-
-
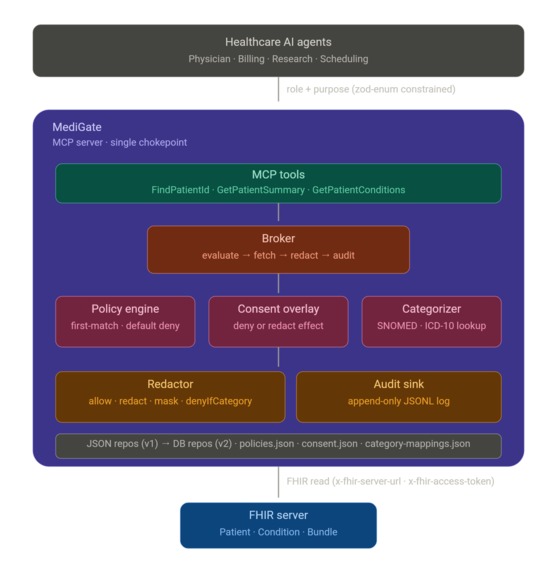
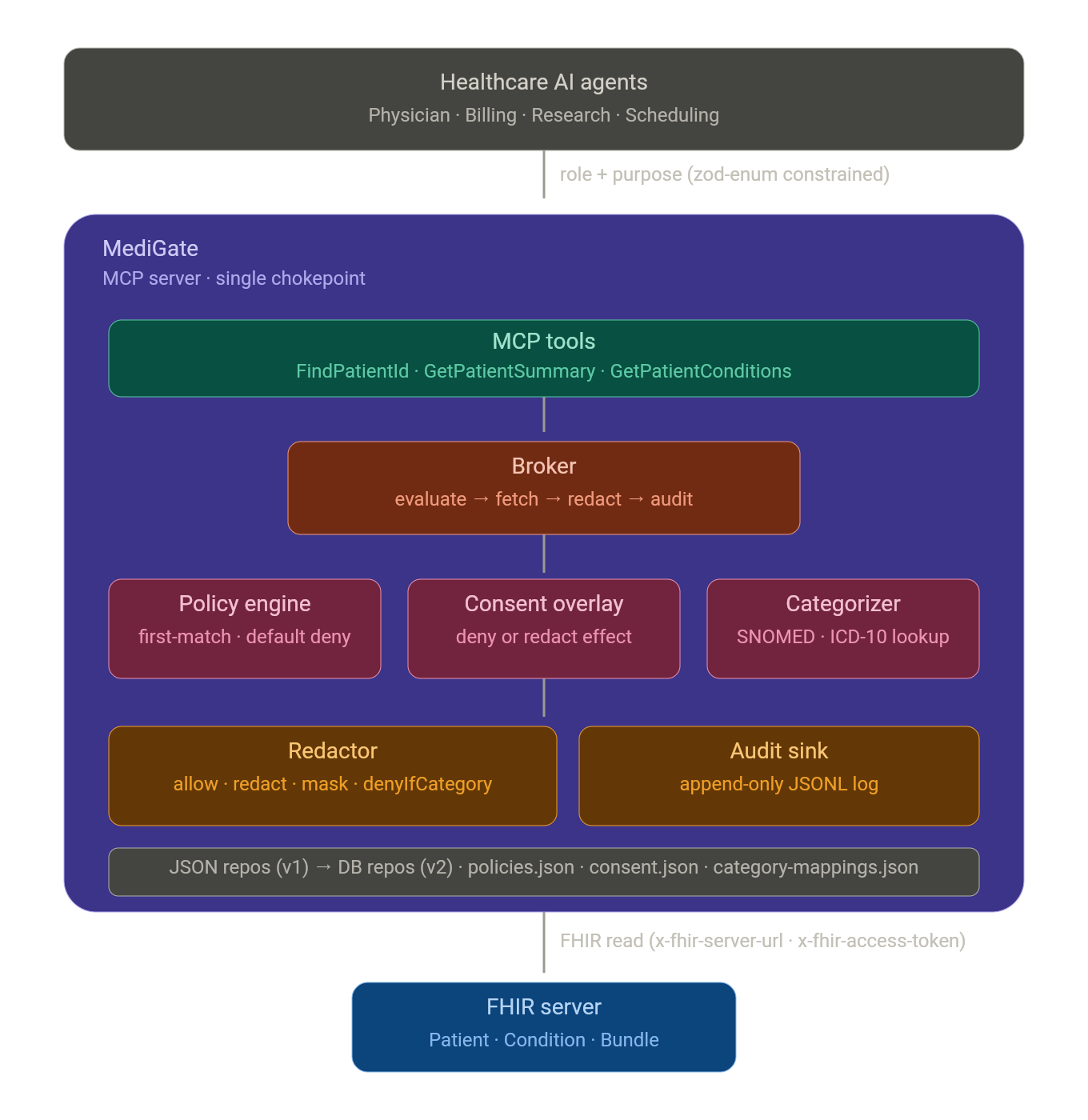
MediGate Architecture
-
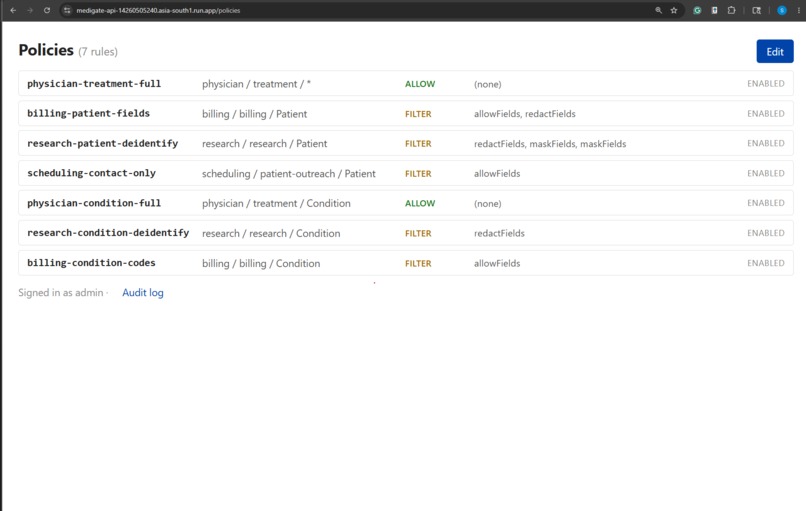
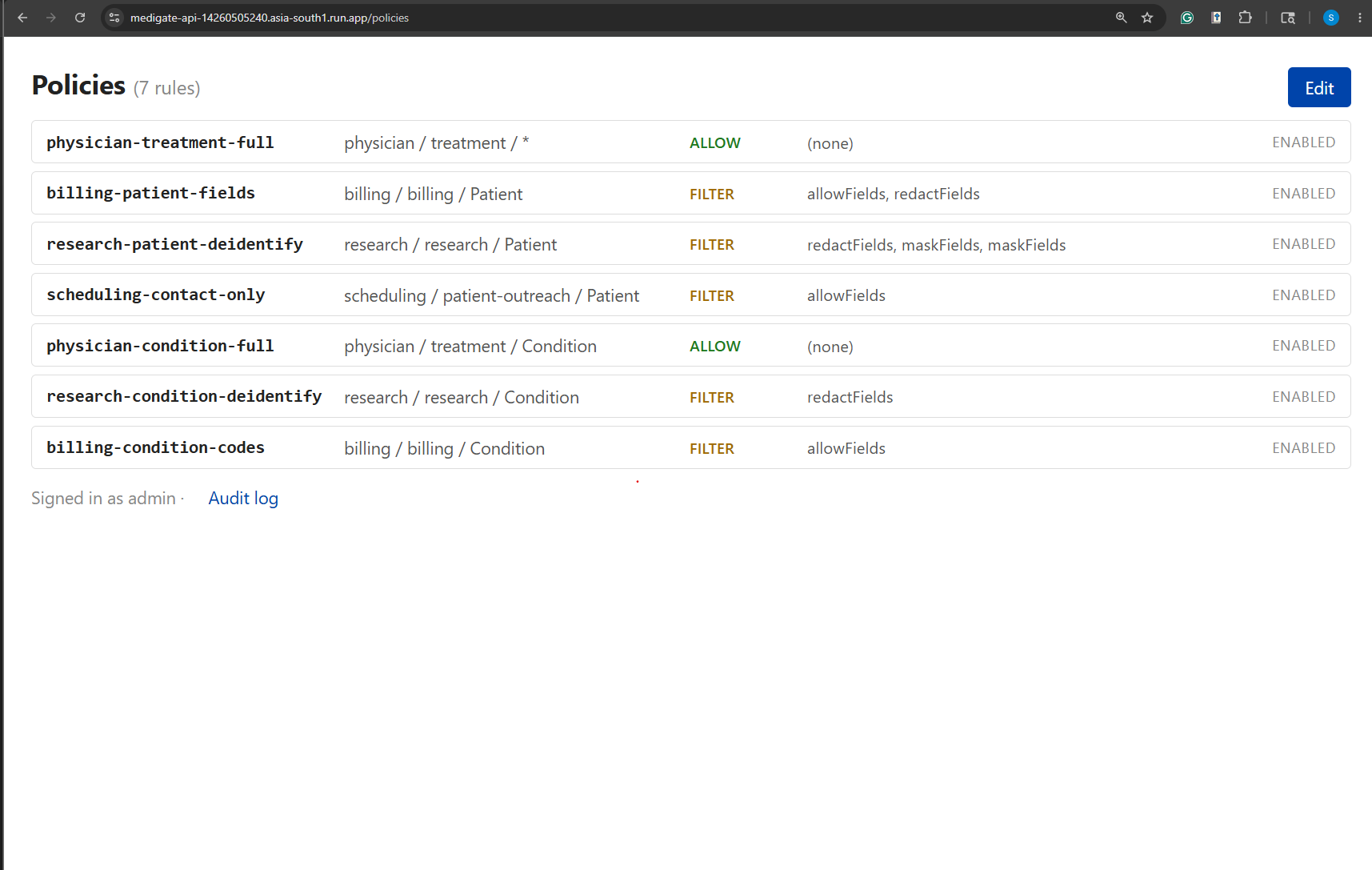
