-
-
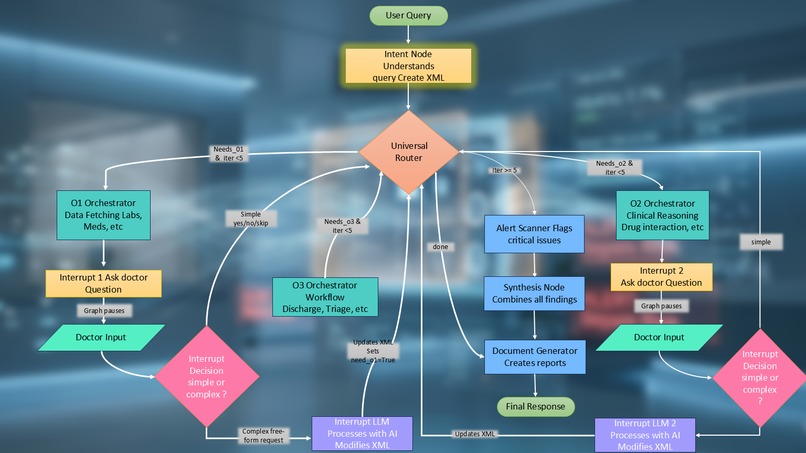
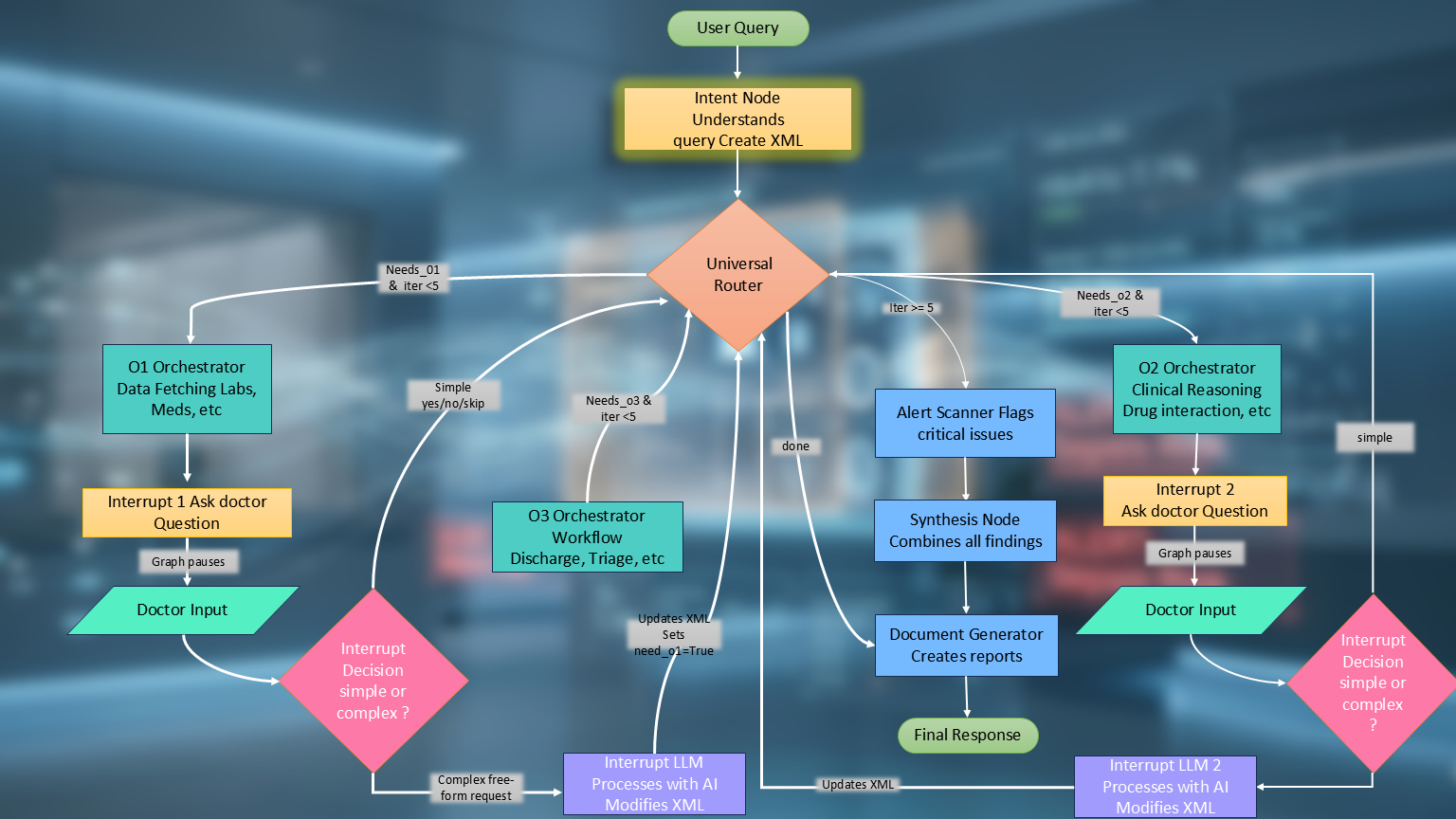
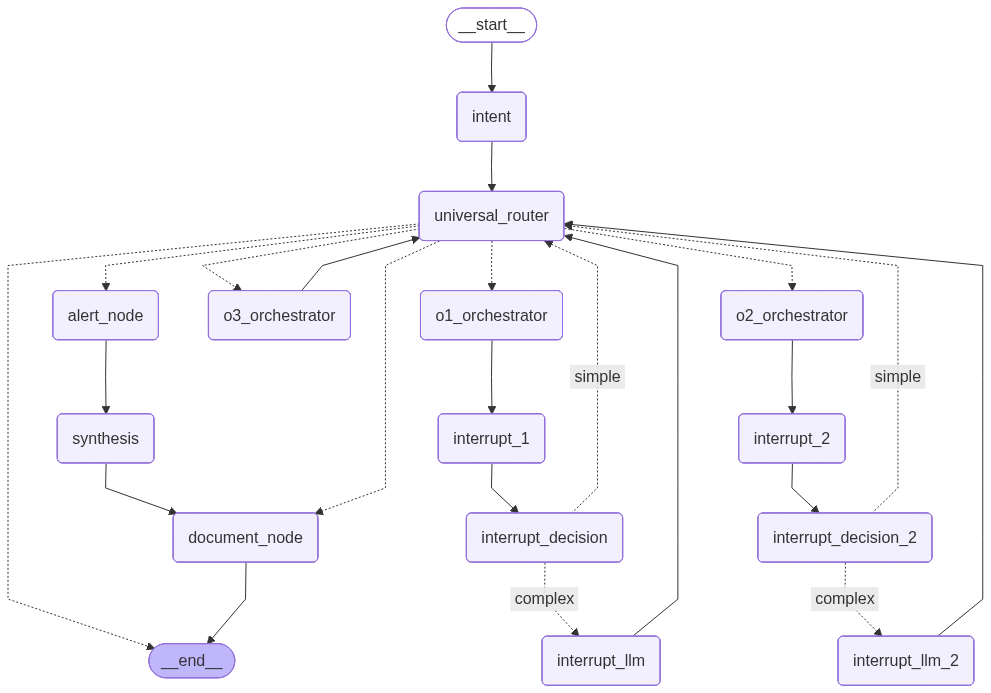
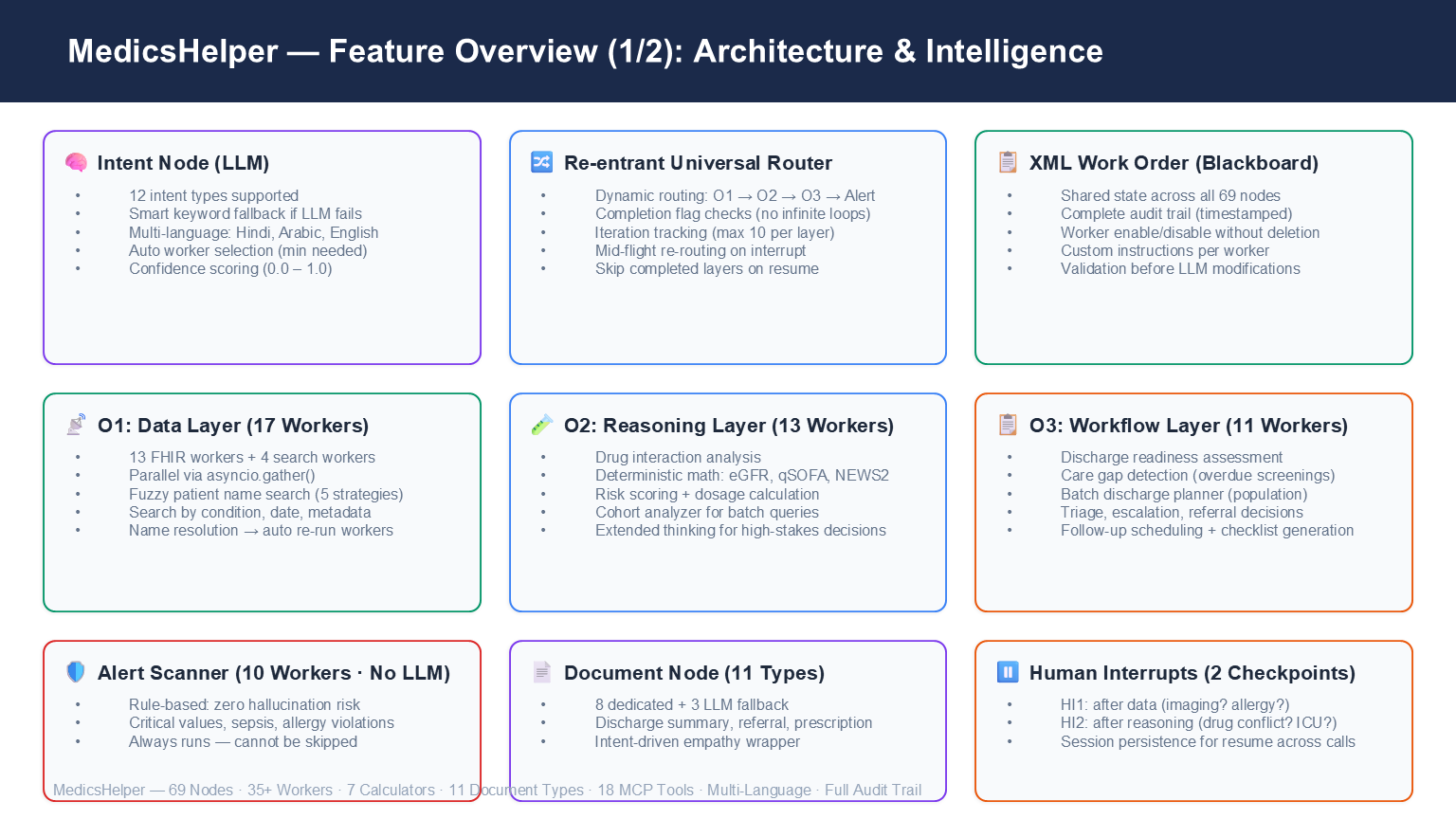
Full node map — Intent, Router, O1/O2/O3 layers, Alert Scanner, Document Node, 2 Human Interrupts.
-
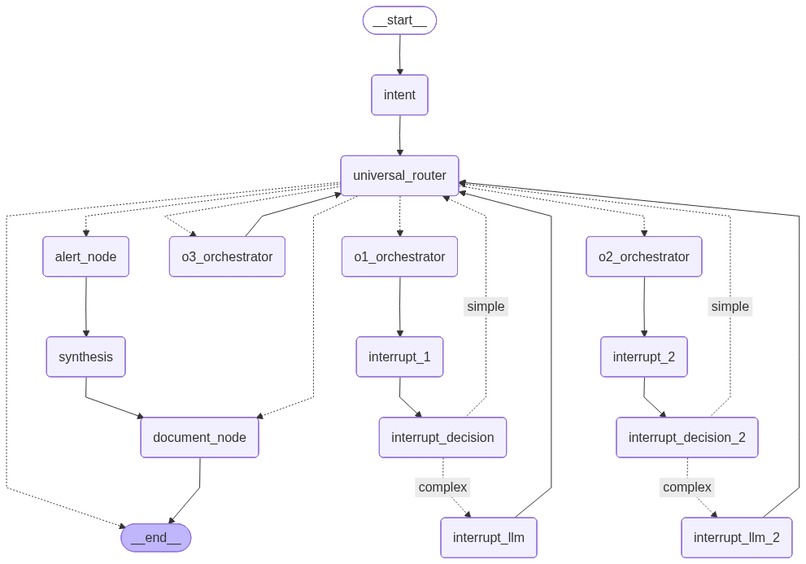
-

