-
-
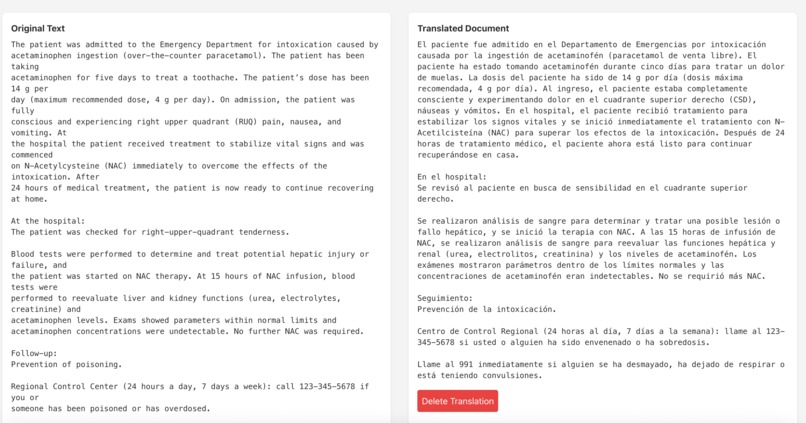
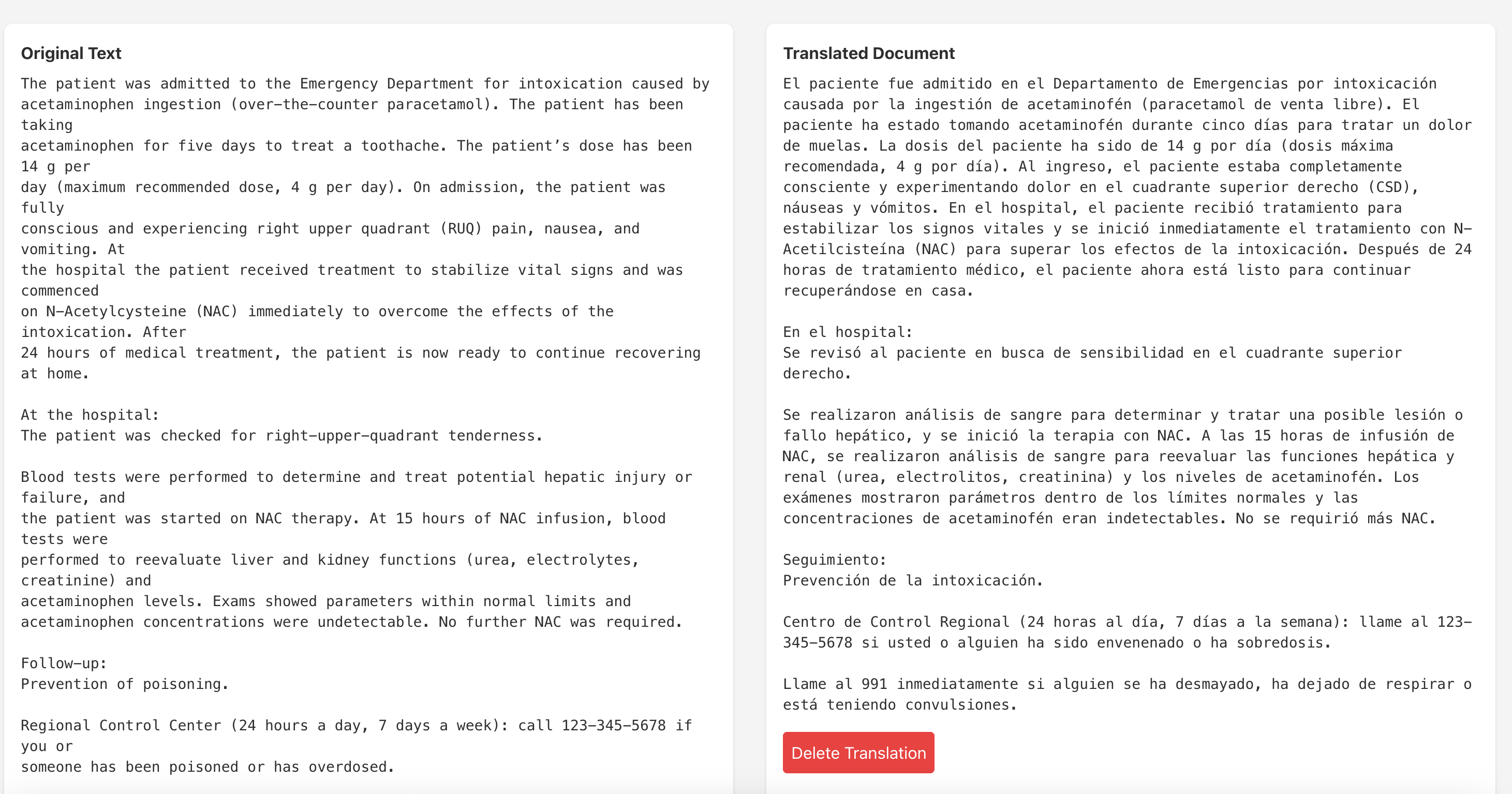
Extracted Text and Translation
-
The website interface
Inspiration
Every year, millions of patients around the world leave hospitals with discharge instructions they can’t fully understand — often written in a language they don’t speak fluently or filled with medical jargon that even native speakers find confusing.