Policy Dashboard
-
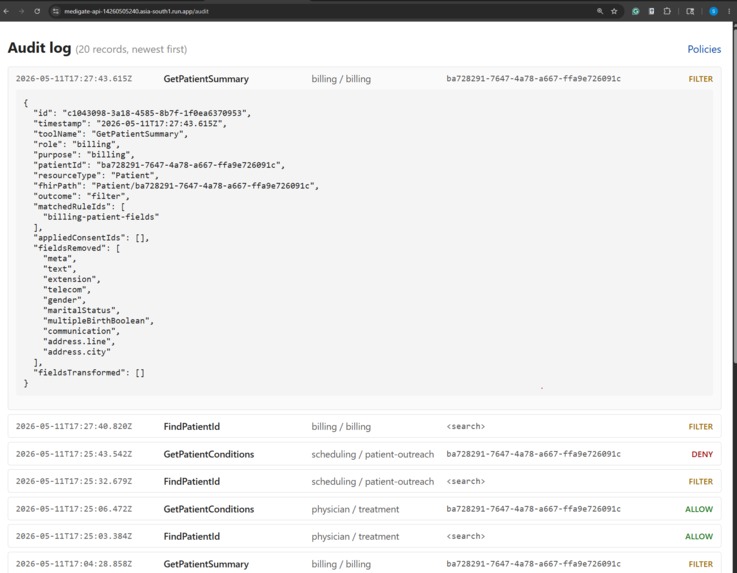
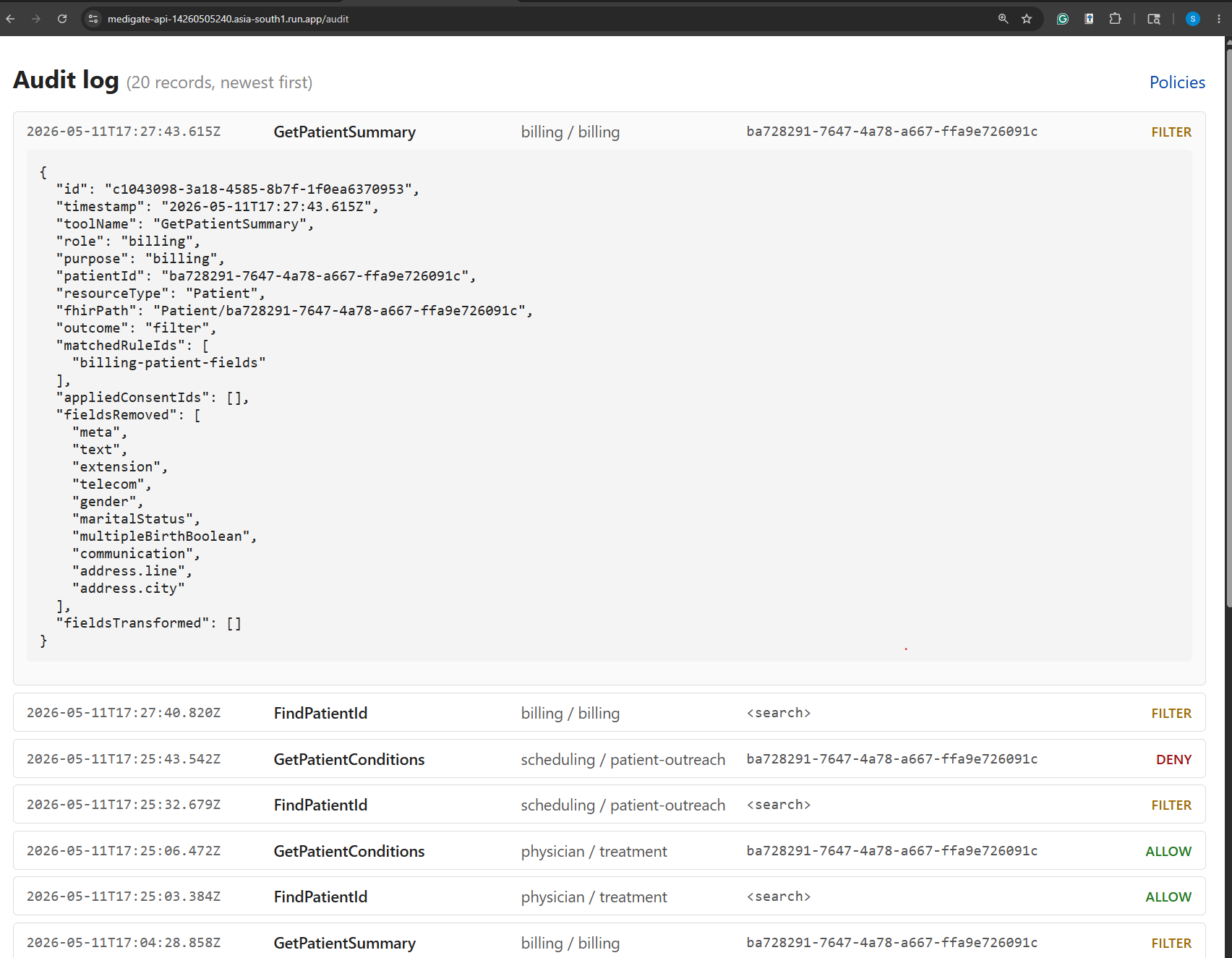
Audit Dashboard (filtered)
-
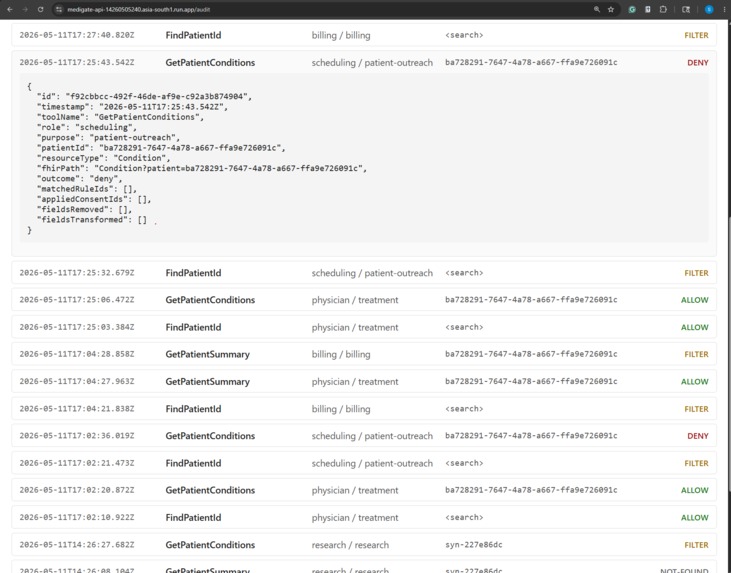
