• encounters
• procedures
• hospitals
• insurance providers
This dataset is stored locally in MongoDB.
A Python Flask server provides REST APIs that expose:
• CRUD operations
• analytics endpoints
• data aggregation queries
These APIs allow structured access to the healthcare database.
MCP Tool Server
The Flask APIs are wrapped into an MCP server, which exposes them as structured tools for LLMs.
This allows large language models to securely interact with the database through controlled API calls.
Through this tool interface, the LLM can:
• search patient records
• retrieve medical histories
• perform aggregation queries across the database
This transforms the database into an AI-accessible tool ecosystem.
Agentic Orchestrator
The MediQ Hub runs a custom Agentic Orchestrator responsible for managing query execution.
The orchestrator uses fast Llama models hosted on Groq for inference and coordinates the workflow using LangGraph.
The orchestrator determines whether a query should be answered using:
• the knowledge graph
or
• database tools
This intelligent routing dramatically improves retrieval speed.
Knowledge Extraction Pipeline
Whenever raw JSON data is retrieved from the database, a background extraction model processes the response and converts it into semantic triplets.
Examples include:
Patient_ID → HAD_ENCOUNTER → Checkup
Patient_ID → VISITED → Hospital_Name
These relationships are stored inside an in-memory graph built using NetworkX.
Over time, this graph becomes a growing knowledge network of patient relationships.
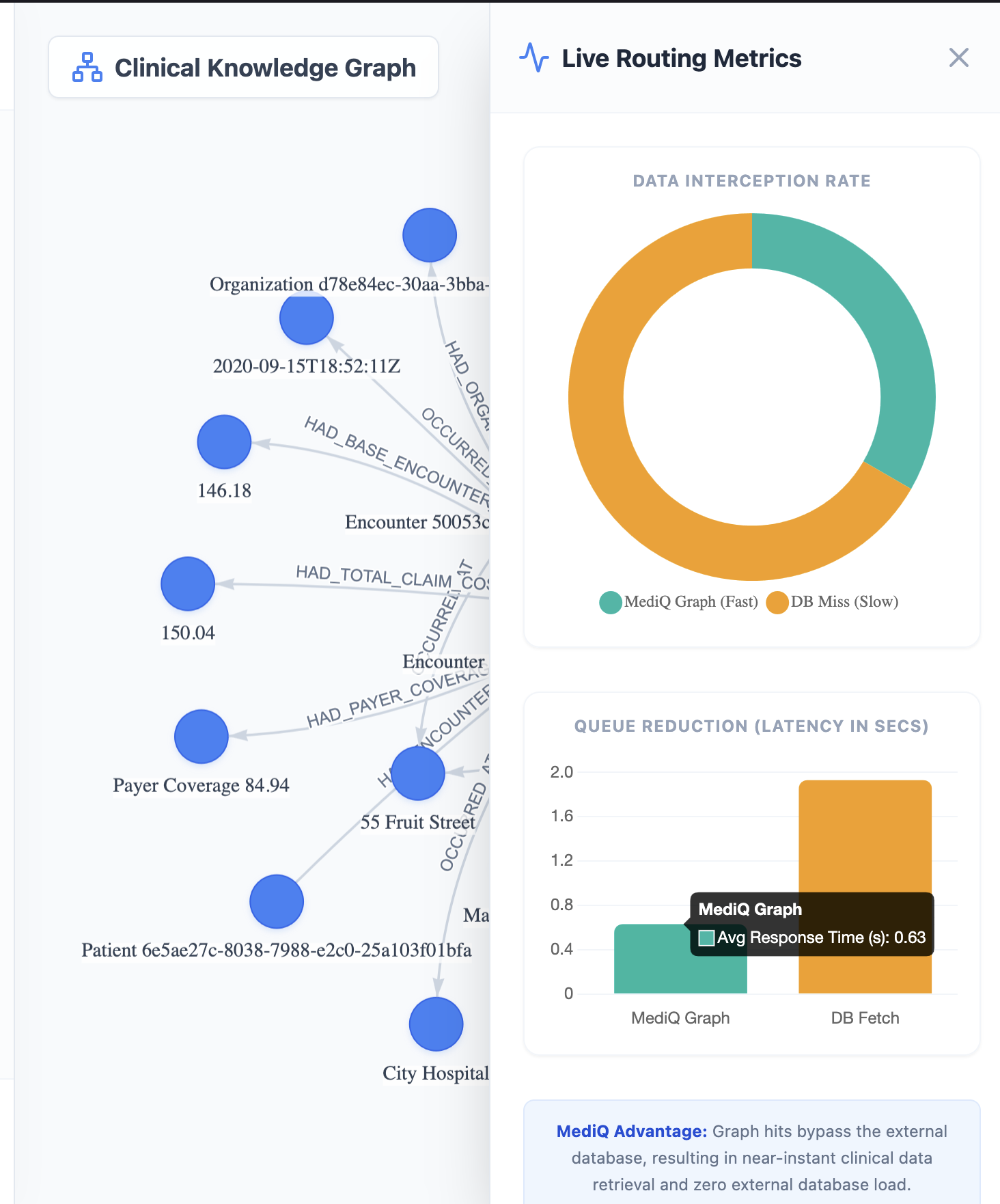
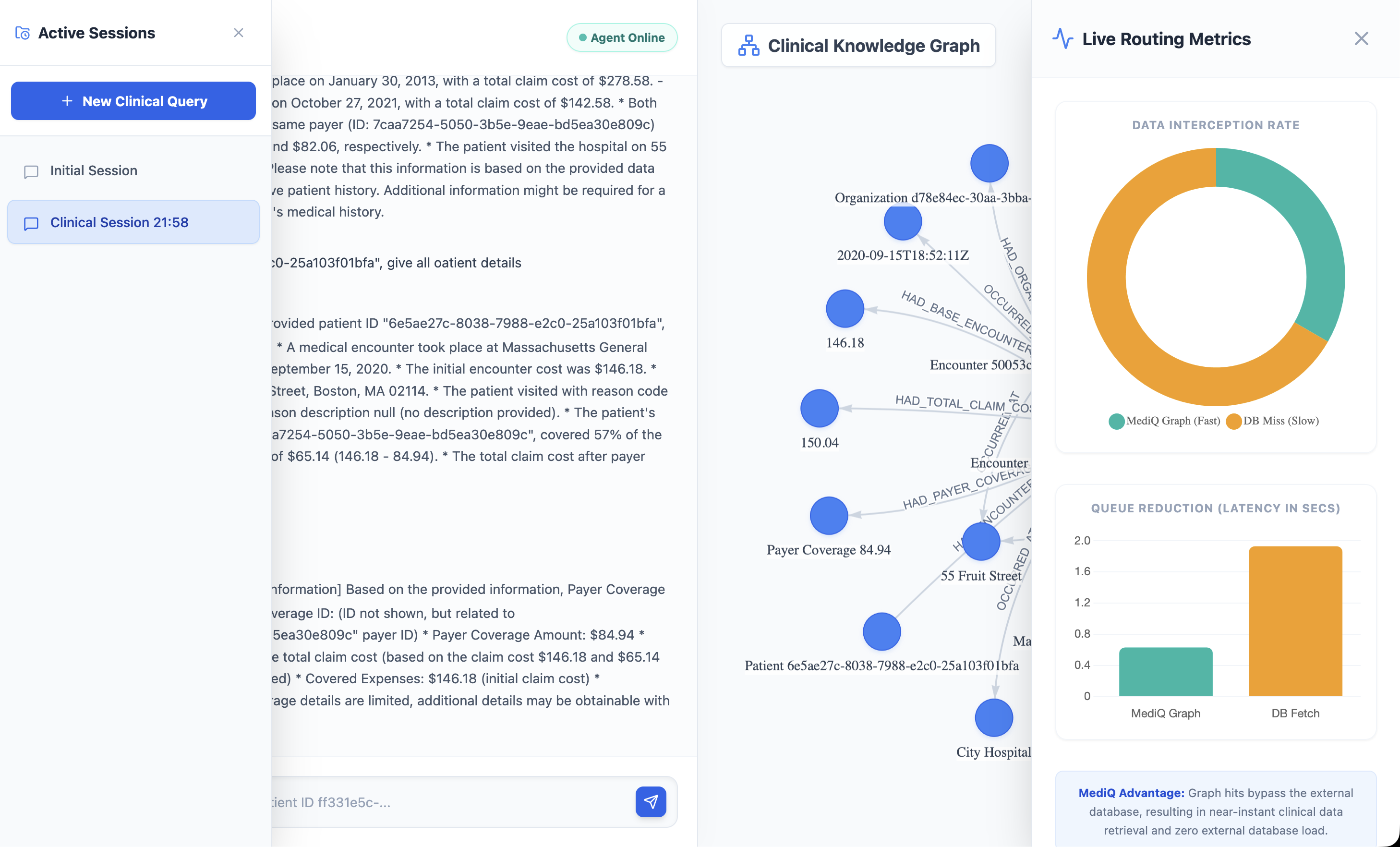
Graph Visualization and Telemetry
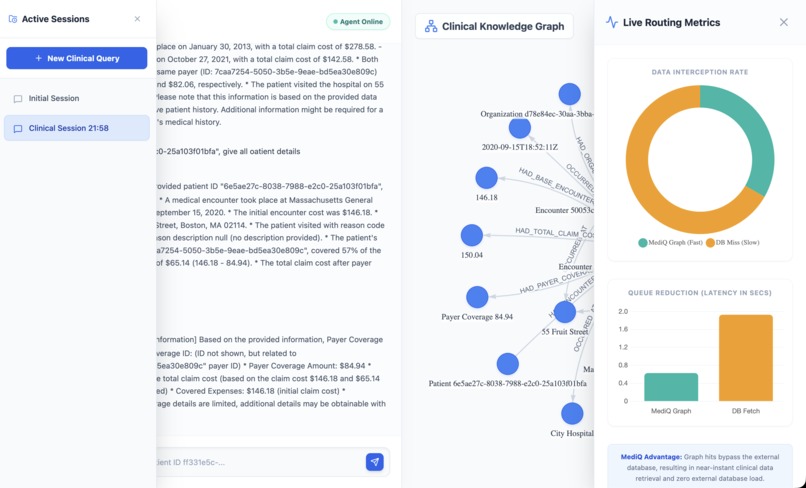
The MediQ frontend provides a live visualization of the knowledge graph using vis.js.