- Language barriers lead to medication errors, missed follow-up care, and avoidable complications.
- Existing translation tools like Google Translate lack domain accuracy, misinterpreting critical medical terms or omitting context.
- Privacy concerns prevent patients from uploading sensitive documents to unverified online platforms.
There is a clear need for a secure, accurate, and patient-centered solution that democratizes access to medical documentation across languages.
What it does
MediDoc Translate bridges this accessibility gap through a fully automated medical translation pipeline that integrates Optical Character Recognition (OCR), domain-verified Large Language Models, and a medical terminology knowledge base.
- Upload & OCR: Users upload a photo or PDF of their medical document. The system extracts text using OCR fine-tuned for healthcare documents.
- Medical Context Engine: The text passes through the MCE, which retrieves relevant medical definitions and terminology mappings from a curated medical knowledge base to ground the translation process.
- Translation & Simplification: The LLM produces both (a) a clinically accurate translation and (b) a simplified, patient-friendly summary for clarity.
- Privacy by Design: No document or extracted text is stored; all processing occurs securely and transiently.
Through this approach, MediDoc Translate transforms opaque, jargon-filled paperwork into accessible health guidance — empowering patients, supporting caregivers, and enabling hospitals to provide equitable post-discharge communication at scale.
How we built it
Frontend (React + Tailwind): Built a responsive web app for PDF/image upload and bilingual translation viewing using React and Tailwind. Axios handles secure API communication.
Backend (FastAPI): Developed an async REST API that coordinates OCR, translation, and summarization pipelines efficiently.
OCR & Preprocessing: Integrated Tesseract and PaddleOCR for extracting text from printed and handwritten medical documents with denoising and language detection.
Medical Context Engine (MCE): Designed a domain-aware retrieval layer using Sentence-Transformers and ChromaDB to fetch verified medical definitions and ensure translation consistency.
Translation & Summarization: Used OpenAI/Anthropic LLMs for translation and simplification, with DeepL as fallback. Ensures medical terms and dosages remain accurate.
Privacy & Security: All data is processed transiently in memory—no storage or external logging. Fully HIPAA-safe and privacy-by-design.
Open-Source & Extensible: Modular, open-source architecture allows hospitals and developers to integrate new languages or medical term packs easily.
Challenges we ran into
OCR Accuracy on Poor Quality Images Problem: Handwritten or low-quality scans might have poor OCR accuracy. Solution: Implement image preprocessing (rotation correction, contrast enhancement, noise reduction). Provide user feedback if confidence is low and suggest re-uploading.
Large Document Processing Time Problem: Long documents might take too long to process, causing timeouts. Solution: Implement async processing with status polling. Show progress indicators. Break documents into pages and process incrementally.
Finding Good Sources of Medical Documentation Problem: Online medical documentations and definitions are not often standardized. Solution: Compiled our own source of 571 medical abbreviations and medical terms for embedding in our vector database.
Accomplishments that we're proud of
- Built a fully functional end-to-end pipeline — from OCR to translation to patient-friendly summaries.
- Developed a custom Medical Context Engine (MCE) that grounds translations in verified medical terminology.
- Achieved accurate, context-aware translations across multiple languages while preserving clinical meaning.
- Designed a privacy-safe architecture — all processing is transient, with no data stored or logged.
- Created an intuitive React frontend for uploading and viewing medical documents side-by-side in bilingual form.
What we learned
How to combine OCR, retrieval-augmented generation, and translation models into one cohesive workflow.
The importance of medical domain grounding to prevent LLM hallucinations or misinterpretations.
Techniques for building HIPAA-safe AI pipelines with transient in-memory data handling.
Balancing accuracy vs. simplicity when explaining complex medical terms to patients.
How interdisciplinary collaboration between medical, linguistic, and AI perspectives leads to better user outcomes.
The value of iterative testing with real-world documents to improve OCR accuracy and translation reliability.
What's next for MediDoc Translate
Immediate Next Steps
- Release the platform as open-source
- Expand medical terminology database to 1000+ terms
- Add support for 10+ languages
- Mobile app (React Native)
Long-term Vision
- Hospital EMR integration
- Medication reminder system
- Making documents more interpretable for laypeople
- Multi-modal input (voice + image)
- FDA/HIPAA compliance
- Partnership with healthcare providers
Built With
- chromadb
- deepl
- fastapi
- ocr
- openai
- react
- tailwind


Log in or sign up for Devpost to join the conversation.