18 MCP tools. One triggers the full 69-node pipeline. 17 handle direct FHIR queries. One query does it all.
-
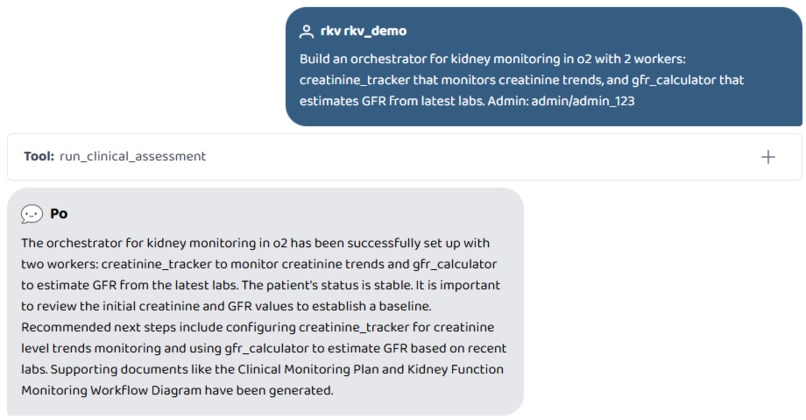
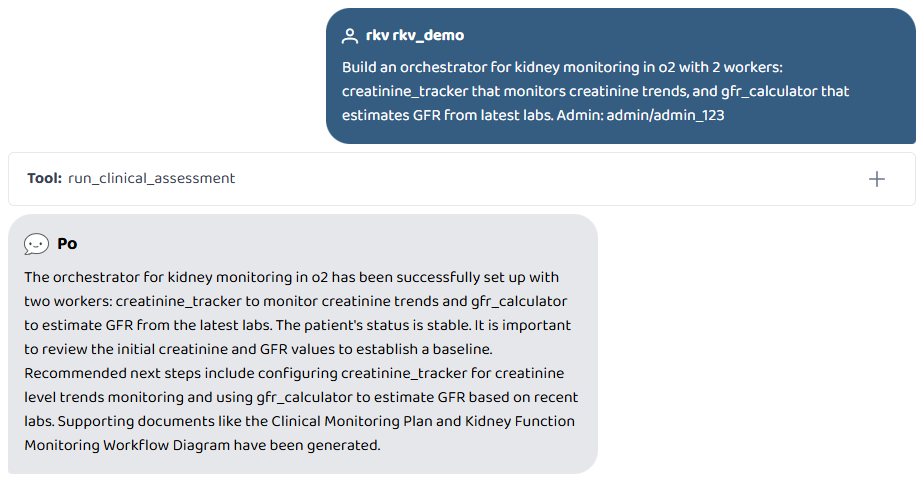
Build an orchestrator for kidney monitoring in o2 with 2 workers
-
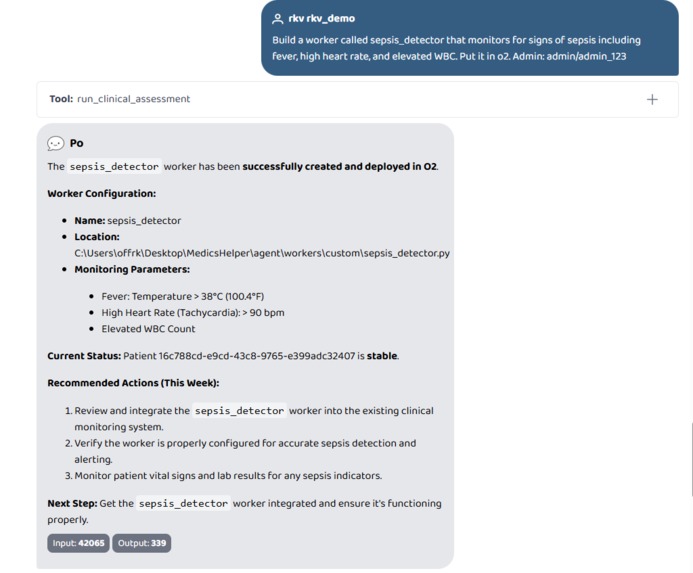
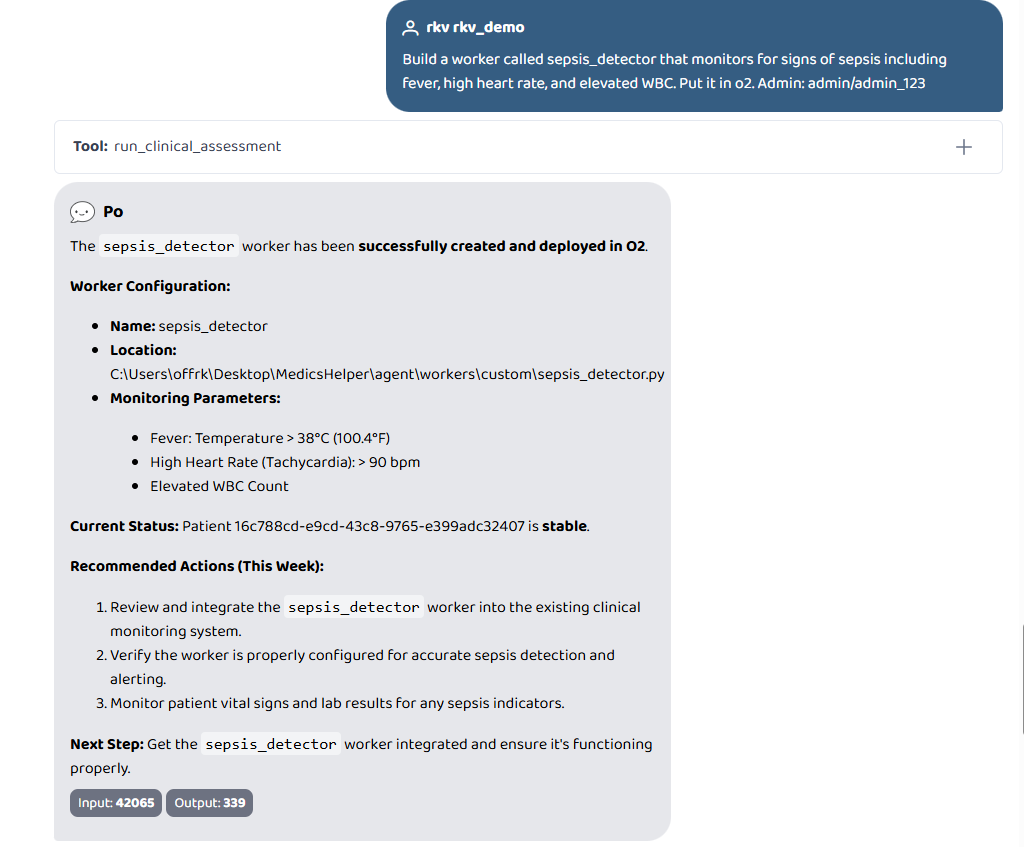
Build a worker called sepsis_detector that monitors for signs of sepsis including fever, high heart rate, and elevated WBC. Put it in o2.
-

