MediFusion AI — AI Voice Doctor Powered by ElevenLabs + Google Cloud Vertex AI
Inspiration
In many regions, patients experience long waiting times and challenges accessing healthcare due to limited medical resources. We wanted to build an intelligent system that enables fast, voice-driven medical interaction. MediFusion AI bridges the gap between patients and doctors using real-time speech understanding, medical reasoning, and disease prediction.
What it does
MediFusion AI is an AI Voice Doctor that allows users to talk naturally and get intelligent, medically relevant responses. It:
- Listens to patient speech using Whisper + ElevenLabs STT with noise reduction
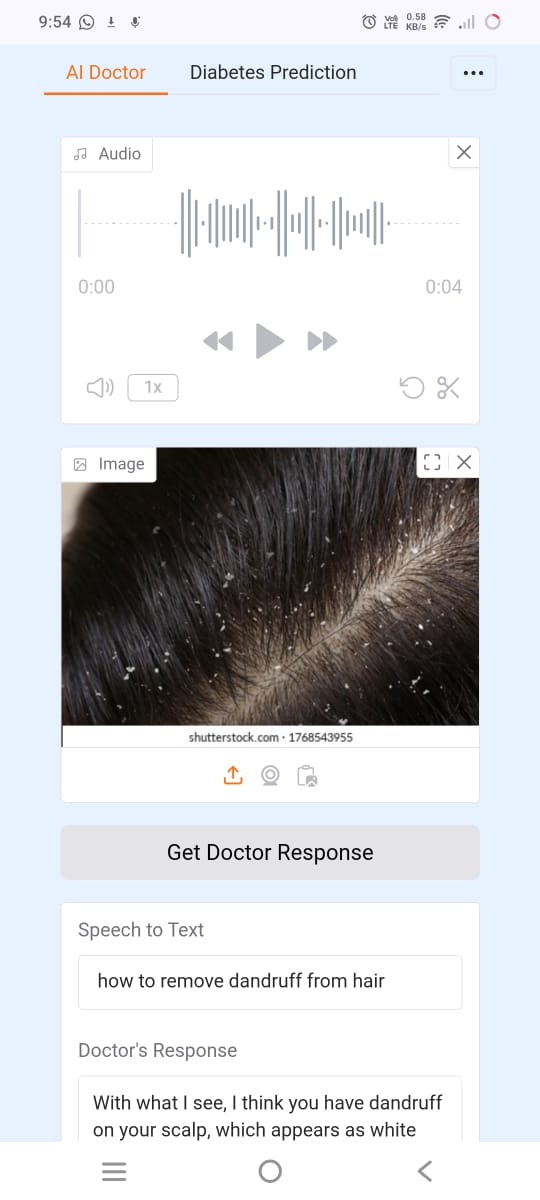
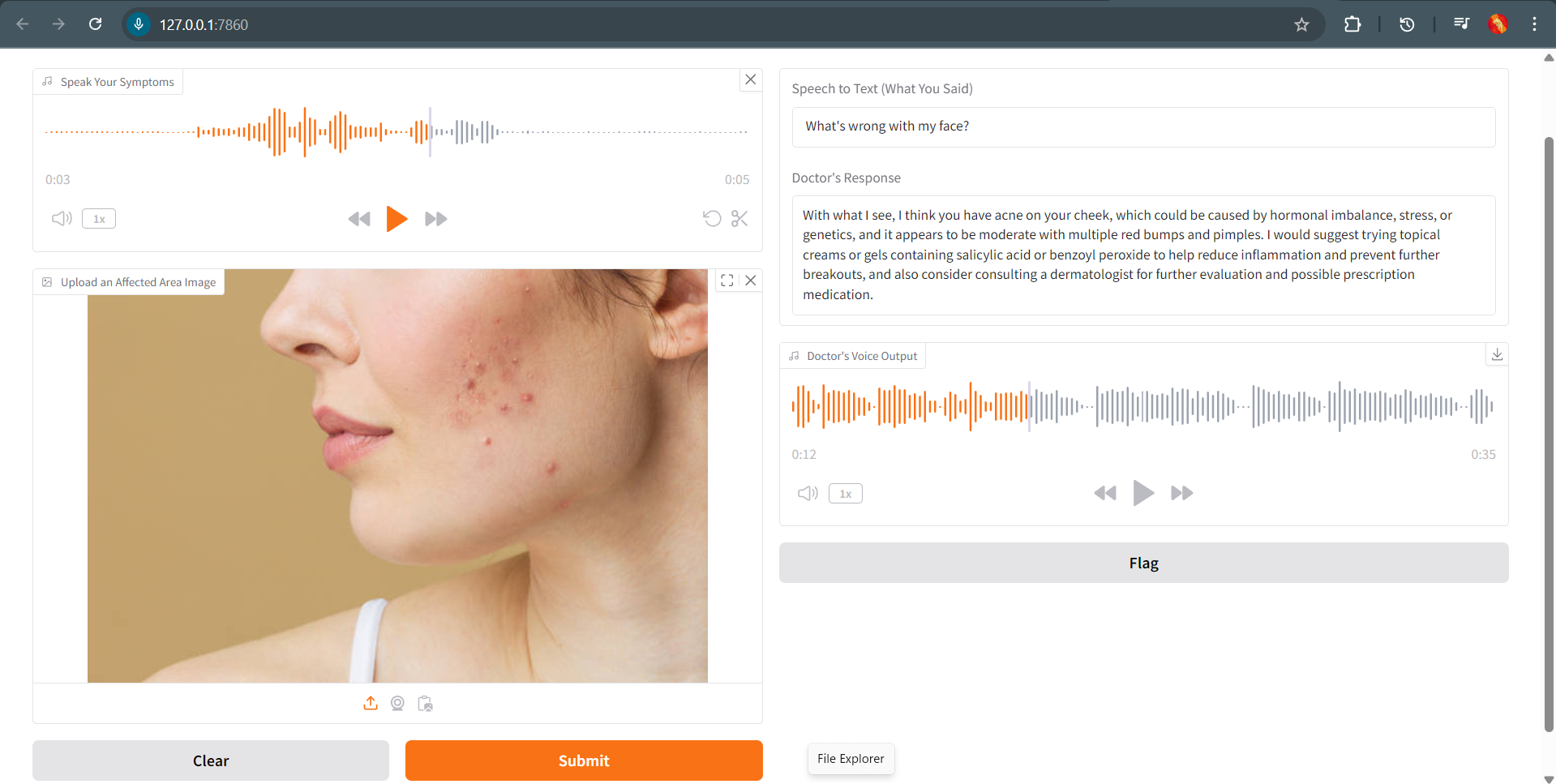
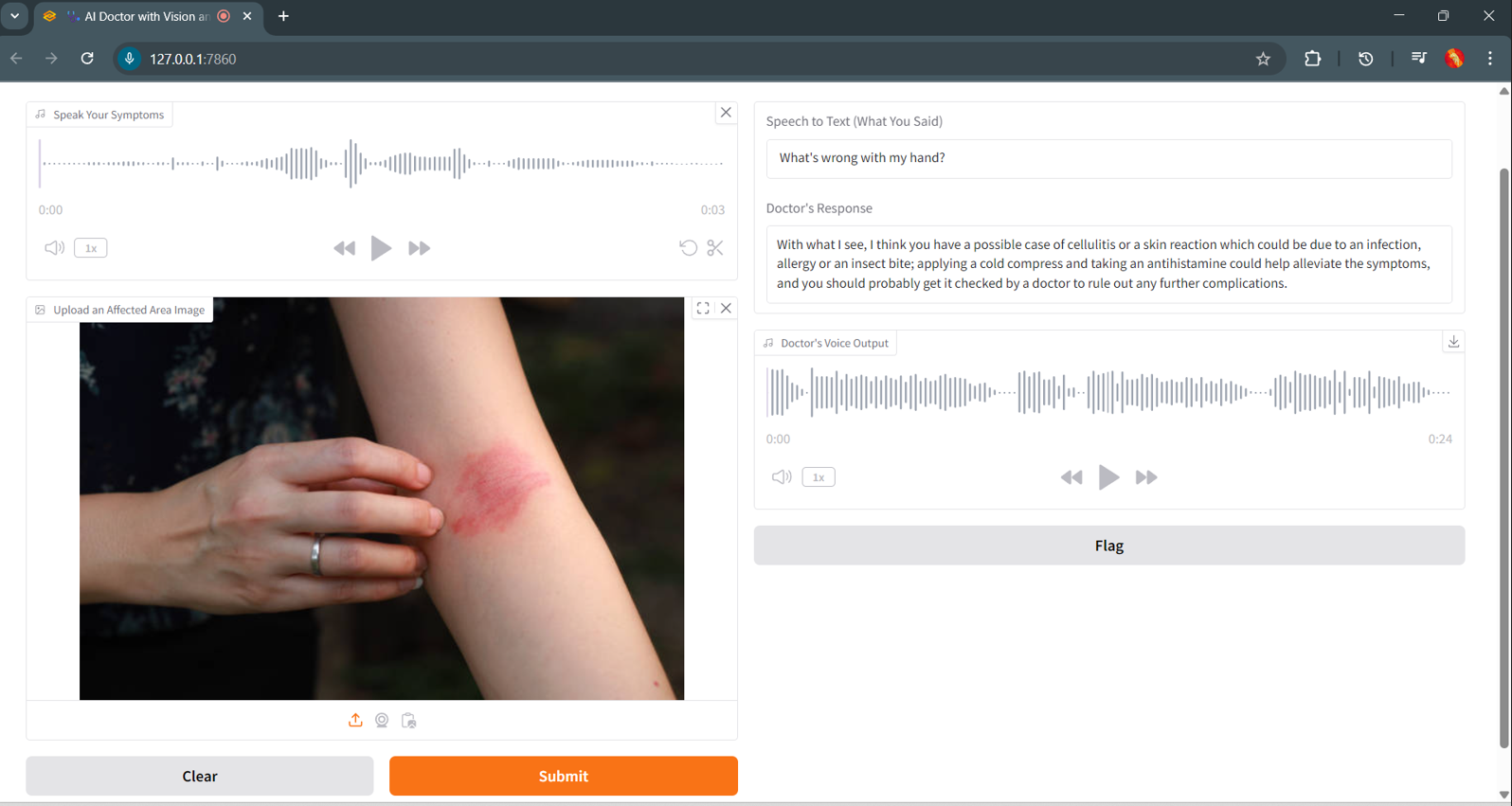
- Analyzes symptoms and medical images using Google Cloud Vertex AI + LLaMA 3 Meta Vision (Groq API)
- Responds like a human doctor using ElevenLabs TTS for natural medical voice output