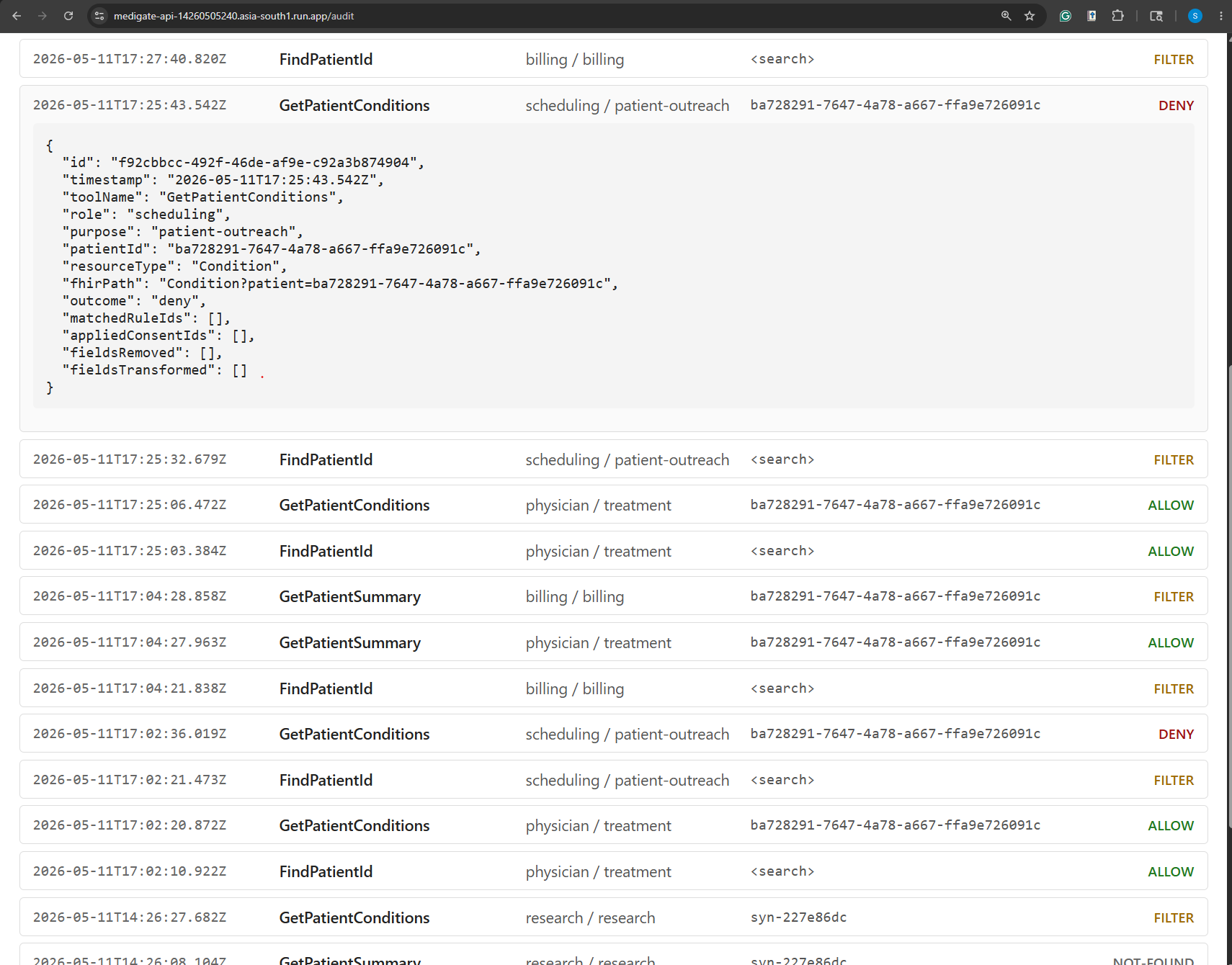
Audit Dashboard (denied)
Inspiration
Watching the first wave of healthcare AI demos, I kept noticing the same uncomfortable pattern: an agent gets handed a SMART token, gets pointed at a FHIR server, and from that moment on, the only thing standing between a patient's most sensitive data and an LLM's curiosity is a system prompt. "You are a billing assistant. Only look at billing-relevant fields." That instruction is doing an enormous amount of unearned work.
