
Inspiration
In the midst of your medical emergency, you rush into the ambulance. The nurse immediately asks about your current symptoms and medical history. You quickly relay the information, hoping for swift help. In the ER waiting room, another nurse approaches and you find yourself repeating the same details. Finally, a doctor comes to you, yet again inquiring about your symptoms and history. Frustrated, you realize you've stated the same facts three times. In a world where every second in medicine counts, this repetition feels like precious time wasted. You can't help but think, in emergencies, saving time means saving lives.
What it does
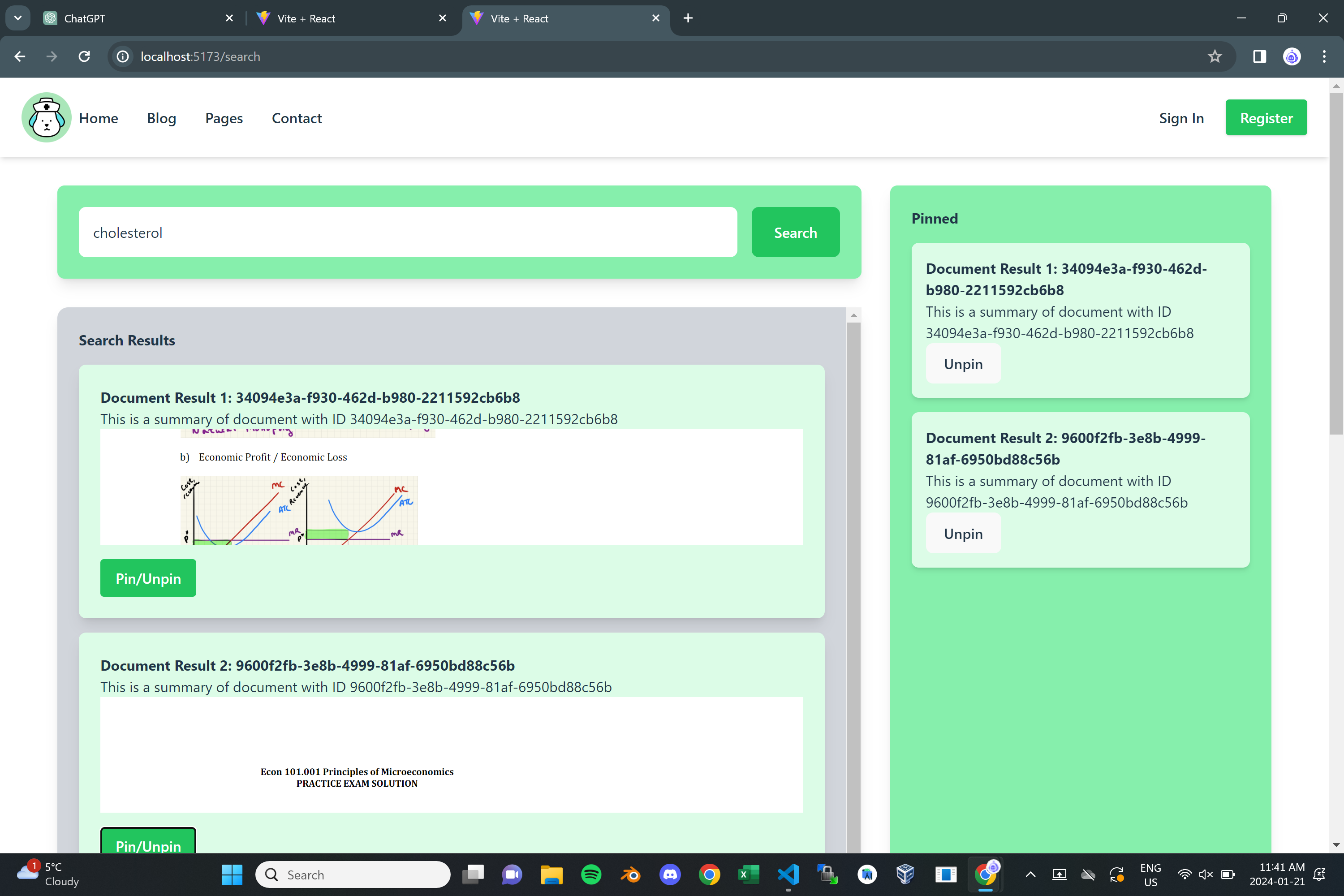
MediFetch AI revolutionizes patient care by streamlining the way medical professionals access and understand a patient's medical history. By utilizing advanced NLP technology, this platform allows users to submit their medical documents, which are then efficiently processed and organized. When a healthcare professional needs specific information, MediFetch AI queries these documents and displays the most relevant sections, tailored to the query. This innovative approach not only consolidates a patient's health history into one accessible location but also significantly reduces the time healthcare providers spend sifting through extensive medical records. With MediFetch AI, medical professionals can quickly grasp a patient's medical background, ensuring faster and more effective care.
Example: A doctor treating a patient with shortness of breath and a history of heart issues might enter the following query into MediFetch AI: "Patient's history of cardiac conditions and recent treatments." Returns PDF chunks consisting of:
- Diagnosed with Atrial Fibrillation in 2021
- Underwent angioplasty in 2022
- Prescribed beta-blockers in March 2023
- Last Echocardiogram showed mild left ventricular hypertrophy in December 2023
How we built it
Frontend:
React, Tailwind
Backend/ML:
Firebase, Flask, Pinecone, BERT
How it works:
When a document is uploaded, the text is segmented and each section is converted into an embedding using BERT. These embeddings capture the contextual meaning of the text. The system then stores these embeddings in a Pinecone index, allowing for efficient retrieval. When a query is made, it's also converted into an embedding and matched against the index to find the most relevant document sections, streamlining access to pertinent medical information.
Challenges we ran into
There were a lot of challenges all-around, but the hardest was having an effective embedding system. Currently, our model is not as effective in retrieving the most relevant chunks in pdfs, and due to the similarity threshold, may output no pdfs if the submitted files are not extensive.
What's next for MediFetch AI
Fine tune the model's effectiveness and launch for use.

Log in or sign up for Devpost to join the conversation.