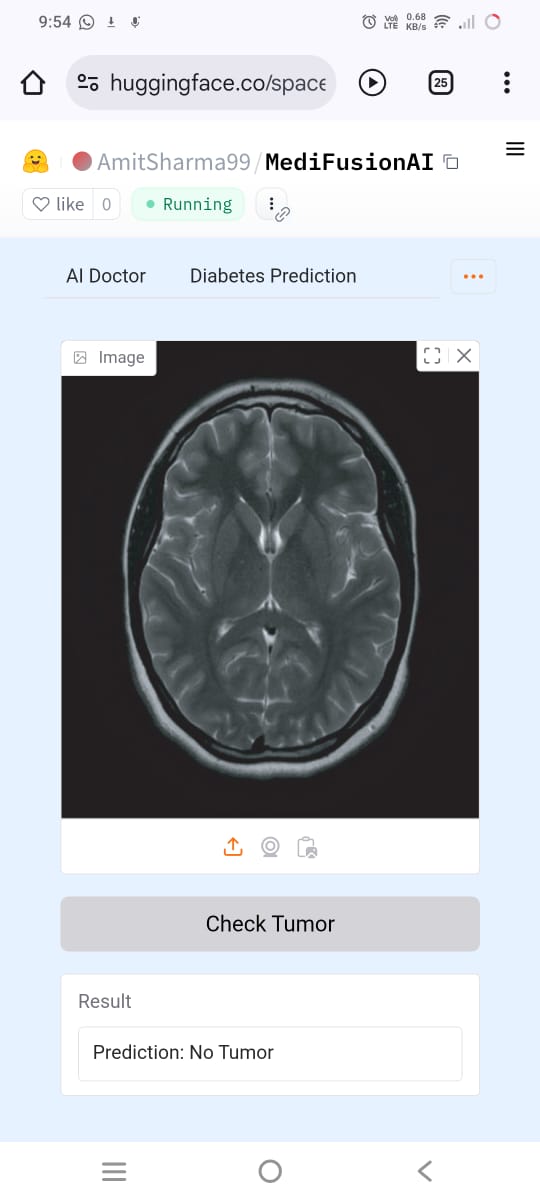
- Predicts diseases using ML models for Diabetes, Tumor Detection, and Heart Disease
- Provides a fully voice-based consultation through a Gradio conversational UI
Key Features
- Voice-driven healthcare consultation
- Real-time multimodal LLM (Vision + Voice + Text)
- Medical image analysis using LLaMA Vision
- ML-based disease prediction (Diabetes, Tumor, Heart)
- Natural conversational doctor voice using ElevenLabs TTS
- Lightweight responsive UI with Gradio
Tech Stack
| Category | Tools |
|---|---|
| Cloud AI | Google Cloud Vertex AI, Gemini, Groq API |
| Voice AI | ElevenLabs STT & TTS, Whisper, gTTS, Google Speech-to-Text |
| LLM | LLaMA 3 Meta Vision |
| Frontend | Gradio |
| ML Models | Diabetes, Heart Disease, Tumor CNN |
| Deployment | Streamlit / Hugging Face / Google Cloud Run |
| Languages | Python, NumPy, OpenCV, ONNX |
How we built it
Phase 1 — AI Brain
- Integrated Google Cloud Vertex AI + Groq LLaMA 3 Vision for reasoning and image analysis