-

One question. Full chart review. NOT SAFE FOR DISCHARGE — opioid accumulation risk caught in seconds.
-

Human interrupt in action. System pauses mid-analysis to confirm a critical drug finding before proceeding.
-
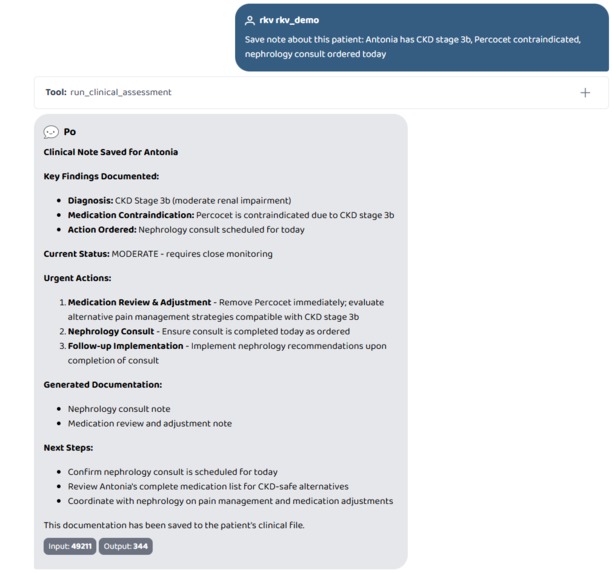
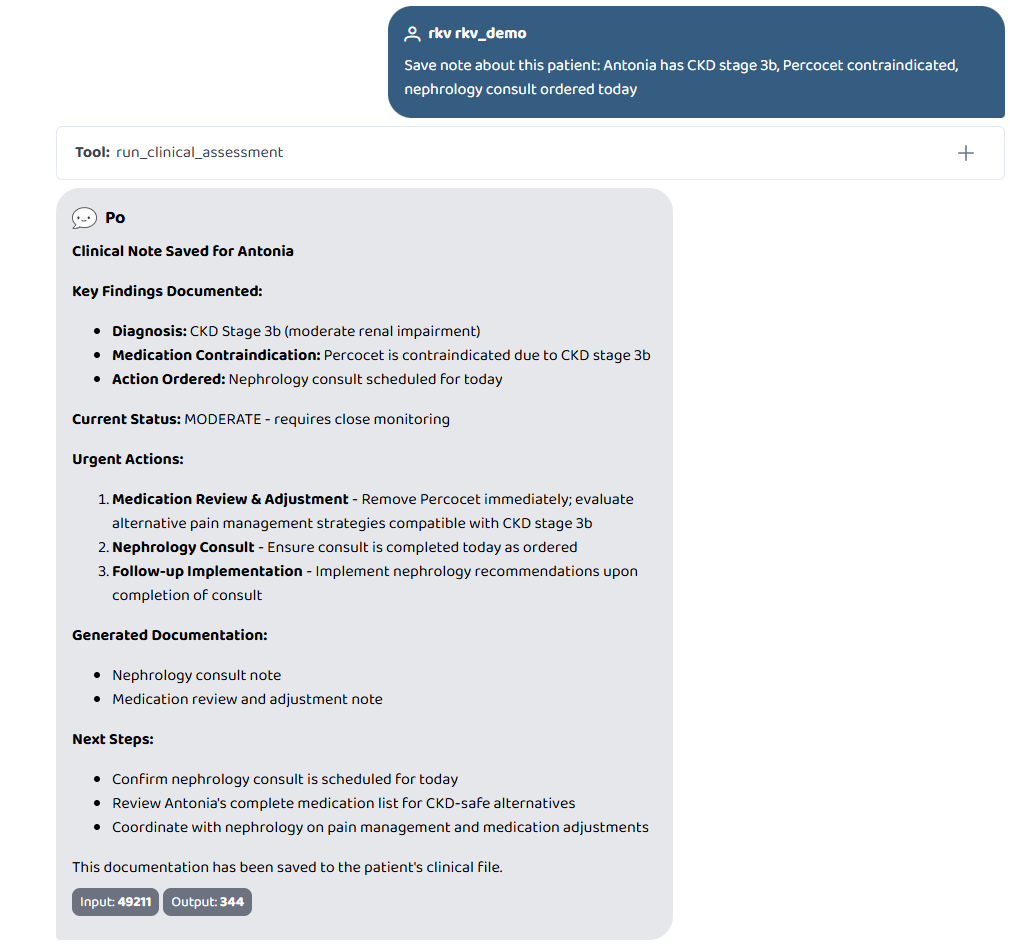
Save note about this patient: Antonia has CKD stage 3b, Percocet contraindicated, nephrology consult ordered today
-
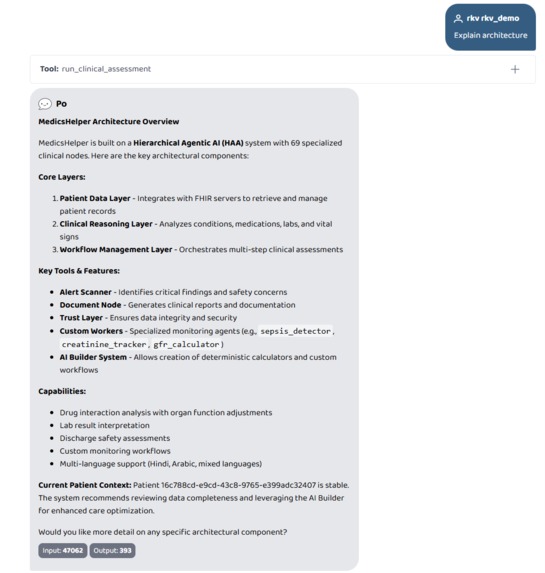
-
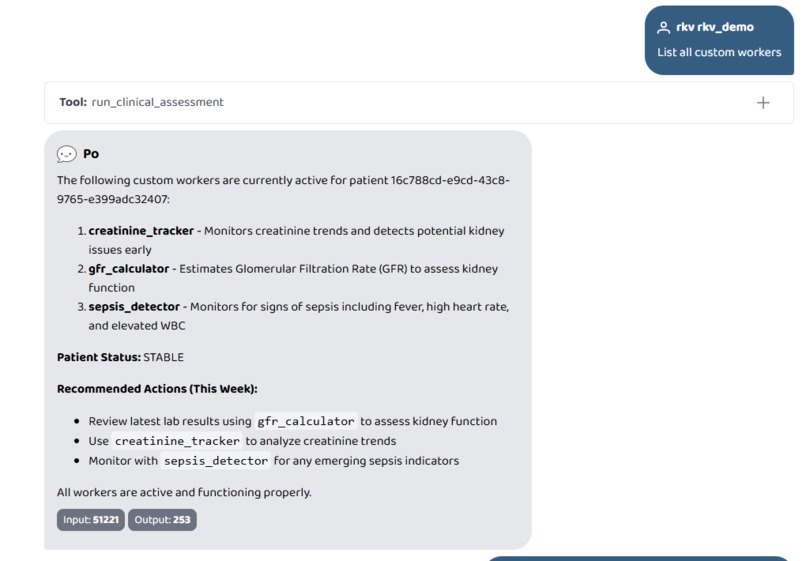
-