The thing is, this isn't hypothetical. The model hallucinates a billing claim that pulls in a depression diagnosis. The research agent helpfully summarizes a patient's HIV status because the prompt didn't explicitly say not to. Compliance comes asking who saw what last quarter, and the honest answer is "we don't know, the LLM decided." HIPAA's "minimum necessary" standard wasn't written with stochastic parrots in mind, and "trust the prompt" is not a control that survives an audit.
What inspired MediGate was a simple reframing: role, purpose, and consent are not the agent's properties to declare, they're the broker's properties to enforce. The same MCP server, talking to the same FHIR backend, should hand a physician, a biller, a researcher, and a scheduler four genuinely different views of the same patient, governed by policy data, not by hoping the model behaves.
The Agents Assemble brief lit this up perfectly. The "last mile" the brief talks about, converting raw model intelligence into something a hospital could actually deploy, runs straight through this access-control gap.
What it does
MediGate is an MCP server that sits between healthcare AI agents and FHIR data. On every single tool call, it asks four questions before any bytes leave the broker:
- Role: What kind of agent is asking? (physician, billing, research, scheduling)
- Purpose: Why? (treatment, billing, prior-auth, research, patient-outreach)
- Consent: Has the patient restricted any of this?
- Minimum necessary: Does this role-and-purpose combination actually need every field?
The agent gets back the data shaped to its authorization, a structured explanation of how that shape was arrived at, and an audit id. Every decision, allow, deny, filter, not-found, error, gets one row in an append-only JSONL audit log.
Three MCP tools are exposed (FindPatientId, GetPatientSummary, GetPatientConditions), and the demo shows two end-to-end flows that capture the whole point of the system:
- Multi-agent split-view. Four agents call
GetPatientSummaryon the same patient. The physician gets the full clinical record. Billing gets demographics and identifiers with the street address and city redacted. Research gets a de-identified Patient: synthetic id, year-only birth date, no name or telecom. Scheduling gets only the contact fields it needs to call about an appointment. Same backend, same patient, four legitimately different shapes. - Consent veto. Mary has filed a restriction: no mental-health data to research or billing. When the research agent calls
GetPatientConditions, MediGate's categorizer recognizes the depression diagnosis via its SNOMED code, the consent overlay drops that entry from the bundle, and the explanation tells the LLM exactly why one fewer condition came back. The physician calling the same tool sees the full bundle, because Mary's consent doesn't restrict treatment access.
How we built it
The architectural commitment I made early was that this had to be data-driven behind repository interfaces, because the obvious post-MVP move is a web portal where a compliance officer edits policies and consent records without touching code. If the rules lived in TypeScript, that portal would be a rewrite. So policies, consent records, and category mappings are all JSON files today, sitting behind PolicyRepository, ConsentRepository, and AuditSink interfaces. The v1-to-v2 swap from file-backed to database-backed is one constructor change in wiring.ts; the broker, the engine, the redactor, and the tools never learn that anything moved.
The pipeline inside the broker is deliberately boring, which I think is the right energy for a security component:
- Load policy rules and the patient's consent record.