Phase 2 — Voice of the Patient
- Built noise-filtered voice recording
- Speech transcription using Whisper + ElevenLabs STT + Google Speech-to-Text
Phase 3 — AI Doctor Voice
- Response synthesis using ElevenLabs TTS and gTTS for natural voice output
Phase 4 — Disease Prediction Engine
- Integrated ML & DL models: Diabetes, Tumor (CNN), and Heart Disease
Phase 5 — Real-Time UI
- Built a real-time Gradio VoiceBot interface for full speech interaction
Challenges
- Managing latency between multimodal model and speech generation
- Synchronizing STT, reasoning, TTS, and UI in real time
- Handling noisy audio input and transcription accuracy
Accomplishments
- Real-time voice-based intelligent medical consultation system
- Integrated ElevenLabs + Google Cloud + Groq multimodal AI successfully
- Achieved smooth, natural conversational experience
What we learned
- Multimodal AI systems (Vision + Voice + ML)
- Cloud deployment and real-time inference pipelines
- Building scalable conversational AI healthcare solutions
What’s next
- Multilingual voice consultation
- Medical reports + symptom history tracking
- Mobile app version and Firebase integration
- End-to-end patient analytics dashboard
What Makes MediFusion AI Unique
MediFusion AI delivers a fully conversational healthcare experience using advanced voice technologies from ElevenLabs combined with multimodal AI reasoning. Users interact entirely through speech, making medical assistance fast, accessible, and natural. The system understands symptoms, provides guidance, and responds in real time—creating a seamless, human-like healthcare interaction for everyone.
Submission Link
🔗 GitHub Repository (Source Code):
https://github.com/amit-sharma-ds/GenAIDoctor
Built With
- deep-learning
- docker
- elevenlabs
- ffmpeg
- gradio
- groq
- groq-cloud
- gtts
- huggingface
- llama-3-vision
- machine-learning
- openai-whisper
- pyaudio
- python
- speech-to-text
- vs-code








Log in or sign up for Devpost to join the conversation.