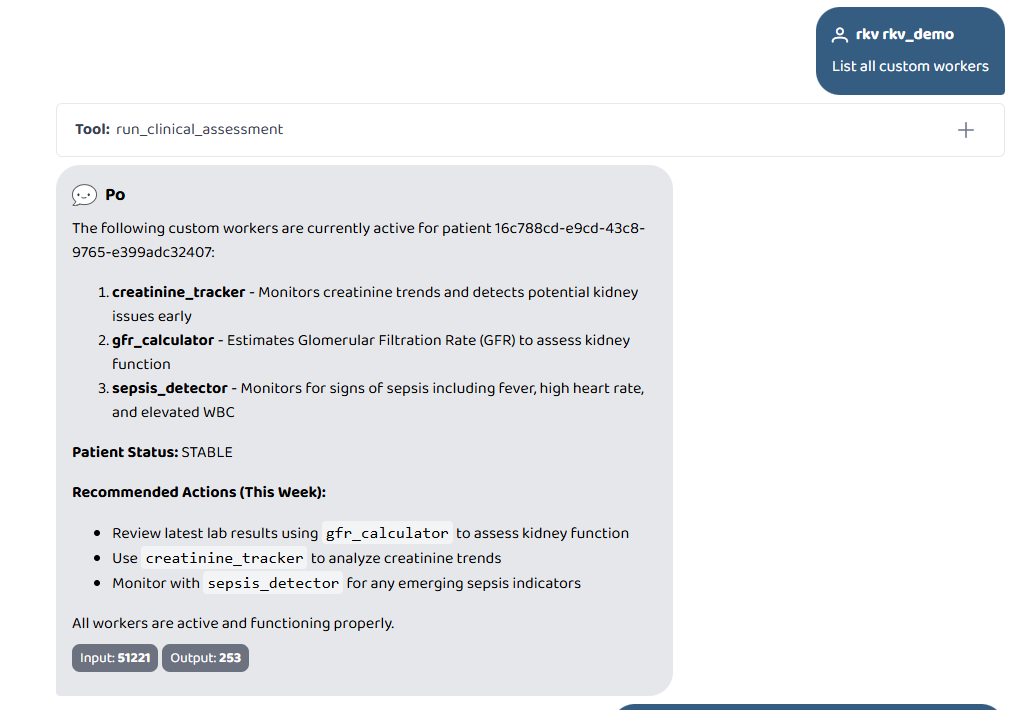
List all custom workers
-

-

43 conditions. 6 critical flags. Opioid risk, CKD, polypharmacy — all surfaced from one plain-English query.
-

Percocet contraindicated in seizure disorder. System flags it, explains why, and asks doctor to confirm.
-

Doctor confirms. System resumes — full action plan, contraindication table, lab orders, and documents generated.
-
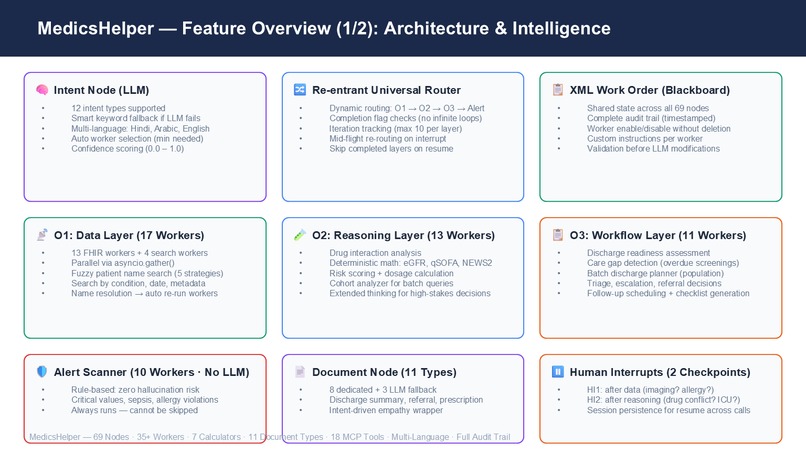
Session persistence, graceful degradation, 7 deterministic calculators, fuzzy search, empathy wrapper. Built for production.
-

-

One query triggers a 6-stage pipeline. Re-entrant router allows mid-flight changes. Clinical math is Python — LLMs interpret only.
-

17 parallel O1 workers. All fire simultaneously via asyncio. Fetch time = slowest worker, not sum of all.
-

O2 — 12 LLM clinical specialists: drug interaction, risk scoring, dosage calc, trend analysis, differential diagnosis, prognosis.
-

O3 answers "what next?" — triage, discharge, referral, escalation. Clinical reasoning into concrete actions.
-

7 calculators, pure Python — eGFR, qSOFA, CURB-65, NEWS2, CHA2DS2-VASc, HAS-BLED, BMI. Numbers guaranteed correct. LLMs interpret only.
-

5 alerts fired for Antonia — creatinine critical, Percocet contraindicated, CKD trend rising. Runs on every query. Cannot be skipped.
-

Alert: 11 rule-based workers, zero LLM. Document: 9 specialists — discharge notes, referrals, prescriptions. O1 data. O2 meaning. O3 action.
-
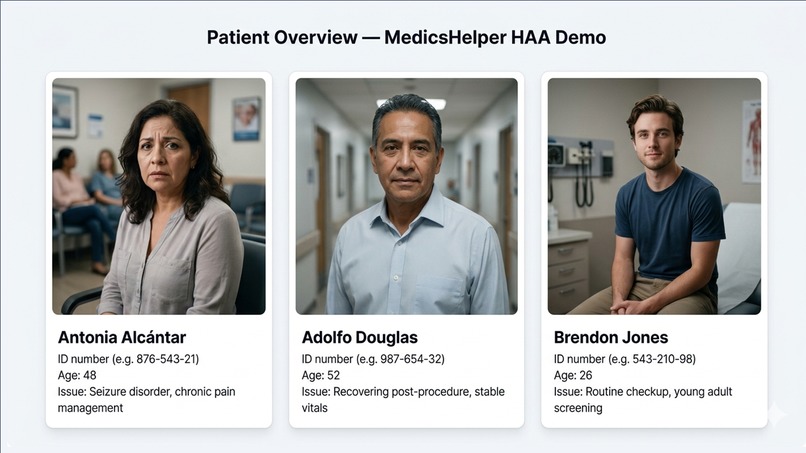
Three demo patients across complexity levels. Antonia exercises every layer of the system.


