Users can observe how nodes and relationships appear in real time as the system processes queries.
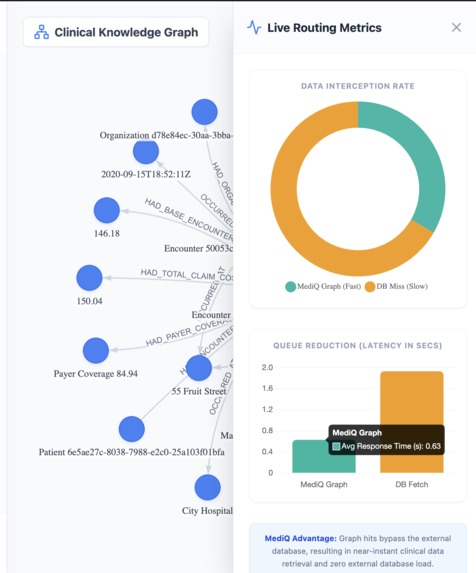
A telemetry dashboard built with Chart.js displays:
• query statistics
• graph hits vs database misses
• latency comparisons
This demonstrates the performance advantage of graph-based retrieval.
Challenges we ran into
Developing a dynamic agentic retrieval system introduced several engineering challenges.
LLM Tool Overuse
Large language models often prefer to call database tools repeatedly, even when information has already been retrieved earlier.
This behavior significantly slows down the system.
To address this, we implemented a Circuit Breaker architecture inside the orchestrator.
Every query first checks the knowledge graph.
If a graph match is detected, the system hides database tools from the LLM payload, forcing the model to answer directly from the graph.
Token Limit Constraints
Another challenge involved handling extremely large JSON payloads from the medical dataset.
These responses often exceeded LLM token limits.
To solve this, we implemented a truncation strategy that allows the extraction model to process the full JSON while limiting the text passed back to the conversational model.
LLM Memory Corruption
We also encountered issues where raw tool execution logs were being stored in the LLM's conversation memory.
This caused syntax errors during follow-up queries.
To solve this, we built a clean memory routing system that separates:
• transient tool outputs
• human-readable conversation history
Accomplishments that we're proud of
One of our biggest accomplishments is demonstrating a working GraphRAG system that learns directly from database queries and improves performance over time.
The telemetry dashboard clearly shows how graph retrieval drastically reduces latency compared to traditional database calls.
We also successfully implemented dynamic LLM tool chaining, allowing the model to combine multiple APIs to answer complex queries.
Another key achievement was building a complete clinical-themed user interface with:
• interactive knowledge graph visualization
• live performance metrics
• real-time graph updates
What we learned
Building MediQ showed us that designing agentic AI systems requires careful control of data flow, tool usage, and memory management.
Simply connecting a language model to a database is not enough.
Reliable orchestration requires:
• strict schema enforcement
• robust error handling
• intelligent routing between memory systems and external tools
We also learned that knowledge graphs are extremely powerful when combined with large language models, especially in domains like healthcare where relationships between entities are more important than raw records.
What's next for MediQ
The next stage of MediQ focuses on scaling the system for real hospital environments.
We plan to introduce asynchronous message queues using Kafka to support the concurrent extraction tasks and prevent UI delays during heavy workloads.
We will also migrate from the in-memory NetworkX graph to a persistent Neo4j graph database, allowing the knowledge graph to scale across millions of nodes.
Finally, we plan to develop a No-Code Tool Builder that allows hospital administrators to visually define custom datasets.
MediQ will automatically generate the required API endpoints and register them as MCP tools, allowing non-technical users to integrate their data without writing code.
Built With
- agenticai
- docker
- dynamicrag
- flaskapi
- javascript
- kafka
- mcp
- mongodb
- networkx
- python



Log in or sign up for Devpost to join the conversation.