- Hand both to a pure-function
PolicyEnginethat walks the rules in order, first-match-wins, with*wildcards on role/purpose/resourceType, defaulting to deny if nothing matches. - Overlay consent. A
denyeffect from consent overrides any allow from the rules. Aredacteffect appends a category-aware filter that runs at the resource (or Bundle entry) level. - Fetch from FHIR.
- Run the Redactor, which applies four kinds of transformation:
allowFields(whitelist),redactFields(blacklist),maskFields(withstars,synthetic-id, orshift-datemasks, all deterministic via salted SHA-256 so audit reconciliation works across calls), anddenyIfCategory(drops entries whose codes belong to a restricted consent category). - Audit. Return the data, the explanation, and the audit id.
The Categorizer is the piece that makes consent more than a name-match exercise. It reads category-mappings.json and matches a FHIR resource's code.coding[] entries against SNOMED and ICD-10 codes belonging to a category like mental-health. Extending the system to handle substance-use or genetic data is purely a config change, no new code paths.
All data shapes have zod schemas in schemas.ts as the single source of truth: runtime validation at load time, exported types for the broker code, and a clean JSON-Schema export path for when the portal needs to validate edits. The MCP tool inputs also use z.enum() for role and purpose, which means the LLM literally cannot pass an arbitrary string; the MCP SDK rejects the call before the broker ever sees it.
For testing I went with node:test plus tsx, no extra dependency, with tests living next to source as *.test.ts. The suite landed at 53 unit tests plus one end-to-end smoke test that boots a stub FHIR server, posts a real JSON-RPC tools/call to /mcp, and asserts that the broker pipeline ran end-to-end including the audit-log write.
Challenges we ran into
The first real challenge was where role and purpose live in the request. My instincts wanted a header, or a signed token, or a sidecar, anything but "the LLM types it into the tool call." But the platform constraints are what they are, and arguing with them would have produced a beautiful design that didn't run on Prompt Opinion. The right move was to lean into the constraint, lock the values down with zod enums so they can't be fuzzed, document the trust gap honestly, and design the v2 attestation upgrade so it slots in without a rewrite.
The second was the synthetic-id reachability problem. The research-deidentify rule masks Patient.id to a synthetic value. Great for de-identification. Terrible for the follow-up call: if a research agent runs FindPatientId and gets syn-7f2c4a91 back, then tries GetPatientSummary on that id, FHIR has no idea who that is and 404s. I spent an evening trying to design a reverse lookup before realizing it was the wrong fight for v1; the demo just feeds research agents real ids via the system prompt, the gap is documented in the design spec, and v2 will add a deterministic resolver inside the broker that keeps the one-way property at the edges but lets the broker itself round-trip.
The third was getting the audit story right without overbuilding it. Real production audit has to fail closed: if you can't write the row, no data leaves the broker, full stop. But the hackathon clock is finite and a fail-closed audit pipeline that's also reliable enough not to brick the demo is a real engineering problem. I made a deliberate call: v1 fails open, the code has a // V1-LIMITATION comment on the exact line where it does, and the README's security-notes section flags it as a must-fix before any non-demo use. I'd rather ship a demo that's honest about what it isn't than one that pretends.
The fourth, and the one I didn't see coming, was circular imports. The first cut had BrokerInstance constructed in index.ts, with tools importing it from there. But index.ts already imports the tool registry, so the moment a tool imported the broker singleton, Node had a cycle. Pulling the wire-up into a dedicated wiring.ts module solved it cleanly, and as a bonus made the "swap the repos for v2" story a one-file change instead of an index.ts edit.
Accomplishments that we're proud of
- A single chokepoint that actually holds. Every tool routes through the broker. There is no escape hatch where a tool talks to FHIR directly, which means there is no policy bypass either. That property is enforced by the import graph, not by code review discipline.