MedicsHelper — Devpost Submission Story
Inspiration
A doctor has roughly 2 minutes per patient during a busy ward round. In those 2 minutes, they are expected to review a full chart, check for drug interactions, assess discharge readiness, catch critical lab values, and document everything — across dozens of patients, back to back.
Clinical AI today doesn't solve this. It either fetches data or answers questions. Nothing reasons across labs, medications, and conditions simultaneously. Nothing catches what the doctor missed and then acts on it. The tools that exist are either passive information retrievers or narrow single-purpose chatbots.
The inspiration was simple: what if a doctor could type one plain-English question and get back a response that felt like a senior colleague had just reviewed the full chart, flagged every risk, and handed over a structured plan — in under 45 seconds?
That question became MedicsHelper.
What It Does
MedicsHelper is a 69-node hierarchical agentic AI system for clinical decision support. A doctor types one question in any language. The system:
- Reads the patient's full chart via live FHIR R4 — labs, medications, conditions, vitals, allergies, imaging, appointments, procedures — fetched in parallel across up to 17 specialized data workers
- Reasons clinically across all of that data simultaneously — drug interactions, risk scoring, dosage safety, trend analysis, prognosis, complication detection — using 12 dedicated LLM-powered reasoning workers
- Decides workflow actions — discharge readiness, referrals, escalation, care gaps, follow-up scheduling — via 10 workflow workers
- Scans for critical values using an always-on alert scanner with 10 rule-based workers that run on every query, zero LLM, zero hallucination risk
- Generates clinical documents — discharge summaries, referral letters, medication reconciliation, patient-facing explanations — via 8 document workers
- Returns a response that reads like a senior colleague talking, not a data dump
- Extends itself — via the AI Builder (O0), doctors or admins can define new monitoring workers in plain English. The system writes, registers, and loads them at runtime.
Antonia example: A 48-year-old patient with epilepsy, chronic pain, and Percocet. Creatinine came back at 2.9. The doctor asked one question: "Is it safe to discharge her today?"
MedicsHelper caught that her eGFR was 24 mL/min (calculated in pure Python via Cockcroft-Gault, not LLM math), that oxycodone accumulates dangerously at that kidney function, that her current dose was double the safe maximum, and that discharge would risk respiratory depression. It returned a structured hold recommendation, adjusted dosing plan, nephrology referral timeline, and full discharge summary — in 33 seconds.
How We Built It
The Core Architecture
The system is built on LangGraph StateGraph with a shared AgentState TypedDict. Every node reads from and writes to this state. The central innovation is the XML Work Order — a shared blackboard that every node in the pipeline reads and writes to. No node talks to another directly. This keeps the system loosely coupled and fully auditable.
<work_order>
<understanding>
<intent>discharge_assessment</intent>
<urgency>high</urgency>
</understanding>
<orchestrators>
<o1 status="complete" iteration="1">
<worker name="labs" status="complete" enabled="true"/>
<worker name="medications" status="complete" enabled="true"/>
</o1>
<o2 status="pending">
<worker name="drug_interaction" status="pending" enabled="true"/>
</o2>
</orchestrators>
</work_order>
The Re-entrant Router
The most technically significant piece is the Universal Router — a re-entrant hub that is called multiple times per query. The routing decision for each orchestrator follows three conditions:
route to O_N iff needs_oN AND NOT oN_complete AND iteration < MAX
When a doctor gives a mid-execution instruction like "actually, fetch only the kidney tests from the last 48 hours", the Interrupt LLM reads the current XML, modifies it (disables most workers, sets a time filter on the labs worker, resets o1_complete = False), and the router sends execution back to O1 for a focused re-run. Each orchestrator is limited to 10 iterations to prevent infinite loops.
This is what separates MedicsHelper from a simple sequential LangGraph pipeline. It's dynamic clinical reasoning, not fixed data fetching.
The Three Orchestration Layers
O1 — Patient Data (17 workers, no LLM): Fires all selected data workers in parallel via asyncio.gather(). Five workers complete in ~4 seconds versus ~20 seconds sequentially.
O2 — Clinical Reasoning (12 workers, LLM-powered): Each worker is a focused specialist — drug interaction checker, risk scorer, dosage calculator, trend analyzer, complication detector, differential diagnosis, prognosis estimator, and more.
O3 — Workflow (10 workers, mixed): Translates clinical findings into actionable decisions — discharge readiness, escalation, triage, referral, care gap detection, follow-up scheduling.
Clinical Math — Never LLM
All clinical calculations run through deterministic Python functions in calculations.py. LLMs interpret results; they never perform the arithmetic.
| Calculator | Formula |
|---|---|
| eGFR | Cockcroft-Gault: $\text{eGFR} = \frac{(140 - \text{age}) \times \text{weight}}{72 \times \text{SCr}} \times (0.85 \text{ if female})$ |
| qSOFA | $\text{qSOFA} = [\text{RR} \geq 22] + [\text{SBP} \leq 100] + [\text{GCS} < 15]$ |
| NEWS2 | Weighted composite of 7 physiological parameters |
| CURB-65 | 5-point pneumonia severity score |
| $\text{CHA}_2\text{DS}_2\text{-VASc}$ | Stroke risk in atrial fibrillation |
| HAS-BLED | Bleeding risk assessment |
FHIR Integration
The FHIR client reads /metadata on startup and auto-discovers all resource types, search parameters, and capabilities. It has been verified against the HAPI FHIR public server — 146 resource types discovered, $everything operation confirmed, 57 patient-linked resource types mapped. Compatible with any R4-compliant server: HAPI, Epic, Cerner, Azure, AWS.
MCP Integration with Prompt Opinion
The system exposes 18 MCP tools. One primary tool triggers the full 69-node pipeline. 17 direct FHIR tools handle targeted queries. The MCP server reads SHARP context from Prompt Opinion headers — FHIR base URL, access token, patient ID — injected automatically on every call. No manual configuration per query.
Graceful Degradation
Every critical path has a fallback:
| Component | Failure | Fallback |
|---|---|---|
| Intent Node LLM | API failure | Smart keyword parser (12 intent patterns) |
| O1 worker | FHIR timeout | Others continue; error summary returned |
| O2 worker | LLM failure | Exponential backoff, then partial results |
| Document worker | Not registered | _fallback_generate() via LLM |
| Synthesis LLM | Fails | _fallback_synthesis() from alert counts |
| XML parsing | Malformed | WorkOrder._empty() skeleton |
The pipeline never fully fails. Worst case is partial results with a clear error message.
Challenges We Ran Into
The re-entrant router was the hardest problem. Making a LangGraph graph that can route back to a previously completed node without creating infinite loops required careful iteration tracking at both the state level and the XML level. The solution was to track iterations in two places — AgentState fields and XML iteration attributes — and check both before routing.
Clinical math correctness. The temptation was to let the LLM calculate eGFR and other scores since it "knows" the formulas. But LLM arithmetic is unreliable, especially at edge cases — very low creatinine, pediatric weights, extreme ages. Every calculator had to be implemented as deterministic Python and tested against known clinical references.
Worker selection without running everything. Running all 35+ workers on every query wastes time and tokens. The Intent Node had to learn to select only the workers relevant to the query type. A drug interaction check doesn't need imaging workers. A population search doesn't need O1 at all. Getting this selection right required carefully designed prompting and a fallback keyword parser that could make reasonable selections without any LLM call.