- Data-driven all the way down. Policies, consent records, and category mappings are JSON. A compliance officer with no TypeScript experience could read
policies.jsonand tell you what each rule does. That's the property the eventual portal needs, and it's true today, before the portal exists. - A test suite that covers the security-critical paths. 53 unit tests on the pure-function policy engine, redactor, and categorizer, plus an end-to-end smoke that boots the real MCP transport against a stub FHIR server and verifies the audit row hits disk. The consent-overlay edge cases (
allow → filter,filter → deny, per-Bundle-entry category drops) all have named tests. - Honest documentation of the gaps. The design spec has a §12 titled "Known gaps and explicit non-goals." The README has a "Security notes (read before deploying)" section. Fail-open audit, LLM-declared identity, single-tenant scoping, synthetic-id one-way-ness, all named, all with v2 fixes already designed. Shipping a demo that lies about what it is would have been easier.
- Repository interfaces that genuinely make v2 a swap, not a rewrite.
PolicyRepository,ConsentRepository, andAuditSinkare TypeScript interfaces. The v2 implementations arePgPolicyRepository,PgConsentRepository,PgAuditSink. The only file that changes iswiring.ts. Everything else (broker, engine, redactor, categorizer, tools, schemas) is untouched.
What we learned
The biggest lesson, and it's the kind of thing that sounds obvious once you say it: agents only get two knobs on platforms like Prompt Opinion: the system prompt and the attached tools. No custom headers, no pre-prompts, no minted JWTs. Once I internalized that, the design crystallized: role and purpose have to enter the broker as zod-constrained tool arguments declared by the LLM. And the moment you accept that, you have to be honest with yourself: in v1, you are trusting the LLM's word for who it is. That's a real, documented gap, and the post-MVP fix is signed identity attestation. Naming the gap clearly is part of the deliverable.
I also got a much sharper feel for how much work the boundary between "explanation to the LLM" and "audit row to disk" is doing. The LLM gets a friendly summary it can narrate to a user ("1 condition was removed due to patient consent"). The audit row gets the structured truth: matched rule ids, applied consent ids, fields removed, fields transformed, an audit UUID. Same decision, two audiences, and keeping them distinct is what makes the system both helpful and defensible.
On the FHIR side, the categorizer work taught me that "sensitive data" isn't a property of a field name, it's a property of a code. You can't redact mental-health data by looking for the word "depression"; you have to recognize SNOMED 35489007 in a Condition's coding array. The category-mapping file is small today, but the shape is right: this is the kind of thing a clinical informaticist should be able to edit without a deploy.
And finally, building this against the SHARP/MCP/FHIR stack reinforced how much leverage you get from working with standards rather than around them. The x-fhir-server-url and x-fhir-access-token headers Prompt Opinion already propagates meant I never had to invent a credential story. The MCP transport gave me a typed tool contract for free. The Bundle structure on the FHIR side meant the Redactor's per-entry filtering was a natural operation rather than a special case.
What's next for MediGate
The roadmap fell naturally out of the v1 design, and every item lands without touching the broker itself:
- Web portal for compliance officers to edit policies, consent records, and category mappings; the repository interfaces are already in place.
- Database-backed repositories swapped in behind those same interfaces. One change in
wiring.ts, broker code untouched. - Signed identity attestation so role and purpose stop being LLM-declared and become non-repudiable claims verified against a token from the platform.
- Multi-tenant scoping: a
tenantIdon the broker context and on every rule, so one MediGate instance can serve many organizations with isolated rulesets. - Fail-closed audit: no data leaves the broker until the audit row is durably written.
- A real category vocabulary sourced from a terminology service rather than a hand-curated JSON, so substance-use, genetic, HIV-status, and other sensitive categories get the same first-class treatment mental-health gets today.
- Deterministic synthetic-id resolver inside the broker, so research agents can chain
FindPatientId → GetPatientSummarywithout losing reachability while keeping the one-way property at the edges.
The bigger thesis MediGate is trying to demonstrate is that healthcare AI agents don't fail safely by default, and the place to fix that is in the plumbing, not the prompt. Same MCP server, same FHIR backend, different agents, different views, governed by data, audited end to end, defensible to compliance. That's the last mile, and it's worth building once, so every agent in the marketplace gets it for free.
Built With
- gcp
- node.js
- zod

Log in or sign up for Devpost to join the conversation.