Human interrupt session persistence. LangGraph interrupts work within a single execution, but Prompt Opinion calls the MCP server fresh each time. Maintaining interrupt state across separate API calls — so the system could pause, return a question, and resume exactly where it stopped — required explicit session state management outside the graph.
FHIR data variability. Real FHIR data is messy. Lab results have inconsistent coding. Medication records use different terminologies. Conditions appear in multiple coding systems. Every O1 worker had to handle missing fields, null values, and unexpected resource shapes without crashing the pipeline.
Accomplishments We're Proud Of
The re-entrant router works. Mid-execution plan modification — disabling workers, changing time filters, forcing re-runs — all works correctly with no infinite loops. This is genuinely novel in a hackathon project.
The clinical math is correct. eGFR, qSOFA, NEWS2, CURB-65, CHA₂DS₂-VASc, HAS-BLED — all implemented, tested against reference values, and integrated into the O2 reasoning layer. The system never hallucinates a number.
The alert scanner runs on every query. Not just when explicitly asked. It scanned Antonia's creatinine at 2.9, flagged it as critical independently of the O2 reasoning workers, and would have caught it even if every LLM call had failed.
The empathy wrapper makes the response feel human. The final response for Antonia doesn't read like a JSON dump. It reads like a colleague who just reviewed the chart and wants to talk you through it. That's a product decision as much as a technical one.
End-to-end tests pass on live FHIR data. Not mock data. Real patient records from the HAPI FHIR public server, three distinct clinical scenarios, all passing.
The Self-Modifying System (AI Builder — O0)
After the core pipeline was complete, we added one more capability that changed the system's nature entirely.
A doctor can type: "Build a worker called sepsis_detector that monitors fever, heart rate, and elevated WBC. Put it in o2. Admin: admin/admin_123"
What happens internally:
- Intent node detects ai_builder intent
- Universal Router bypasses O1/O2/O3 entirely — routes directly to O0
- Admin credentials verified against server environment variables
- LLM generates a Python worker body from a typed template
- Safety filter rejects subprocess, eval, exec, open() — unsafe code never reaches disk
- File written to agent/workers/custom/ with explicit UTF-8 encoding
- registry.json updated with name, layer, description, file path, active flag
- On the next O2 query: orchestrator reads registry, dynamically imports via importlib, fires sepsis_detector alongside the 13 default workers automatically
No code changes. No server restart. The running system extends itself through natural language.
Supported commands:
- Build worker X that does Y for o1/o2/o3
- Remove worker X (file deleted + registry entry removed atomically)
- Remove all custom workers (full reset in one command)
- List custom workers (no authentication required)
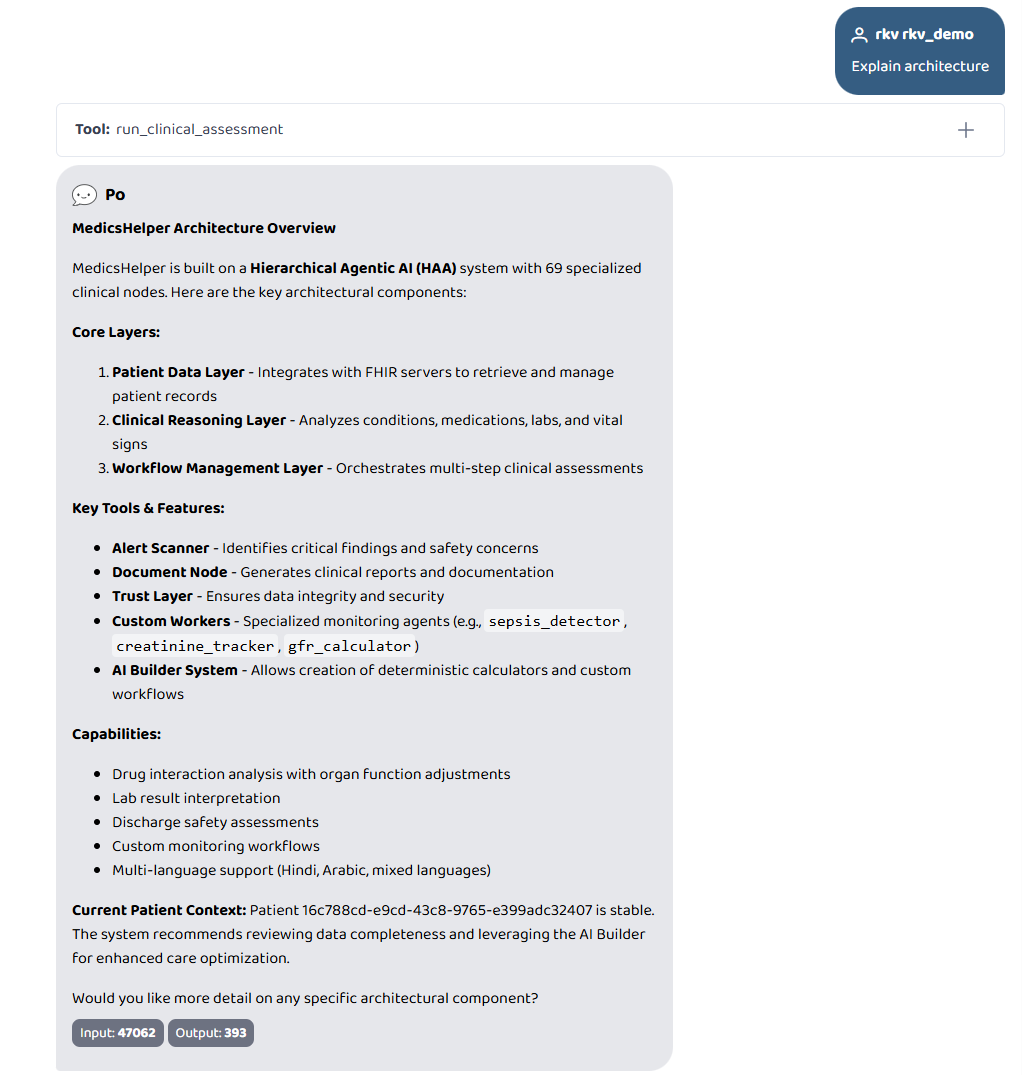
- Explain architecture (system self-describes all 69 nodes including any custom ones)
- Save note about this patient / Show notes (per-patient doctor notes, persisted to disk)
This makes MedicsHelper not just a fixed clinical AI but a self-extending platform. A children's hospital could say "build a worker that tracks weight-for-age z-scores for patients under 5." An ICU could say "build a worker that monitors lactate trends over the last 6 hours." A pharmacy could say "build a worker that checks formulary compliance for discharge medications." Each deploys into the live pipeline in seconds, isolated per hospital, without touching the core system.
The architecture supports this because the worker registry is just a JSON file and the orchestrators load workers dynamically at query time — not at startup. Adding a worker does not require recompiling the graph. The blackboard pattern means new workers read the same O1 data every other worker reads and write their results in the same format — no special integration required.
Screenshots of the full AI Builder workflow — build, list, remove, remove all, architecture explain, patient notes — are in the gallery above.
How MedicsHelper Thinks Differently
Most clinical AI systems are a single LLM call with a well-crafted prompt. The doctor's question, the patient's data, and the instruction to "reason clinically" all go into one context window. The model simultaneously fetches context, reasons clinically, checks safety, decides workflow, and generates documents — all in one pass.
The problem is fundamental: attention is split. A single model juggling 43 conditions, 40 medications, lab trends, drug interactions, dosage safety, discharge criteria, and document formatting in one inference call will miss things. And when it misses something, it misses silently. There is no intermediate checkpoint. There is no second opinion. There is no rule-based safety net catching what the LLM overlooked. The output looks confident regardless of whether it is correct.
MedicsHelper takes the opposite approach. Each clinical task is handled by a dedicated specialist worker. The drug interaction worker only checks drug interactions. The risk scorer only computes risk. The dosage calculator only verifies dosing. Each worker has one job, one system prompt, one scope of responsibility — and each worker's output is independently visible, traceable, and challengeable.
This is not a design preference. It is a clinical safety requirement.
For Clinicians Managing High-Acuity Patients
Consider a patient with epilepsy, chronic pain, Stage 4 CKD, and 40 medications. A single LLM might catch the obvious — "creatinine is high, be careful with opioids." MedicsHelper catches the non-obvious:
The dosage calculator computes eGFR at exactly 23.4 mL/min using Cockcroft-Gault — a Python function, not an LLM estimate. At that clearance, oxycodone's active metabolites accumulate. The current dose of 10mg is double the maximum safe dose of 5mg every 8 hours at this renal function.
The drug interaction worker connects this to epilepsy — opioids lower the seizure threshold. This patient is not just at risk of respiratory depression from opioid accumulation. She is simultaneously at increased risk of seizure breakthrough. These two risks compound each other in a way that checking them independently would miss.
The care gap worker notices that despite 43 active conditions and Stage 4 CKD, there is no nephrology referral in the chart. No one has asked a kidney specialist to review a patient whose kidneys are failing. That is a systemic gap — not a data point any individual lab value would reveal.
The alert scanner fires independently of all of this. Creatinine above 2.0 triggers a critical alert. Potassium at 5.04 triggers an urgent alert. These are rule-based Python threshold checks — zero LLM, zero hallucination, zero chance of being talked out of firing by an optimistic reasoning worker.
The synthesis node receives all of these findings — from workers that ran in parallel, each focused on one dimension — and produces a prioritized clinical summary. Critical findings first. Urgent second. Routine third. The doctor reads one line and knows the answer: do not discharge today.
This multi-specialist approach catches clinical chains that a single model cannot reliably detect. The oxycodone-to-eGFR-to-seizure-threshold chain requires connecting pharmacokinetics, renal physiology, and neurology. A generalist model might catch any one link. It is unlikely to catch all three and recognize that they compound each other. Three dedicated workers, each expert in their domain, catch all three — and the synthesis connects them.
For Those Building on Health Data Standards
The system does not assume what a FHIR server supports. On first connection, FHIRClient calls /metadata and parses the CapabilityStatement — mapping every resource type to its supported search parameters, operations, and record counts. When a worker needs laboratory results, it does not hardcode GET Observation?category=laboratory. It checks the capability map: does this server support the category parameter for Observation? If yes, use it. If no, fetch all observations and filter locally in Python.
This matters because FHIR servers vary significantly. HAPI FHIR exposes 146 resource types with full search parameter support. Prompt Opinion's internal FHIR server returns 422 on /metadata — it does not expose a CapabilityStatement at all. Epic, Cerner, and Azure each have their own subset of supported parameters and operations.
MedicsHelper handles all of these without code changes. For servers with full /metadata support, it uses the exact capabilities advertised. For servers without /metadata, it falls back to a minimal capability set of 57 standard R4 resource types with conservative search parameters. When a parameter is rejected at runtime — as happened with clinical-status on Prompt Opinion's Condition endpoint — the worker catches the error, drops that parameter, retries the broader query, and filters the results in Python. The system logged a warning and still returned all 43 active conditions for the patient.
The parallel fetch architecture matters for clinical completeness. When a doctor asks for a full assessment, 13 FHIR calls fire simultaneously via asyncio.gather — Patient, Observation (labs), Observation (vitals), MedicationRequest, Condition, AllergyIntolerance, Procedure, Encounter, ImagingStudy, Immunization, Coverage, DocumentReference, and DiagnosticReport. Total fetch time equals the slowest individual call — typically 3 seconds — not the sum of 13 sequential calls. This is the difference between a system that can afford to check everything and one that must choose what to skip.
FHIR write operations are also supported. The update_patient_demographics tool reads the current Patient resource, modifies the relevant fields, and PUTs it back with the proper Content-Type: application/fhir+json header. The add_patient_observation tool POSTs new Observation resources with LOINC coding. Both authenticate using the SHARP token injected by Prompt Opinion. These are real FHIR write operations against the live server — not mock data and not client-side state.
For Those Evaluating AI Orchestration Architecture
The Universal Router is the architectural centerpiece. It is not a one-shot classifier that decides the path at the start and never revisits. It is called multiple times per execution — after each orchestrator completes, after each interrupt resolution, and potentially after an interrupt LLM modifies the execution plan.
The routing decision is three conditions evaluated in order: route to O_N if and only if: needs_oN is True AND oN_complete is False AND iteration < MAX_ITERATIONS (default 10)
When all three orchestrators are complete, the router sends execution to the Alert Scanner, which feeds into Synthesis, which feeds into the Document Node, which produces the final response.
The re-entrant behavior emerges from the interrupt pattern. When HI2 fires because O2 found a critical drug interaction, the system saves its state — all O1 results, all O2 results, the XML Work Order, all completion flags — to a JSON file on disk. It returns partial results plus the interrupt question to the doctor. When the doctor replies, the system loads the saved state, injects the doctor's answer, and resumes. The router sees o1_complete=True, o2_complete=True, hi2_done=True — and routes directly to O3, skipping the work already done.
But the more powerful case is the Interrupt LLM Node. When a doctor gives a complex mid-execution instruction — "also check yesterday's kidney labs" — the Interrupt LLM reads the current XML Work Order, modifies it (disables irrelevant workers, adds a time-filter instruction to the labs worker, resets o1_complete to False), and returns control to the router. The router sees o1_complete=False and routes back to O1 for a focused re-run. Only the modified workers execute. Previous results are preserved. The system re-plans mid-flight based on the doctor's evolving clinical thinking.
Two independent safety mechanisms prevent infinite loops. First, each orchestrator increments its iteration counter on entry — before any worker runs. The router checks this counter before routing. Second, the completion flag is set on exit — after all workers finish. Even if the completion flag somehow fails to set, the iteration counter will eventually reach MAX_ITERATIONS and force the router to move on. Both mechanisms would need to fail simultaneously for a loop to occur, which is architecturally impossible since they are checked at different points in the execution.
For Those Assessing Clinical Safety and Trust
The trust model has three layers that operate independently.
Layer 1 — Deterministic Clinical Math. Seven calculators in calculations.py produce guaranteed-correct results. Cockcroft-Gault eGFR, qSOFA, NEWS2, CHA2DS2-VASc, HAS-BLED, CURB-65, and BMI. These are pure Python functions with no LLM involvement. The eGFR value of 23.4 for Antonia is a mathematical certainty given her inputs — not an estimate, not a probability, not a hallucination. O2 reasoning workers call these functions first and then ask the LLM to interpret the scores. The LLM provides clinical context. The math provides the numbers. They are never mixed.
Layer 2 — Rule-Based Alert Scanner. Ten workers that run on every query, regardless of intent, regardless of what the doctor asked. Critical lab value detection uses hardcoded thresholds: creatinine above 2.0, potassium above 6.0, sodium below 120, hemoglobin below 7.0. Allergy violation checks current medications against documented allergies. Sepsis watch evaluates qSOFA criteria. These are if-then rules in Python. They cannot be influenced by prompt injection, confused by ambiguous data, or persuaded by confident-sounding reasoning from another worker. If the threshold is met, the alert fires.
Layer 3 — Human-in-the-Loop Interrupts. Two checkpoints — after O1 (data collection) and after O2 (clinical reasoning). If O2 detects a critical drug interaction, the system does not proceed to discharge planning. It pauses, presents the finding, and asks the doctor to confirm the clinical decision. The doctor's response is recorded in the XML Work Order with a timestamp — creating an auditable record that the clinician was informed, considered the finding, and made an explicit decision to proceed, modify, or halt.
These three layers are independent by design. The alert scanner does not read O2 reasoning results. It reads raw O1 data and applies its own rules. If the drug interaction worker somehow missed the oxycodone risk, the alert scanner would still fire on creatinine above 2.0. If both the O2 worker and the alert scanner somehow missed everything, the interrupt checkpoint would still pause on any finding marked critical. For a dangerous recommendation to reach the doctor without any flag, all three layers would need to fail simultaneously on the same data point — deterministic math would need to produce the wrong number, rule-based thresholds would need to not fire on an abnormal value, and the interrupt conditions would need to not trigger on a critical finding.
The system also practices epistemic honesty. When the medications worker retrieves 3 active medications for a patient with 43 conditions, the care gap worker flags the mismatch: "3 active medications for 43 conditions suggests incomplete medication data. Assessment is based on available data only — manual verification recommended." The system does not pretend to have complete information. It tells the doctor exactly what it checked, what it could not check, and why the gap exists.
The Self-Modifying Dimension
The AI Builder is not an afterthought. It changes the fundamental nature of the system.
Traditional clinical AI is static — built by engineers, frozen at deployment. If a cardiologist needs troponin trend monitoring, that is a feature request. It enters a product backlog, gets prioritized against other requests, is built by an engineering team, tested, reviewed, and deployed weeks or months later.
MedicsHelper inverts this. The cardiologist types: "Build a worker called troponin_monitor that tracks troponin-I trends and flags if rising above 0.04. Put in o2. Admin credentials." Eight seconds later, the worker exists — generated from a typed template, scanned for unsafe operations, import-tested, registered, and loaded by the O2 orchestrator on the next clinical query.
The safety model for generated code has four layers. Admin authentication prevents unauthorized creation. Code scanning rejects any generated code containing subprocess, exec, eval, open, or shutil before the file is written. Import verification dynamically loads the generated module and checks for a valid run() function — if the import fails, the file is deleted and the registry is not updated. Auto-generated fallback functions ensure that even if a custom worker passes all checks but fails at runtime with real patient data, the orchestrator catches the exception and uses the fallback, returning a safe default result while the other workers continue normally.
This means a hospital does not need our engineering team to extend the system. A pediatric ICU adds weight-based dosing workers. A cardiology department adds cardiac risk stratification. A pharmacy adds formulary compliance checking. Each extends the same pipeline, reads the same FHIR data, writes results in the same format, and is caught by the same safety nets. The platform scales to specialty needs without scaling the engineering team.
What We Learned
Hierarchical agents outperform flat agents on complex tasks. A single LLM asked "is it safe to discharge this patient?" will miss things. Twelve specialized workers each focused on one clinical dimension, running in parallel, catches far more — and each result is traceable.
The blackboard pattern solves the coordination problem. Shared XML state that every node reads and writes to, with no direct node-to-node communication, made the system debuggable, extensible, and auditable in ways that a pure LangGraph state dict wouldn't have.
Deterministic math should never be delegated to LLMs in clinical contexts. This seems obvious in retrospect but required active discipline. Every time an O2 worker needed a calculated value, the reflex was to ask the LLM. The correct answer was always to call calculations.py.
Graceful degradation is a first-class design requirement. A clinical system that crashes on an LLM timeout is dangerous. Every failure mode had to be designed for explicitly, not handled reactively.
Prompt Opinion's SHARP context injection is genuinely powerful. Having the FHIR URL, access token, and patient ID injected automatically into every MCP call — without any manual plumbing — made the integration feel like a native capability rather than a bolted-on connector.
What's Next for MedicsHelper
Real hospital FHIR integration. The architecture already reads CapabilityStatement from /metadata and auto-discovers resource types, search parameters, and supported operations. It has been tested against HAPI FHIR public server (146 resource types, $everything confirmed) and handles servers that return 422 on /metadata via a 57-resource fallback capability set. The next step is a pilot against a production R4-compliant server — Epic, Cerner, Azure Health Data Services, or AWS HealthLake. No code changes required. Point it at the server, CapabilityStatement does the rest.
Standards-aligned interoperability. SHARP context injection (X-FHIR-Server-URL, X-FHIR-Access-Token, X-Patient-ID) is already the integration model — the same pattern that SMART on FHIR established for EHR-launched apps. The MCP layer is the natural next transport for this context, allowing any agent on any platform to access a patient's full clinical context without manual configuration per query. MedicsHelper is designed to be the reasoning layer on top of whatever FHIR server a hospital already has.
ICU and critical care expansion. The deterministic calculator layer currently covers qSOFA, NEWS2, CURB-65, and eGFR. The next additions are SOFA score (multi-organ dysfunction), APACHE II (ICU severity), and a hypotension prediction score for patients requiring emergent intubation. The alert scanner already runs rule-based sepsis indicators on every query — expanding this to ventilator management, vasopressor titration thresholds, and fluid balance monitoring is a worker addition, not an architectural change.
Pediatric clinical depth. The Cockcroft-Gault eGFR formula is adult-validated. The Schwartz formula is the correct pediatric alternative and is the next planned calculator addition. The dosage worker already flags adult-dose medications when the patient is under 18. Expanding this to weight-for-age z-scores, Broselow tape weight estimation, and age-adjusted vital sign reference ranges would make MedicsHelper suitable for pediatric wards without changing the pipeline architecture — only the calculator layer and the relevant O2 worker prompts.
Agentic EHR workflow integration. The human interrupt pattern — where the system pauses mid-pipeline and asks the clinician to confirm before proceeding — is the same pattern that modern agentic EHR tools are converging on: AI handles the task, human stays in the loop at critical decision points. The next step is CDS Hooks integration — triggering the MedicsHelper pipeline automatically when a clinician opens a patient chart, orders a medication, or initiates a discharge — without requiring the clinician to type a query at all.
Women's health and population health modules. The population query architecture (cross_patient_search, cohort_analyzer, batch_discharge_planner) already supports ward-level analysis. Extending this to maternal risk scoring (ACOG guidelines, preeclampsia risk, gestational diabetes screening), preventive care gap detection, and chronic disease management across patient populations requires adding domain-specific O2 workers and calculators — the pipeline handles the rest.
Longitudinal patient intelligence. Right now each query is stateless across sessions. Adding a persistent patient timeline — tracking how risk scores change across visits, flagging silent deterioration patterns across days rather than within a single query — would transform MedicsHelper from a point-in-time decision tool into a continuous clinical intelligence layer. The session persistence infrastructure is already built. The extension is a vector store indexed by patient ID storing summarized assessment history.
Clinical validation. The most important next step is a structured evaluation against real clinical decisions — comparing MedicsHelper's recommendations to what a senior clinician would have caught in the same scenario. That is what turns a hackathon prototype into a tool that belongs in a hospital.
⚠️ How to Use MedicsHelper (Important for Judges)
To experience MedicsHelper correctly, please use it inside Prompt Opinion BYO Agent.
MedicsHelper is NOT a normal chatbot — it runs a full Hierarchical Agentic pipeline through MCP tools. If configured incorrectly, it will fall back to default tools and the system will NOT behave as intended.
Required Setup:
Go to BYO Agents → Add MedicsHelper
Open Edit → Tools tab → Enable: "Disable Community MCP Server"
Use the official prompts from the repository: Visit the GitHub repo and navigate to:
/byo-prompts/
- system_prompt.txt
- consultation_prompt.txt
Use these prompts exactly in:
- System Prompt
- Consultation Prompt
These prompts are required to activate the full MCP pipeline (all 18 tools).
⚠️ Important:
run_clinical_assessmentis not a simple tool — it is the entry point to the full HAA system- It orchestrates all 69 nodes across data, reasoning, safety, and workflow layers
- Without the correct prompts, this orchestration will NOT trigger
⚠️ Without proper setup:
- MCP tools will not be used
- Clinical pipeline will not execute
- Safety checks and drug interaction analysis will be skipped
- Output will degrade to a basic LLM response
Full Setup & Source Code:
https://github.com/off-rkv/MedicsHelper---Hierarchical-Agentic-AI-for-Clinical-Decision-Support
We strongly recommend using the repo prompts to see the system’s full capability.


Log in or sign up for Devpost to join the conversation.